


机构一致看好股市行情,2021年谁是最强风口?布局窗口期来临,立即开户,抢占投资先机!
原标题:Netflix 如何用“GraphQL Federation”扩展 API (第1部分) 来源:36氪
神译局是36氪旗下编译团队,关注科技、商业、职场、生活等领域,重点介绍国外的新技术、新观点、新风向。
编者按:微服务因为开发维护容易、启动较快、技术栈不受限以及可按需伸缩等特点已经成为架构设计的主流,Netflix也不例外。其微服务架构就以松耦合、高可扩闻名。而且他们还通过提供统一的API聚合层,屏蔽了UI开发者可能遇到的跨域复杂性。不过,随着开发者数量的增加以及域复杂性的增加,这种聚合层的开发已经变得越来越困难。为了解决这个难题,他们搭建了一个联邦GraphQL平台来驱动这个聚合层。本文就是他们的实践介绍。原文发表在其官方博客上,标题是:How Netflix Scales its API with GraphQL Federation (Part 1)

划重点:
如果不想看这么多,就看文末的API架构演进图
Netflix的微服务架构的松耦合、高度可扩展是出了名的。服务相互独立可以让各自用不同的节奏去演进并独立地扩展。但是,这给跨多个服务的用例增加了复杂性。但Netflix并不是向UI开发者提供成百上千的微服务,而是在边缘提供统一的API聚合层。
UI开发人员喜欢这种针对很大的同一个域采用概念性API的简洁性。后端开发人员喜欢API层提供的去耦合以及弹性。但是随着业务规模的扩大,我们快速创新的能力已逼近了那条无形的渐近线。随着开发人员数量的增加以及域复杂性的增加,开发API的聚合层变得越来越困难。
为了解决这个日益严重的问题,我们开发了一个联邦GraphQL平台来驱动API层。这解决了在一致性和开发速度方面的遇到的很多挑战,并且在可伸缩性和可操作性等维度上的牺牲也最小。我们已经在Netflix的工作室生态体系成功部署了这种方案,并且正在探索可以适用于其他领域的模式和改造。在此我们愿意分享自己的故事,希望能给大家提供启发,并且鼓励就其在别处的适用性进行对话。
案例研究:Studio Edge
Studio Ecosystem简介
Netflix正在用更快的速度来制作原创内容。从电视节目或电影进行宣传开始,到真正在Netflix上映之时,在背后其实发生了很多事情。这包括但不仅限于招募人员、选角、签订交易、合同谈判、制作、后期制作、视觉效果和动画、字幕以及配音等等。为了支撑这些工作流,Studio Engineering正在开发成百上千的应用和工具。

NetflixStudio的内容生命周期
Studio API
回想起几年前,工作室这块的痛苦之一是数据及其关系的复杂性的不断提高。上面描述的工作流互相之间的联系是固有的,但是数据及其互相关系则完全不同,而且存在于无数的微服务之中。产品团队用两种架构模式来解决这个问题。
1)单用途聚合层(Single-use aggregation layers)—因为松耦合的关系,我们观察到很多团队花费了大量精力来构建可重复的数据获取代码和聚合层,以支持其产品需求。这一块要么是UI团队通过BFF(面向前端的后端)来完成的,要么就是由后端团队通过中间层服务提供的。
2)来自其他团队的数据的物化视图(Materialized views)——部分团队采用了一种构建其他服务数据的物化视图的模式来满足其特定的系统需求。物化视图具有性能的优势,但数据一致性存在不同程度的落后。这对于Studio里面最重要的工作流来说是不可接受的。跨Studio应用的数据不一致是2018年Studio Engineering遇到的主要支持问题。
Graph API:为了更好地满足潜在需求,我们的团队开始开发一个自己策划的Graph API,叫做“Studio API”。它的目标是在数据和关系之上提供统一的抽象。Studio API采用GraphQL作为其底层的API技术,并为访问核心共享数据提供了重要手段。Studio API的使用者可以浏览图谱,并可以更快地开发新功能。由于GraphQL中的每个字段都解析为一条数据提取代码,因此,我们还观察到了不同UI应用之间数据不一致的情况变少了。

