


转自:中国科技网
科技日报记者 操秀英
5月28日,浪潮信息发布“源2.0-M32”开源大模型。“源2.0-M32”在“源2.0”系列大模型已有工作基础上,创新性地提出和采用了“基于注意力机制的门控网络”技术,构建包含32个专家(Expert)的混合专家模型(MoE),并大幅提升了模型算力效率,模型运行时激活参数为37亿,在业界主流基准评测中性能全面对标700亿参数的LLaMA3开源大模型。
据介绍,针对MoE模型核心的专家调度策略,“源2.0-M32”采用的新型的算法结构“基于注意力机制的门控网络”,关注专家模型之间的协同性度量,有效解决传统门控网络下,选择两个或多个专家参与计算时关联性缺失的问题,使得专家之间协同处理数据的水平大为提升。“源2.0-M32”以“源2.0-2B”为基础模型设计,沿用并融合局部过滤增强的注意力机制(LFA, Localized Filtering-based Attention),通过先学习相邻词之间的关联性,然后再计算全局关联性的方法,能够更好地学习到自然语言的局部和全局的语言特征,对于自然语言的关联语义理解更准确,进而提升了模型精度。
在数据层面,“源2.0-M32”基于超过2万亿的token(文本中最小的语义单元)进行训练,覆盖万亿量级的代码、中英文书籍、百科、论文及合成数据。基于这些数据的整合和扩展,“源2.0-M32”在代码生成、代码理解、代码推理、数学求解等方面有着出色的表现。在算力层面,“源2.0-M32”为硬件差异较大训练环境提供了一种高性能的训练方法。针对MOE模型的稀疏专家计算,该模型采用合并矩阵乘法的方法,模算效率得到大幅提升。
基于在算法、数据和算力方面全面创新,“源2.0-M32”的性能得以大幅提升,在MATH(数学竞赛)、ARC-C(科学推理)榜单上超越了拥有700亿参数的LLaMA3大模型。
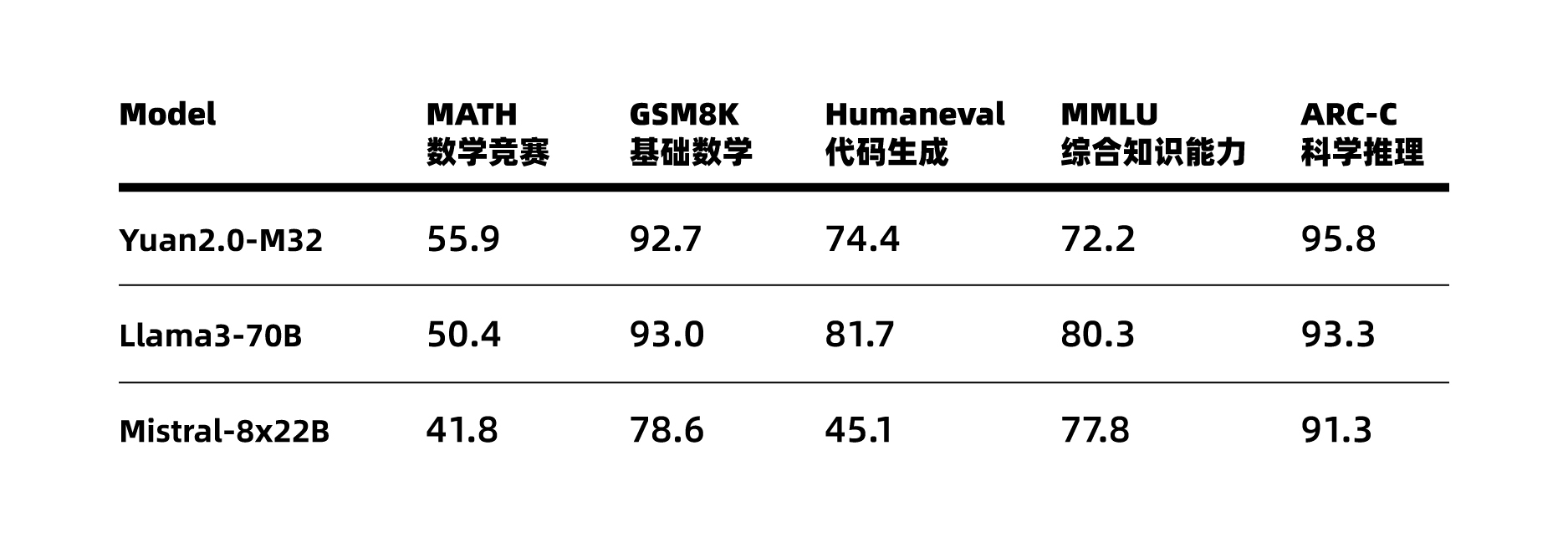
“源2.0-M32”大幅提升了模型算力效率,在实现与业界领先开源大模型性能相当的同时,显著降低了在模型训练、微调和推理所需的算力开销。
浪潮信息人工智能首席科学家吴韶华表示:当前业界大模型在性能不断提升的同时,也面临着所消耗算力大幅攀升的问题,给企业落地应用大模型带来了极大的困难和挑战。“源2.0-M32”是浪潮信息在大模型领域持续耕耘的最新探索成果,大幅提升的模算效率将为企业开发应用生成式AI提供模型高性能、算力低门槛的高效路径。“M32开源大模型配合企业大模型开发平台EPAI(Enterprise Platform of AI),将助力企业实现更快的技术迭代与高效的应用落地,为人工智能产业的发展提供坚实的底座和成长的土壤,加速产业智能化进程。”他说。
(浪潮信息供图)


VIP课程推荐
APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




