


十三 鱼羊 发自 凹非寺
量子位 报道 | 公众号 QbitAI
看到这张恐龙化石的动态图片,你肯定会认为是用视频截出来的吧?

然而真相却是——完全由静态图片生成!
没错,而且还是不用3D建模的那种。
这就是来自伯克利大学和谷歌的最新研究:NeRF,只需要输入少量静态图片,就能做到多视角的逼真3D效果。

还需要专门说明的是,这项研究的代码和数据,也都已经开源。
你有想法,尽情一试~
静态图片,合成逼真3D效果我们先来看下NeRF,在合成数据集(synthetic dataset)上的效果。

可以看到,这些生成的对象,无论旋转到哪个角度,光照、阴影甚至物体表面上的细节,都十分逼真。
就仿佛是拿了一台录影设备,绕着物体一周录了视频一样。
正所谓没有对比就没有伤害,下面便是NeRF分别与SRN、LLFF和Neural Volumes三个方法的效果比较。

不难看出,作为对比的三种方法,或多或少的在不同角度出现了模糊的情况。
而NeRF可谓是做到了360度无死角高清效果。
接下来是NeRF的视点相关 (View-Dependent)结果。
通过固定摄像机的视点,改变被查询的观看方向,将视点相关的外观编码在NeRF表示中可视化。


NeRF还能够在复杂的遮挡下,展现场景中详细的几何体。


还可以在现实场景中,插入虚拟对象,并且无论是“近大远小”,还是遮挡效果,都比较逼真。

当然,360度捕捉真实场景也不在话下。

这样出色的效果,是如何实现的呢?
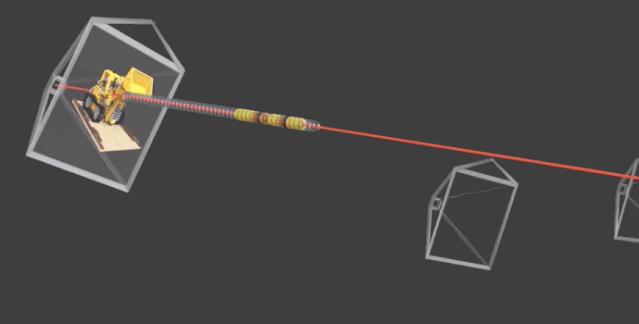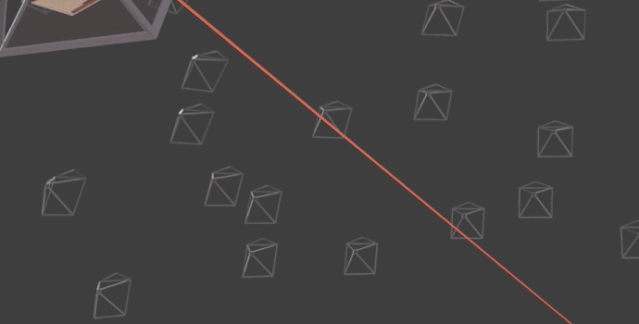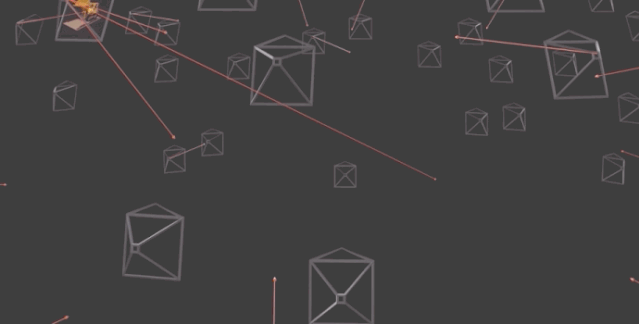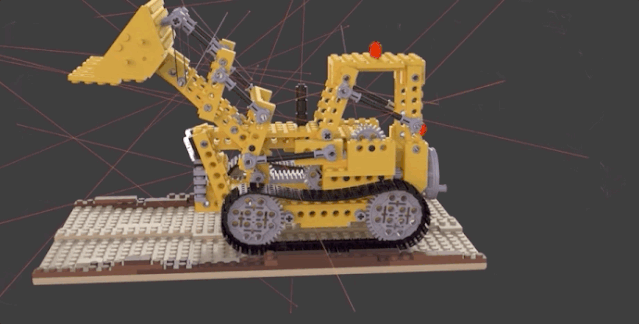
首先,是将场景的体积表示优化为向量函数,该函数由位置和视图方向组成的连续5D坐标定义。具体而言,是沿相机射线采样5D坐标,来合成图像。
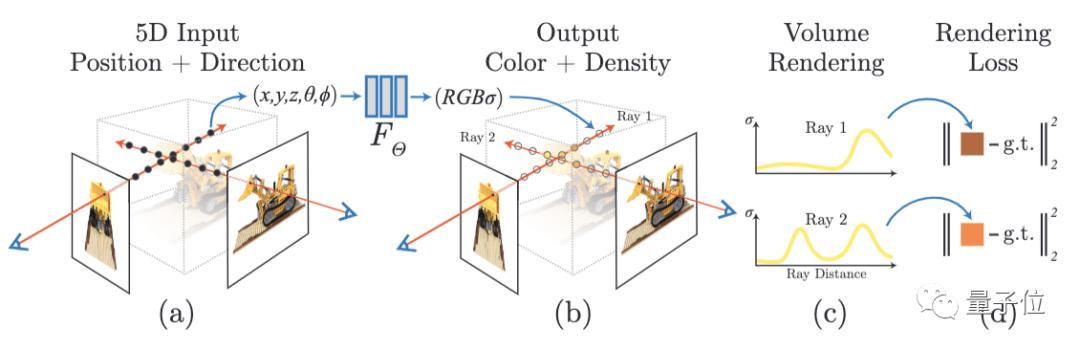
而后,将这样的场景表示参数化为一个完全连接深度网络(MLP),该网络将通过5D坐标信息,输出对应的颜色和体积密度值。
通过体积渲染技术将这些值合成为RGB图像。
渲染函数是可微分的,所以可以通过最小化合成图像和真实图像之间的残差,优化场景表示。
需要进一步说明的是,MLP使用8个完全连接层(ReLU激活,每层256个通道)处理输入,输出σ和256维特征向量。然后,将此特征向量与摄像机视角连接起来,传递到4个附加的全连接层(ReLU激活,每层128个通道),以输出视点相关的RGB颜色。
NeRF输出的RGB颜色也是空间位置x和视图方向d的5D函数。

