伯克利发布的“大世界模型”,究竟大在哪里?
作者丨赖文昕
自3天前Sora发布以来,由图灵奖得主、Meta首席科学家Yann LeCun提出的“世界模型”又一次引起了广泛关注。
“世界模型”作为Sora的一大核心亮点,被OpenAI写在技术报告中。但Sora是否真的如Open AI所说,是一个世界模型,却引起了行业内的争论。
在Yann LeCun的愿景中,世界模型是一个能够学习世界如何运作的内在规律的内部模型,可以更快速地学习,为完成复杂任务做出计划,并且随时应对不熟悉的新情况,所以它很有可能克服目前限制最先进的AI系统发展的难关。
而在这场争论持续之际, UC Berkeley(加州大学伯克利分校)发布了一项名为“Large World Model(LWM)”的最新研究成果,今日已成功登上GitHub榜首。
值得一提的是,两位华人学者Hao Liu和Wilson Yan为共同一作,指导老师是吴恩达开门大弟子、伯克利人工智能实验室主任Pieter Abbeel与计算机副教授Matei Zaharia。两位教授的谷歌学术引用次数均十分耀眼,分别高达13.8万次与7.4万次。
 论文链接:https://arxiv.org/pdf/2402.08268.pdf
论文链接:https://arxiv.org/pdf/2402.08268.pdf为了应对由于内存限制、计算复杂性和数据集有等重大挑战,这个团队构建了一个由不同视频和书籍组成的大型数据集,以Hao Liu先前提出的RingAttention技术为基础,对长序列进行可伸缩训练,并将上下文大小从4K逐渐增加到100万tokens,一次可以分析1小时长度的视频。
1
100万token,1小时长视频
它还开源
大模型的发展进程快得令人惊叹,但是仍存在不少技术痛点。比如,目前的语言模型无法理解世界上某些难以用语言描述的问题,且难以处理复杂冗长的任务。
针对这个难题,该团队提出了“Large World Model(LWM)”,因为视频序列能提供语言和静态图像中没有的、有价值的时间信息,这使得它们对于语言的联合建模具有特别作用。这样的模型可以更好地理解人类文本知识和物理世界,从而实现更广泛的人工智能能力来帮助人类。
这个“大世界模型”是否确如其名呢?
在研究报告的开篇,团队便自信展示了LWM与GPT-4V、Gemini Pro Vision与Video-LLaVA的对比结果:将长达1小时的油管视频输入并根据视频内容细节提问后,只有LWM能提供准确的答复。