StudioAPI Graph
 StudioAPI架构图
StudioAPI架构图Studio API的瓶颈
Studio API暴露的One Graph取得了巨大的成功;产品团队喜欢它的可重用性和轻松、一致的数据访问。但是,随着API使用者数量的增加以及该图数据量的增加,出现了新的瓶颈。
首先,Studio API团队跟领域知识与产品需求脱节,这对架构的运行状况产生了负面影响。其次,将后端的新元素链接到该graph API的操作是手动完成的,这跟微服务价格哦偶所承诺的快速演进显然背道而驰。最后,对于一个不断扩大的团队来说,一个小团队很难应对日益增加的运营和支持负担。
我们知道必须要有一个更好的办法——统一但去耦合,要有策划但行动快速。
回到核心原则
为了解决这些瓶颈,我们借鉴了自己丰富的微服务历史,将一体式的应用打破。我们仍然希望保留Studio API统一的GraphQL模式,但把解析器的实现下放给各自领域的团队。
2019年初,当我们在一起讨论新架构时,正好Apollo发布了GraphQL联邦规范(GraphQL Federation Specification)。规范保证了既有统一模式又有分布式所有权的好处。我们对该规范跑了一个测试实现,并取得了可喜的结果,然后开始跟Apollo一起就GraphQL Federation的未来开展合作。在我们的下一代架构“Studio Edge”里面,联邦就是其中的关键要素。
GraphQL Federation入门
GraphQL Federation的目标有两个:为消费者提供一个统一的API,同时还为后端开发人员提供灵活性和服务隔离。为此,需要创建模式并加以注释,说明所有权的分配方式。我们不妨看看一个包含有三个核心实体的例子:
Movie:在Netflix这里,我们要制作title(节目的、电影的、短片的等)。为简单起见,我们假设每个title都是一个Movie对象。
Production:每部电影都跟一个Studio Production关联。Production对象会跟踪制作电影所需的所有内容,包括拍摄地点,供应商等。
Talent:做Movie的人就是Talent,包括演员,导演等。
这三个域由三个独立的工程团队拥有,分别要负责各自的数据源、业务逻辑以及相应的微服务。在一个非联邦的实现中,我们会有这样一个简繁的Schema和Resolvers,都是由Studio API团队所拥有并实现的。GraphQL Framework会接受客户端的查询,以广度优先遍历来协调对解析器的调用。

StudioAPI的Schemas & Resolvers
为了过渡到联邦架构,我们需要在不牺牲统一schema的情况下将这些resolver的所有权转移到它们各自的域中。为此,我们需要跨GraphQL服务边界来扩展Movie类型:

movie类型联邦化
这种跨GraphQL服务边界来扩展Movie类型的能力让Movie成为了联邦类型。解析给定字段需要网关层向下委托给相应的域服务。
Studio Edge架构
通过利用对类型进行联邦的能力,我们设想了下面的架构:
 StudioEdge架构图
StudioEdge架构图关键架构组件
Domain Graph Service(DGS)是符合规范的独立GraphQL服务。开发人员在DGS里面定义自己的联邦GraphQL schema。DGS由负责该API一小部分的领域团队拥有和运营。DGS开发者可以自由决定是否要把自己现有的微服务转换为DGS,或者启动全新的服务。
Schema Registry是一个有状态的组件,里面存储了每一个DGS的所有schema以及schema变更。它会公开schema的CRUD API,供开发者工具和CI / CD管道使用。它还要负责schema(含独立DGS schema以及组合schema)的验证。最后,这个注册表还会将统一schema组合到一起,并将其提供给网关。
GraphQL Gateway主要负责响应使用者的GraphQL查询。它从客户端获取查询,将其分解为较小的子查询(查询计划),然后通过将调用交给适当的下游DGS代理处理来执行该计划。
实现细节
GraphQL Federation有3个主要的业务逻辑组件。
Schema Composition(模式组合)
Composition是指把所有的联邦DGS schema合为一个统一schema这个阶段。Gateway会将组合好的schema公开给该graph的使用者。

SchemaComposition阶段
每当DGS推送一个新的schema时,Schema Registry都会进行以下验证:
新的schema是有效的GraphQL schema
新的schema跟其他的DGS schema可以无缝组合,从而创建出有效的组合schema
新的schema具备向后兼容
如果满足上述所有条件,则将该schema注册进Schema Registry。
查询规划与执行
联邦配置由所有独立的DGS schema和组合schema组成。Gateway利用联邦配置和客户查询来生成查询规划。查询规划将客户查询分解为较小的子查询,然后将其发送给下游的DGS执行,里面还明确了执行顺序,包括哪些需要顺序执行那些需要并行执行。