这样做的好处可以通过对比来体现。可以看到,如果去掉视点相关,模型将无法重现镜面反射;如果去掉位置编码,就会极大降低模型对高频几何形状纹理的表现能力,导致渲染出的外观过于平滑。
另外,针对高分辨率的复杂场景,研究人员还进行了两方面的改进。
其一,是输入坐标的位置编码,可以帮助MLP表示高频函数。
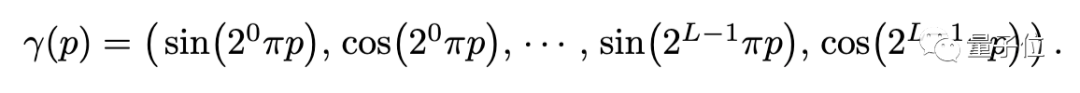
其二,是分层采样。用以更高效地采样高频表示。
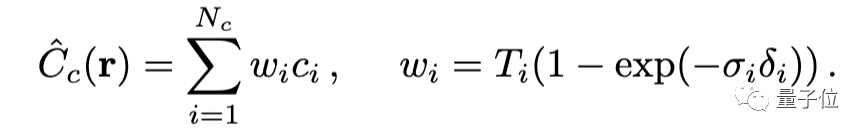
目前,NeRF项目的代码已经在GitHub上开源。
代码主要基于Python 3,还需要准备的一些库和框架包括:TensorFlow 1.15、matplotlib、numpy、imageio、configargparse。
优化一个NeRF研究人员表示,优化NeRF只需要一个GPU就可以完成,时间方面,需要花费几个小时到一两天(取决于分辨率)。
而从优化的NeRF渲染图像,大约只需要1~30秒时间。
运行如下代码可以获取生成Lego数据集和LLFF Fern数据集:
bash download_example_data.sh
若想优化一个低解析度的Fern NeRF:
python run_nerf.py --config config_fern.txt
在经过200次迭代之后,就可以得到如下效果:

