


原标题:清华大学发布全球最大的公开人脸数据集 含数百万ID和数亿图片 来源:搜狐科技
近年来,经过业界多年来在数据集构建、神经网络架构、损失函数设计等方面的详尽研究,人脸识别技术在识别精度上已经取得了长足进步,并实现了大规模落地。但当前人脸识别仍然面临公开数据规模小、标准混杂、测评无法对齐等问题。
其中,目前公开的人脸识别训练数据集中,规模最大的是MegaFace2和MS1M,分别仅拥有67.2万ID和470万图片,以及10万 ID和1000万图片,远远无法满足实际人脸识别系统的数据需求。可以说,公开数据规模与实际落地系统所需数据规模之间的巨大差距,已经较大程度上阻碍了当前人脸识别相关技术的持续发展。
另一方面,评测准则和测试集也是影响人脸识别技术进一步发展的重要制约因素。目前公开的人脸识别评测集在精度上基本已经比较饱和。同时这些测试集对于人脸识别不同场景下的分类测评不够细致,没有持续迭代、升级和维护,也没有根据实际应用限制搭建评测准则。
业界公认,NIST-FRVT是目前唯一符合现实应用的测评系统。然而,由于NIST-FRVT对提交频率和提交条件的严格要求,一定程度上也限制了人脸识别技术的发展。
基于当前行业的现状,芯翌科技与清华大学的研究人员在FRVT参赛基础上,完全基于全球互联网公开人脸数据,联合推出了当前全球规模最大的人脸数据集WebFace260M,人脸ID数目首次达到数百万,图片数目首次达到数亿规模,将很大程度上推动以深度学习为基础的人脸识别相关技术发展。
 WebFace260M数据集和公开数据集在人脸ID和数量上的比较
WebFace260M数据集和公开数据集在人脸ID和数量上的比较同时在WebFace260M的基础上,芯翌科技和清华大学的研究人员采用自训练全自动迭代的清洗流程 (Cleaning Automatically by Self-Training, CAST),得到WebFace42M,是目前全球规模最大的可直接用于训练的干净人脸数据集。该数据集包含200万ID和4200万图片,ID数目和图片数目相比目前使用最广泛、最受认可的公开数据集MS1MV2都提高了一个数量级以上。
针对目前人脸识别的评测问题,研究人员发布了更贴近实际应用的“时间受限人脸识别评测准则”-FRUITS (Face Recognition Under Inference Time conStraint)和分布更广泛、更具挑战性、分类更细致的人脸测试集,这将推动人脸识别评测更靠近真实场景。同时,研究人员将持续维护、迭代和升级该测试集以及评测系统,助力行业技术发展。
基于WebFace260M清洗得到的WebFace42M数据,能够在目前公开的、最具挑战性的IJBC测试集上,达到新的SOTA (State-Of-The-Art),并把相对错误率降低了40%。
 基于WebFace42M,在IJBC测试集上取得了SOTA的性能
基于WebFace42M,在IJBC测试集上取得了SOTA的性能同时,仅基于WebFace42M的数据,芯翌科技在2020年10月NIST-FRVT的榜单上,取得了1:1人脸识别评测综合排名世界前三的成绩。
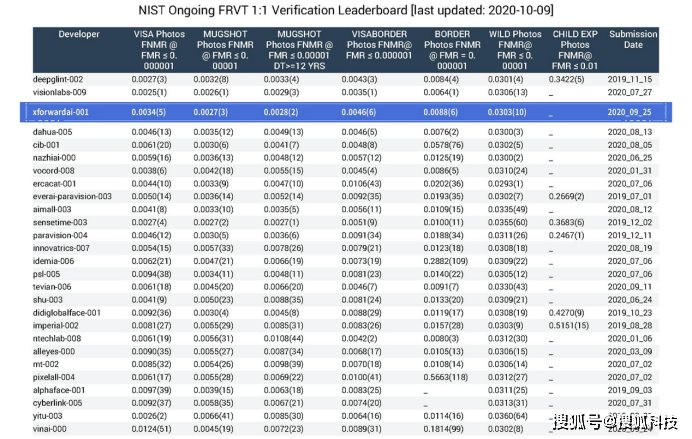
更进一步,以WebFace42M为基础,在2021年3月最新一期的NIST-FRVT榜单上,芯翌科技在戴口罩人脸识别评测中以绝对优势获得世界第一,并在1:1人脸识别评测综合排名世界前三。
然而目前,国内外普遍对数据资源这一重要的生产资料重视程度不够,行业规范不足,分享壁垒严重,缺乏长期规划。生产资料的匮乏,严重影响和制约了数字经济和智能化时代生产力的释放,限制了行业的发展。
芯翌科技和清华大学的研究人员合作推出了目前全球最大的公开人脸数据集——WebFace260M以及相应的Benchmark。通过这个数据集,希望能够助力AI时代科技创新,持续推动智能化产业落地。
出品|搜狐科技
编辑|陈凯烨




APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)







