


安装新浪财经客户端第一时间接收最全面的市场资讯→【下载地址】
专题:OpenAI发布首个视频生成模型Sora:输文字出视频
爱范儿

OpenAI 的
降维打击
今天凌晨,OpenAI 从‘弹药库’里掏出了 AI 视频生成工具 Sora,瞬间占据了各大新闻头条。
就连一向和 OpenAI 不对付的马斯克也甘心承认 Sora 的强大,并借此盛赞‘在未来的几年里,人类借助 AI 的力量,将创造出卓越的作品。’
Sora 的强大之处在于能够根据文本描述,生成长达 60 秒连贯流畅的视频,其中包含细腻复杂的场景、生动的角色表情以及复杂的镜头运动。
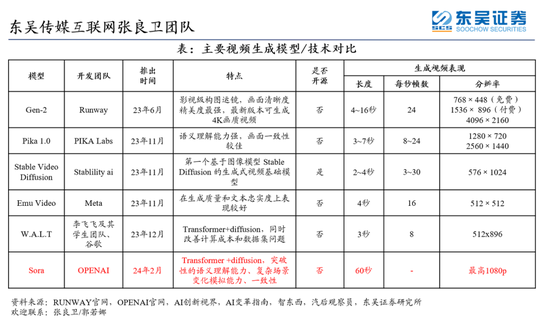
对比其他只能生成短至个位数长度的视频,Sora 的一分钟时长无疑起到了掀桌的效果。
更为重要的是,无论是在视频的真实性、长度、稳定性、一致性、分辨率还是对文本的理解方面,Sora 均展现出了目前最佳的水平。让我们先来欣赏一下官方发布的演示视频片段。
Prompt: Beautiful, snowy Tokyo city is bustling. The camera moves through the bustling city street, following several people enjoying the beautiful snowy weather and shopping at nearby stalls. Gorgeous sakura petals are flying through the wind along with snowflakes.
在这段视频中,无人机视角下的一对情侣穿梭于繁华的城市街道,美丽的樱花花瓣伴随着雪花在空中翩翩起舞。
当其他工具还在努力保持单镜头稳定时,Sora 已经丝滑实现多镜头的无缝切换,且镜头切换的连贯性和对象的一致性效果都遥遥领先,真降维打击。👇
视频源自 @gabor
在过去,要拍摄这样一段视频可能需要耗费大量时间和精力进行剧本创作、分镜头设计等一系列繁琐的工作。而现在,仅需一段简单的文本描述,Sora 就能彻底生成这样的大场面,相关从业者或许已经开始瑟瑟发抖了。
网友 @debarghya_das 用 OpenAI Sora 剪辑、David Attenborough 在 Eleven Labs 上的声音以及 iMovie 上 Youtube 上的一些自然音乐样本,在 15 分钟内制作了这个 20 多秒的预告片。
Sora 是怎么实现强大效果的?
OpenAI 也发布了一份关于 Sora 详细的技术报告,介绍了其背后的技术原理和应用。
那么,Sora 是如何实现这一突破的呢?受到 LLM 成功实践经验的启发,OpenAI 引入了视觉块嵌入代码(patches),这是一种高度可扩展且有效的视觉数据表现形式,能够极大地提升生成模型处理多样化视频和图像数据的能力。

在高维度空间中,OpenAI 首先将视频数据压缩至一个低维潜在空间,然后再将其分解为时空嵌入,从而将视频转化为一系列编码块。
接下来,OpenAI 训练了一个专门用于降低视觉数据维度的网络。该网络以原始视频作为输入,输出的潜在表示在时间和空间上都经过了压缩。Sora 正是在这个压缩后的潜在空间中进行训练,并在该空间内生成视频。
此外,OpenAI 还训练了一个解码器模型,能够将这些潜在表征还原为像素级的视频图像。
通过对压缩后的视频输入进行处理,研究人员能够提取出一系列的时空 patchs,这些 patchs 在模型中扮演着类似于 Transformer Tokens 的角色。
采用基于 patchs 的表现形式,Sora 能够适应不同分辨率、持续时间及宽高比的视频和图像,在生成新视频内容时,可以通过将这些随机初始化的 patchs 按照需要的大小排列成网格,来控制最终视频的大小和形式。

尽管上述原理听起来颇为复杂,但实际上 OpenAI 所用到的这项新技术--视觉块嵌入代码(简称视觉块)。就好比是将一堆杂乱无章的积木整理好放入一个小盒子中。如此一来,即便面对众多积木,只要找到了这个小盒子就能轻松找到所需积木。
由于视频数据被转化为了一个个小方块的形式,当 OpenAI 向 Sora 提供一个新的视频任务时,他们首先会从该视频中提取出一些包含时间和空间信息的小方块。随后将这些小方块交给 Sora 让其根据这些信息生成新的视频。
这样就可以像拼拼图一样,把视频重新组合起来。这样做的好处是,计算机可以更快地学习和处理各种不同类型的图片和视频。
随着 Sora 的训练越来越深入,OpenAI 的研究人员还发现随着训练计算量的增加,样本质量得到了显著提高。
OpenAI 发现直接在数据的原始尺寸上进行训练具有诸多优势:
Sora 训练时没有对素材进行裁切,使得 Sora 能够直接按照不同设备的原生宽高比创建内容。
在视频的原生宽高比上进行训练,能够显著提升视频的构图与布局质量。