若想优化一个低解析度的Lego NeRF:
python run_nerf.py --config config_lego.txt
在经过200次迭代之后,就可以得到如下效果:

运行如下代码,为Fern数据集获取经过预训练的高分辨率NeRF。
bash download_example_weights.sh
渲染代码,在 render_demo.ipynb 中。
另外,你还可以将NeRF转换为网格,像这样:

具体示例,可以在 extract_mesh.ipynb 中找到。还需要准备PyMCubes、trimesh和pyrender包。
关于作者:三位青年才俊这篇论文的研究团队,来自加州大学伯克利分校、谷歌研究院和加州大学圣地亚哥分校。
共同一作有三位。
Ben Mildenhall,本科毕业于斯坦福大学,目前在伯克利电气工程与计算机科学系(EECS)助理教授吴义仁(Ren Ng)门下读博。致力于计算机视觉和图形学研究。

Pratul P. Srinivasan,同样为伯克利EECS在读博士,师从吴义仁和Ravi Ramamoorthi。

Matthew Tancik,前面两位作者的同门,本硕毕业于MIT。除了专注于计算机成像和计算机视觉研究外,他还是一位摄影爱好者。

1个GPU就能完成优化,优化后渲染又只需要1-30秒,如此方便又效率的项目,还不快来试试?
One More Thing最后,还想介绍个这方面有意思的研究。
NeRF确实强,但在输入上还需要多张照片……
那么有没有方法,一张图片就能玩3D效果呢?
问就有。
之前,Adobe的实习生就提出了一个智能景深算法,单张2D图片秒变3D。
让我们感受下效果。

也是很有大片既视感了。
而最近,同样是单张2D图片变3D,台湾清华大学的研究人员,在老照片上玩出了新花样,论文入选CVPR 2020。
你看看女神奥黛丽·赫本,看看毕加索,看看马克吐温:

感觉以后看照片——摇一摇更有感觉啊。
再来看看“登月”、“宇航员和民众握手”照片裸眼3D效果:

颇有点身临其境之感。
与此前介绍过的Adobe的算法(后台加链接)类似,这一3D图像分层深度修复技术的核心算法,同样有关上下文感知修复:
初始化并切割分层深度图像(LDI),使其形成前景轮廓和背景轮廓,然后,仅针对边缘的背景像素进行修补。从边缘“已知”侧提取局部上下文区域,并在“未知”侧生成合成区域(如下图c所示)。
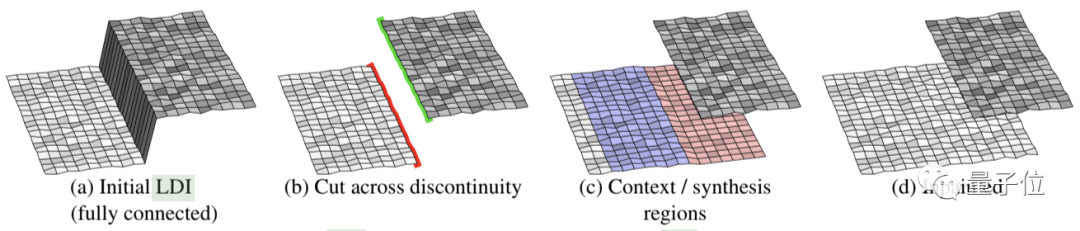
说起来,对于个人视频制作者、游戏开发人员,以及缺乏3D建模经验的动画公司来说,这类技术的成熟,可谓“福音”。
通过AI技术,让3D效果的实现进一步简化,这也是Facebook、Adobe及微软等公司纷纷投入这方面研究的原因所在。
最后,这个项目的代码也开源了……
稿子还没写完,我就准备好一系列“雪藏”已久的照片要试试了。
这也是最近看到最酷的3D图片方面的突破了。


热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