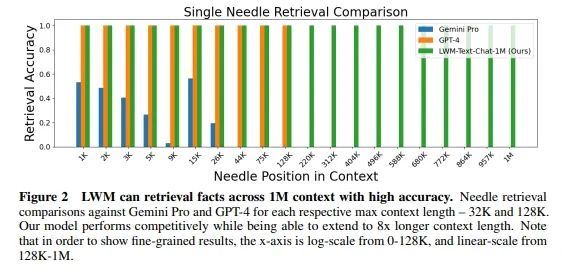
而除了能读懂理解长视频外,LWM在超长文本任务的表现同样亮眼。LWM 可以高精度地检索 1M 上下文中的事实。针对Gemini Pro 和 GPT-4各自的最大上下文长度(32K 和 128K)进行单针检索比较时,LWM在各个指标上的表现均大幅领先。
团队对LWM的研究成果作出了以下总结:
该研究在长视频和语言序列上训练了一个拥有极大上下文尺寸的 transformers 模型,从而设立了新的检索任务和长视频理解方面的标杆。
为了克服视觉 - 语言训练带来的挑战,该研究采取了以下措施,包括使用掩码序列以混合不同长度的序列、损失加权以平衡语言和视觉、以及使用模型生成的问答数据来处理长序列对话。
通过 RingAttention、掩码序列打包等方法,可以训练数百万长度的多模态序列。
完全开源 7B 参数系列模型,其能够处理超过 100 万 token 的长文本文档(LWM-Text、LWM-Text-Chat)和视频(LWM、LWM-Chat)。
2
分阶段的渐进式训练
模型能力逐步升级
是什么训练方法让LWM具备如此亮眼的能力呢?
LWM的训练步骤主要分为两个阶段:第一阶段是学习长上下文语言模型(Learning Long-Context Language Models),第二阶段是学习长上下文视觉-语言模型(Learning Long-Context Vision-Language Models)。
第一阶段时,团队将研究重点分为了上下文扩展、训练步骤、聊天微调和语言结果评估四个部分。
在上下文扩展中,他们使用RingAttention技术,通过分块计算和序列并行,理论上可以扩展到无限上下文,仅受限于可用设备数量。
RingAttention作为一个环形结构来组织blocks,这样每个block只需要与其相邻的block进行通信、交换信息,此结构能够大大减少通信开销。
分块计算则是将长序列分割成多个较小的blocks,每个block包含固定数量的tokens。这样,模型只需要计算每个block内的注意力权重,而不是整个序列。
在训练过程中,序列并行的方法可以并行处理多个block,每个block由不同的GPU处理,使模型能在多个设备上同时处理序列的不同部分,从而提高了训练效率。
同时,由于RingAttention 支持渐进式训练,让模型可以从处理较短的序列开始,然后逐步增加序列长度。于是团队就采用了渐进式训练方法,从32K tokens开始,逐步增加到1M tokens,以有效扩展上下文大小。这意味着此方法有助于模型逐步学习处理更长序列的能力,同时保持训练效率。
到了训练步骤的部分,团队会初始化模型参数,然后逐步增加上下文长度,分为32K、128K、256K、512K和1M tokens共5个阶段,且在每个阶段,会使用不同版本的Books3数据集进行训练,这些数据集经过过滤,以适应当前的上下文长度。
针对聊天微调,团队构建了模型生成的问答数据集,通过将文档分割成固定大小的block,然后使用短上下文语言模型生成问题和答案对。而在长上下文长度(如32K tokens)下,则是通过连接相邻的block和在序列末尾添加相关的问答对来构建单个32K tokens的示例。
在第一阶段的最后,团队对于LWM的语言能力进行了单针检索、多针检索、多文本评估和聊天评估。
值得一提的是,此研究还对比了具有 4K 上下文的 Llama2-7B 模型与LWM-Text(从 32K 到 1M)的语言能力。评估涵盖了各种语言任务,证明扩大上下文大小不会影响短上下文任务的性能。结果表明,LWM在32K 到 1M长度下各任务中表现得同样好,甚至更好。
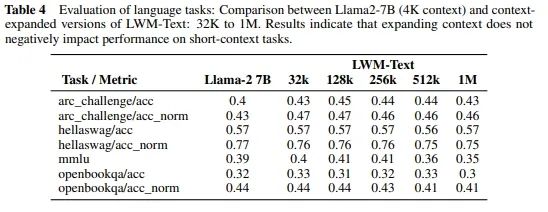
这一证据表明上下文扩展不存在负面影响,突显了模型适应不同任务要求而不会在较短上下文中损失效率的能力。
在完成语言模型的训练后,团队开启了他们的第二阶段——学习长上下文视觉-语言模型。在此阶段中,团队也将研究工作分为三个板块,即视觉架构修改、训练步骤和评估结果。
对于视觉架构修改,他们使用了预训练的VQGAN将图像和视频帧转换为离散tokens,并且引入新的tokens来区分文本生成的结束和视觉生成的开始,以及视频帧的结束。
而在训练步骤中,团队从LWM-Text-1M文本模型开始初始化,然后在大量结合文本-图像和文本-视频数据上进行渐进式训练。他们分别在1K、8K、32K、128K和1M tokens的序列长度上进行训练,同样地,每个阶段都是从先前的较短序列长度阶段初始化。
在最终的评估结果上,团队在长视频理解、图像理解和短视频理解等任务上评估了LWM的模型性能并展示了其在处理长视频和图像生成方面的优秀能力。
3
结语
Sora在2024年拉响了大模型比拼的第一枪,使得文生视频技术跃为时下焦点,也让“世界模型”变得似乎不再遥不可及。
在应对长文本、视频甚至是多模态技术时,世界模型对物理世界规律的理解与应用,或将成为各家大模型选手能否在角逐中取胜的关键。
AI 科技评论将继续关注世界模型研究动态,欢迎添加anna042023,交流认知,互通有无。

















热门推荐
日本警告:有特大地震风险,或致近30万人死亡 收起日本警告:有特大地震风险,或致近30万人死亡
- 2025年03月31日
- 05:26
- APP专享
- 扒圈小记
 7,019
7,019
美防长称日本是应对中国“侵略”不可或缺的国家,外交部回应
- 2025年03月31日
- 08:00
- APP专享
- 扒圈小记
- 6,915
视频|马斯克称火星将是美国的一部分
- 2025年03月31日
- 05:20
- APP专享
- 北京时间
- 5,574