查询规划输入
让我们根据上面提到的schema构建一个简单的查询,然后看看查询规划是什么样的。
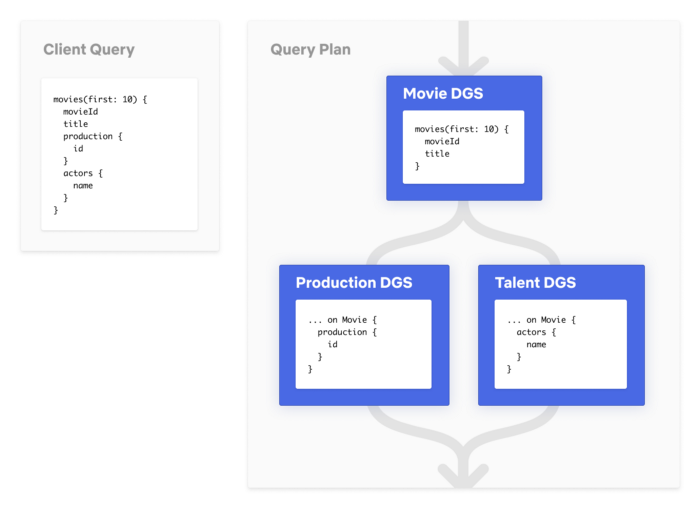
一个简化的查询规划
对于该查询,网关会根据联邦配置了解到哪个字段归哪个DGS拥有。通过这一信息,它会把客户查询拆分为对三个DGS的三个独立查询。由于根字段movies归Movie DGS所有,所以第一个查询会发送到Movie DGS。其结果是会检索数据集前10部电影的movieId和title字段。然后,Gateway再用从上一个请求获得的movieIds ,执行对Production DGS和Talent DGS发起的两个并行请求,从而获取那10部电影的production和actor字段。完成后,子查询响应会被合并到一起,并将合并的数据响应返回给调用方。
关于性能的一点说明:在最坏的情况下,查询规划和执行会增加〜10ms的开销。这包括用于创建查询规划的计算,以及对DGS响应的反序列化以及对合并的网关响应的序列化。
Entity Resolver(实体解析器)
现在你可能在想,Production和Talent DGS的并行子查询是怎么个并行法的?DGS可不支持这种功能。这是我们的难题的最后一部分。
我们再回顾一下我们的联邦类型Movie。为了让网关能够跨DGS将Movie无缝地加入进去,定义和扩展Movie的所有DGS需要就一到多个定义主键的字段(比方说movieId )达成一致。为了完成这项工作,Apollo在联邦规范中引入了@key指令。其次,DGS必须为通用的查询字段_entities实现一个解析器。_entities查询会返回该DGS里面所有的联邦类型的一个联合类型。网关用_entities查询来依靠movieId去查找Movie 。
让我们看一下查询规划是什么样的

详细的联邦查询规划
表示的对象含有一个movieId,而后者则是根据对Movie DGS的第一个请求的响应生成的。由于我们要求的是前10部电影,因此我们会有10个表示对象发送给Production和Talent DGS。
这跟Relay’s Object Identification有点类似,但有一些区别。_Entity是联合类型,而Relay’Node是个接口。此外,在用@key的时候,是支持可变key名和类型以及组合键(composite key)的,而在Relay里面,id是一个不透明的ID字段。
把这些组合在一起,便构成了联邦API体系结构核心的要素。
总结
我们的Studio Ecosystem架构已经历了不同的阶段,每一个阶段都是因为这些想法的推动:减少从构思到实现的时间,改善开发人员的体验,简化操作。架构阶段大概是这样的:

API架构的演变:从n:1到n:m到n:1:m再到n:1:k:m
敬请关注
在过去一年的时间里,我们已经在Studio Edge里面实现了联邦API架构组件。到达这一步需要快速迭代,大量的跨职能协作,经历若干次的转型(pivot),以及持续的投资。我们跟70个DGS以及数百位采用Studio Edge架构并为之做出贡献的开发者一道努力。在我们的下一片Netflix Tech Blog文章里面,我们会分享在此过程中学到的知识,包括构建整体解决方案所必需的横切关注点方面的认知。
我们要感谢整个GraphQL开源社区的慷慨贡献,以及为GraphQL的未来所铺平的道路。如果你想参与解决像Netflix这种规模的复杂而有趣的问题的话,不妨看看我们的招聘页面,或直接与我们联系。
译者:boxi。





APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