此外,Sora 还具有以下特性:
训练文本到视频生成系统需要大量带有文字标题的视频。OpenAI 将在 DALL·E 3 中引入的重新标注技术应用到视频上。
类似于 DALL·E 3,OpenAI 利用 GPT 将用户的简短提示转换成更长的详细说明,然后发送给视频模型,从而使得 Sora 能够生成高质量的视频。
除了可以从文字转化而来,Sora 还能接受图片或已有视频的输入。这项功能让 Sora 能够完成各种图片和视频编辑任务,比如制作无缝循环视频、给静态图片添加动画效果、延长视频的播放时间等。
形成‘SORA’字样的逼真云朵图像。

在一个装饰华丽的历史大厅里,一道巨大的海浪正准备冲击而来。两位冲浪者抓住机会,巧妙地驾驭着海浪。

无需任何预先示例,Sora 就能改变视频中的风格和环境。甚至两个风格迥异的视频也能平滑连接起来。

Sora 还能文生图,研究团队通过在一个时间范围仅为一帧的空间网格里排列高斯噪声块来创造出各种尺寸的图像,最大分辨率达到了 2048x2048。

实在的 OpenAI 也坦率地承认了 Sora 当前存在的局限问题,比如它无法模拟复杂场景的物理效应,以及理解某些特定因果关系。举例来说,它无法精确模拟像玻璃破碎这样的基本物理互动。
相反方向的跑步
不过 OpenAI 坚信,Sora 目前的能力表明,持续扩展视频模型是朝着开发能够模拟物理和数字世界及其内部的物体、动物和人类的有能力的模拟器的一条充满希望的途径。
世界模型,AI 的下一个方向?
OpenAI 发现,在大规模训练下,Sora 展示出了一系列引人注目的涌现能力,能够在一定程度上模拟真实世界中的人、动物和环境。
这些能力并非基于对三维空间或物体的特定预设,而是由大规模数据驱动产生的。
三维空间的连贯性:Sora 能生成带有动态视角变化的视频。当摄像机位置和角度变动时,视频中的人物和场景元素能够在三维空间连贯移动。
远距离连续性与物体持久性:即使人物、动物或物体被遮挡或移出画面,Sora 也能保持长时间视频的连续性。同样,它能在同一视频样本中多次展示同一角色,并确保外观一致。
数字世界的模拟:Sora 还能模拟数字化过程,如视频游戏,只需提及‘Minecraft’等字样,就能激发其相关能力。
OpenAI 将 Sora 视为‘能够理解和模拟现实世界的模型的基础’,相信其能力‘将是实现 AGI 的重要里程碑’。
对于 Sora 的到来,英伟达高级科学家 Jim Fan 表示:
如果你认为 OpenAI 的 Sora 就像 DALL·E 那样,是一个用于创意实验的工具,那你可能需要重新考虑了。
Sora 实际上是一款基于数据的物理模拟引擎,它能够模拟出真实或虚构的世界。这款模拟器通过去噪和梯度计算,学会了复杂的图像渲染、‘直观’的物理行为、长远规划能力以及语义层面的理解。
而这种模型能力的基础正是世界通用模型,这是一种人工智能系统,它的目标是建立一个可以更新状态的神经网络模块,用以记忆和建模环境。
这种模型能够根据当前的观测(如图像、状态等)和即将采取的动作,预测下一个可能的观测。它通过学习世界的规律和常识,模拟环境中可能的未来事件。

实际上,世界模型并不是什么新鲜的概念,早在去年 12 月,AI 视频生成的领头羊 Runway 就官宣下场打造通用世界模型,目的是创建一种与现有的 LLM 不同,并且能够更真实模拟现实世界的人工智能系统。
具体来说,世界模型的核心思想是通过记忆历史经验来学习世界的运作方式,进而预测未来可能发生的事件。例如,从一段物体下落的录像中,模型可以根据当前的画面预测下一帧的画面,从而学习到物体运动的物理规律。
图灵奖得主 Yann LeCun 也曾提出过类似的概念,并批评了基于概率生成自回归的大模型,如 GPT,认为这类模型无法破解幻觉难题。LeCun 和他的团队甚至预言,GPT 这类模型在未来五年内可能会被淘汰。
世界模型可以被看作是人工智能领域中,试图创建更接近人类智能水平 AI 的一个研究方向。通过模拟和学习真实世界的环境和事件,世界模型有潜力推动 AI 向更高层次的模拟和预测能力发展。
2 月份的时候,知名风险投资公司 a16z 的合伙人 Justine Moore 深入分析了 AI 视频生成领域的现状。在生成式 AI 逐渐步入大众视野的两年间,AI 视频生成领域迎来了百花齐放,百家争鸣的繁荣景象。
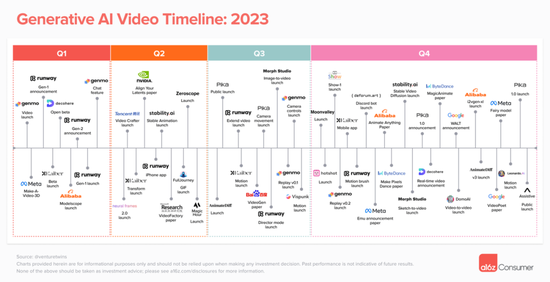
随着 OpenAI Sora 的加入,AI 视频生成领域势必掀起滔天巨浪,现有的主流平台如 Runway、Pika 和 Stable Video Diffusion 等都可能会受到波及。
同时,独立创作者的游戏规则将会彻底改变,任何人只要有创意和想法,就可以使用 Sora 来生成自己的视频内容。创作门槛的降低,也意味着独立创作者将会迎来黄金时代。
正如《三体》中所说,‘主不在乎’,无论目前的竞争态势如何,AI 视频生成领域都可能会被新的技术和创新所颠覆。而 Sora 的入局仅仅只是个开始,远不是终点。

责任编辑:凌辰



VIP课程推荐
APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