24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)
投资研报 扫码订阅
股市直播
-

数字江恩今天 10:06:22
明日来说,只要不加速跌破今日低点都算正常;反之若再突破今日尾盘高点,则说明今日探底成功。但是,短线来说,3386还有压力。 -
数字江恩今天 10:06:15
看5分钟,第二浪如期走出了abc的内部形态。但这里,市场对3439的回踩是第二浪,还是新的下跌,颇有争论。这个分歧可以以3297为界,这里若不跌破,那边是新上涨的1+2浪;反之,跌破则可以是新的下跌。所以不跌破3297,那么本周和今日形态一样,都是探底回升。【更多独家重磅股市观点请点击】 -
数字江恩今天 10:05:55
从指数来看,今日上证、创业板、科创50、国政2000四大指数全部都是探底反弹的长下影。银行、石油、电力、煤炭、电信运营商这些权重是今日大盘做大的支撑,盘中反弹时财税数字化、算力、ai智能体较为积极。 -
数字江恩今天 10:05:47
A股两市今日成交5315 + 6901 = 12216 亿人民币,相对昨日缩量约1300亿。大盘低开震荡后,盘中一度恐慌性杀跌,午后震荡拉起,收了一根长下影小阴线,收跌16个点。个股方面,只有1/4的个股收红上涨。 -
数字江恩今天 10:05:40
探底回升 -

趋势领涨今天 09:29:43
华为公布2024年业绩了,营收高达8621亿元,同比增长22%,创历史第二高纪录(仅次于2020年的8914亿元);净利润626亿元,上一年同期是净利润870亿元,同比下滑出现了大幅下滑,为什么下滑?因为华为在加大投资,华为轮值董事长孟晚舟强调,“2025年,华为将进一步把‘以质取胜’落实到各项管理制度和业务活动中,坚持质量目标牵引,不断提升质量竞争力。”同时,华为将持续做强根生态,向开发者持续提供好用易用的工具和产品,加速生态繁荣,共促产业活力。 -
趋势领涨今天 09:26:55
国新办今日就第八届数字中国建设峰会有关情况举行发布会,国家发展改革委党组成员、国家数据局局长刘烈宏表示,持续推进高质量数据供给。高质量的数据供给是人工智能发展的不竭动力。行业应用和典型场景的落地,是推动人工智能进化普及的关键一环。基于我国海量数据(sh603138)资源和丰富应用场景的优势,我们将加快推动数据要素和人工智能产业赋能、终端应用和场景培育相结合。积极引导做好高质量数据集建设工作,“人工智能+”行动到哪里,高质量数据集的建设和推广就要到哪里。进一步推动数据标注产业高质量发展,为人工智能技术创新和产业应用提供坚实的数据基础。 -

张馨元今天 08:21:18
国新办今日就第八届数字中国建设峰会有关情况举行发布会,工业和信息化部信息技术发展司司长王彦青表示,推进原创性数字技术攻关,聚焦人工智能、关键软件、工业互联网等重点领域,深化技术创新、产业创新深度融合,培育一批创新成果转化平台,助力科技成果产业化,持续提升数字技术的自主创新能力。实施数字产业优质企业培育工程,建立多层次、分阶段、递进式企业培育体系,培育一批具有产业链控制力的生态主导型企业,开展数字产业集群梯度培育行动,进一步发挥产业集聚优势,打造一批具有国际竞争力的数字产业集群。 -
张馨元今天 08:05:52
华为今日发布2024年年度报告,报告显示,华为经营结果符合预期,实现全球销售收入8,621亿元人民币,同比增长22.4%;净利润626亿元人民币,同比减少28%。2024年研发投入达到1,797亿元人民币,约占全年收入的20.8%,近十年累计投入的研发费用超过12,490亿元人民币。 -

巨丰投资张翠霞今天 07:28:19
4小时运行结束,总结全天市场运行,1)月底收官之战,再次绿盘报收,相较于24年下半年月底拉尾盘,从12月底节奏发生改变,不错指数弱势,题材出现转折点,deepseek算力出现超跌修复,化解题材A杀走势,四月份年报披露正式开始,重点关注个股基本面,预期结构型行情;2)量能,沪深两市今日成交额12443亿元,较上个交易日11450亿元增加993亿元;3)行业板块方面,以加权涨幅来看56家行业9家红盘,电信运营、石油、银行等板块涨幅居前;航空、酒店餐饮、化纤等板块跌幅居前;4)市场延续结构型行情,题材热点快速轮动。详细解盘,可关注《翠霞首席课》的“热点直击”和“操盘指南”~~~