


近日,昆仑万维 2050 研究院院长颜水成教授团队、联合北京大学袁粒助理教授团队提出一种混合注意力头模型。
该模型基于一种通用的基础网络结构,能被用于任何基于 Transformer 或基于多头注意力机制的模型。
目前,主流大模型比如 ChatGPT 和 SORA,均构建于 Transformer 架构之上。
而该课题组期望混合注意力头模型能用于上述模型之中,从而帮助降低用户使用成本。
此外,本次提出的混合注意力头模型还能在移动端等计算资源受限的场景下提升大模型的适用性。
 (来源:arXiv)
(来源:arXiv)研究中,该团队在视觉理解模型(ViT,Vision Transformer)、视觉生成模型(DiT,Diffusion Transformers)以及大语言模型(LLM,Large Language Model)上进行了大量实验。
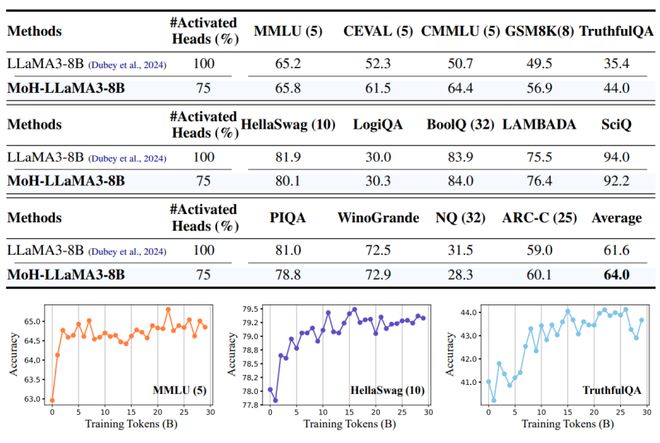
结果表明,混合注意力头模型只需使用 50% 到 90% 的注意力头,就能超过原始模型的性能。
为了进一步扩展混合注意力头模型方法的适用性,他们还通过实验证明预训练的多头注意力模型(比如 LLaMA3-8B)可以继续优化为混合注意力头模型。
值得注意的是,MoH-LLaMA3-8B 仅使用 75% 的注意力头,就能在 14 个基准测试中实现 64.0% 的平均准确率,这比 LLaMA3-8B 提升了 2.4%。
这些实验结果表明,混合注意力头模型是一种极具潜力的多头注意力替代方案,能为开发更先进、更高效的基于注意力的模型奠定基础。

既能降低计算成本,又能维持模型性能
众所周知,OpenAI 此前提出的扩展法则(Scaling Laws),在近两年来成为指导大模型发展的基本原理。
Scaling Laws 表明:Transformer 模型的性能主要依赖于参数规模和训练数据规模的扩展。
然而,随着大模型参数规模的不断扩大,训练和使用大模型的成本也急剧上升,高昂的成本极大拉高了用户使用门槛。
因此,本次研究团队希望探索一种既能降低计算成本、又能不降低大模型性能的方案。
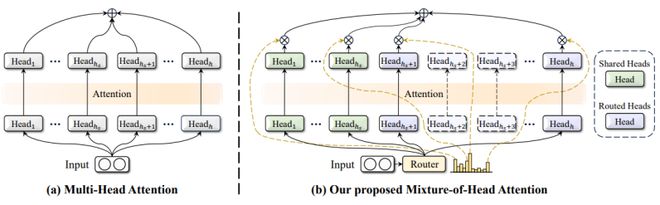
研究中,他们发现在 Transformer 模型核心模块之一的多头注意力层(MHA,Multi-Head Attention)中,存在可以去除的冗余计算。
具体来说,在多头注意力层中,每个注意力头负责处理不同领域的知识,它们分别扮演着各自领域的“专家”角色。
然而,对于某个特定样本而言,它通常并不涉及所有领域的知识,因此只需激活部分注意力头即可完成计算。
这种“专家选择”的思路也与 ChatGPT 采用的混合专家模型(MoE,Mixture of Experts)相似,因此该课题组将这种大模型称为混合注意力头模型(MoH,Mixture-of-Head Attention)。
混合注意力头模型主要有三个优点:
首先,每个样本都能自适应地选择合适的注意力头,从而在降低计算量的同时保持模型的性能。
其次,在传统的多头注意力机制中,每个注意力头的权重是相同的,而混合注意力头模型会给每个注意力头分配不同的权重,从而能够提升大模型的灵活性和性能上限。
再次,混合注意力头模型基于一个通用的基础网络结构,因此能被用于任何一个基于 Transformer 或基于多头注意力的模型上。
 (来源:arXiv)
(来源:arXiv)
“兴奋得推掉周末出游计划”
如前所述,本次研究的目标在于降低大模型的计算成本。2024 年初,混合专家模型是最流行的高效大模型方案之一,尤其是 Mixtral 8x7B 模型的发布引发了业界和学界的极大关注。
而这也是该团队尝试改进混合专家模型的原因。但是,他们遇到的第一个困难便是混合专家模型没有一个很好用的开源代码。
为此,担任本次论文第一作者的北大博士生金鹏耗时三个月学习混合专家模型论文并编写代码。在随后的两个月里,他和同事依然没能找到有效的混合专家模型改进方案。
“可以说在前面几个月里,工作进展得非常缓慢。直到某个夜晚大家突然茅塞顿开。”他说。
那晚,由于大家对于混合专家模型的改进依然没有头绪。因此,金鹏等人开始重新审视整个 Transformer 模型结构。
据他介绍,标准的混合专家模型层能对 Transformer 中的前馈神经网络层(FFN,Feed-Forward Neural Network)进行替换。
因此,大家开始设想:混合专家模型结构能否用于 Transformer 中的多头注意力层?
关键时刻,本次论文通讯作者颜水成的一句话起到了四两拨千斤的作用,对于这一场景金鹏至今印象深刻。
他说:“颜老师说‘如果把 Multi-Head Attention 的输出投影矩阵按行分解,每个注意力头岂不是可以独立出来?’”
听完之后,金鹏冒出一个大胆想法:给每个独立的注意力头赋予一个稀疏的权重,不就是类似混合专家模型的稀疏激活结构吗?
即可以把多头注意力层中的注意力头,类比成混合专家模型中的专家,这样一来就能构建一个稀疏注意力结构,从而降低大模型的计算成本。
“讨论到这儿我和颜老师都认为这是一个很有希望的想法。我更是兴奋得连周末出游计划都推掉了,赶紧熬夜写代码和做实验。”金鹏表示。
“说实话,科研最让人热血沸腾的瞬间,可能不是论文被接收的那一刻,而是灵感突然爆发、思路豁然开朗的那一刻。”他继续说道。
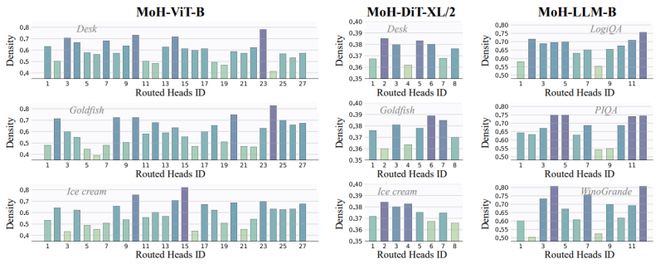
在实验中,由于有前几个混合专家模型代码的积累,金鹏和同事很快就实现了混合注意力头模型,并在视觉理解模型、视觉生成模型以及大模型上验证了混合注意力头模型的有效性。
 (来源:arXiv)
(来源:arXiv)同时,他们还在实验中总结了混合注意力头模型的两大关键成功要素:
其一,每个样本能够自适应地选择合适的注意力头,从而能在降低计算量的同时保持模型性能。
其二,在传统的多头注意力机制中,每个注意力头的权重是相同的,而混合注意力头模型能为每个注意力头分配不同的权重,从而能够提升模型的灵活性和性能上限。
接着,课题组开始继续探索模型的边界。此时,他们已经视觉理解模型、视觉生成模型以及大模型上证明:从头训练一个混合注意力头模型比训练一个多头注意力模型更有优势。
但是,他们希望进一步扩展混合注意力头模型方法的适用性,因此针对“预训练的多头注意力模型能否继续优化为混合注意力头模型”这一问题,该团队又开展了进一步的探索。
具体来说,他们选择 LLaMA3-8B 模型作为实验对象,借此证明 MoH-LLaMA3-8B 仅使用 75% 的注意力头,就可以超过原始的 LLaMA3-8B 模型。至此,研究终于完成。
日前,相关论文以《MOH:多头注意力作为多头注意力的混合物》(MOH:MULTI-HEAD ATTENTION AS MIXTURE-OFHEAD ATTENTION)为题发在 arXiv[1]。
金鹏是第一作者,北京大学助理教授袁粒、新加坡工程院院士&昆仑万维 2050 全球研究院院长颜水成担任共同通讯作者。
 图 | 相关论文(来源:arXiv)
图 | 相关论文(来源:arXiv)目前,本次论文仍在评审中。不过,在中外社交媒体上,已有科研工作者针对此次工作给予较高评价。
比如,有人在转发这篇论文时评论道:“思路挺有意思,但不确定在自己的模型上是否容易训练。”
与此同时,课题组已经开源了训练代码。“欢迎大家复现我们的实验结果,并与我们一起继续优化混合注意力头模型。”金鹏表示。
 图 | 金鹏(来源:金鹏)
图 | 金鹏(来源:金鹏)值得注意的是,金鹏本科毕业于清华大学电子工程系,那时他同时学习通讯、集成电路、信号处理和人工智能等课程。也正是在本科期间,他开始对人工智能产生兴趣。
后来,他考入北京大学信息工程学院读博,目前正在读博士四年级,导师是袁粒助理教授。
博士期间,金鹏专注于研究视觉多模态和文本多模态。然而,他的科研路程并不是那么顺利。
在前三年的读博生涯里,金鹏撰写了两个视频-文本表征学习的论文,但是这两篇论文接连被拒稿五次。
“那段时间导师、家人、朋友给了我很大帮助,让我没有因为接二连三的小挫折而丧失科研的信心。最终,在导师的帮助下我的第一篇论文终于被 NeurIPS(Conference and Workshop on Neural Information Processing Systems,神经信息处理系统大会)2022 收录。”他说。
而在 OpenAI 发布 ChatGPT 后,金鹏的研究开始聚焦于多模态大模型领域。
2023 年,他又来到昆仑万维 2050 研究院院长颜水成教授团队实习,期间开展了一系列关于大模型的研究,本次的混合注意力头模型正是其中的一项工作。
不过,目前混合注意力头模型只能将注意头的激活比例降低到 75% 左右,未来他希望争取能将注意头的激活比例降低到 50% 以下。

参考资料:
1.https://arxiv.org/pdf/2410.11842
排版:溪树
03/
04/
05/



VIP课程推荐
APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




