

Jeff Dean万字长文:2020谷歌10大领域AI技术发展

欢迎关注“创事记”的微信订阅号:sinachuangshiji
文/QJP、小匀
来源: 新智元(ID:AI_era)
Jeff Dean发了一篇几万字长文,回顾了这一年来谷歌在各个领域的成就与突破,并展望了2021年的工作目标。
“当我20多年前加入谷歌的时候,只想弄清楚如何真正开始使用电脑在网络上提供高质量和全面的信息搜索服务。时间快进到今天,当面对更广泛的技术挑战时,我们仍然有着同样的总体目标,那就是组织全世界的信息,使其普遍可获取和有用。
2020年,随着世界被冠状病毒重塑,我们看到了技术可以帮助数十亿人更好地交流,理解世界和完成任务。我为我们所取得的成就感到骄傲,也为即将到来的新的可能性感到兴奋。”
Google Research 的目标是解决一系列长期而又重大的问题,从预测冠状病毒疾病的传播,到设计算法、自动翻译越来越多的语言,再到减少机器学习模型中的偏见。
本文涵盖了今年的关键亮点。
新冠病毒和健康
COVID-19的影响给人们的生活带来了巨大的损失,世界各地的研究人员和开发人员联合起来开发工具和技术,以帮助公共卫生官员和政策制定者理解和应对这场流行病。
苹果和谷歌在2020年合作开发了暴露通知系统(ENS) ,这是一种支持蓝牙的隐私保护技术,如果人们暴露在其他检测呈阳性的人群中,可以通知他们。
ENS 补充了传统的接触者追踪工作,并由50多个国家、州和地区的公共卫生当局部署,以帮助遏制感染的传播。
在流感大流行的早期,公共卫生官员表示,他们需要更全面的数据来对抗病毒的快速传播。我们的社区流动性报告,提供了对人口流动趋势的匿名追踪,不仅帮助研究人员了解政策的影响,如居家指令和社会距离,同时还进行了经济影响的预测。
我们自己的研究人员也探索了用这种匿名数据来预测COVID-19的传播,用图神经网络代替传统的基于时间序列的模型。
冠状病毒疾病搜索趋势症状允许研究人员探索时间或症状之间的联系,比如嗅觉缺失---- 嗅觉缺失有时是病毒的症状之一。为了进一步支持更广泛的研究社区,我们推出了谷歌健康研究应用程序,以提供公众参与研究的方式。
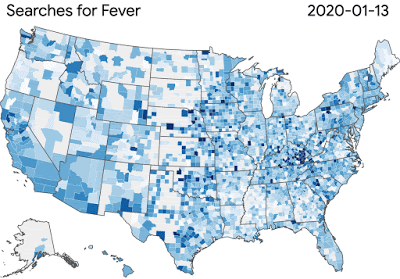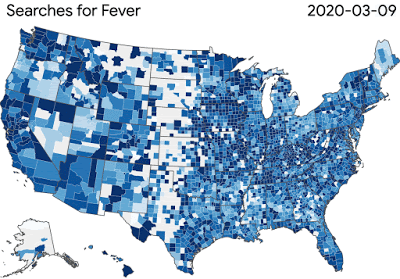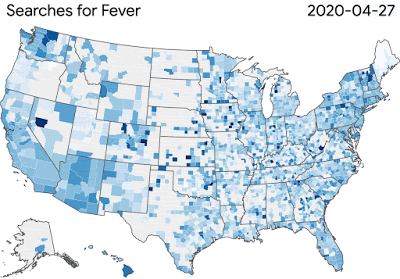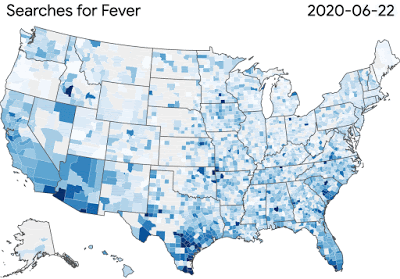 图:COVID-19搜索趋势正在帮助研究人员研究疾病传播和症状相关搜索之间的联系
图:COVID-19搜索趋势正在帮助研究人员研究疾病传播和症状相关搜索之间的联系谷歌的团队正在为更广泛的科学界提供工具和资源,这些科学界正在努力解决病毒对健康和经济的影响。
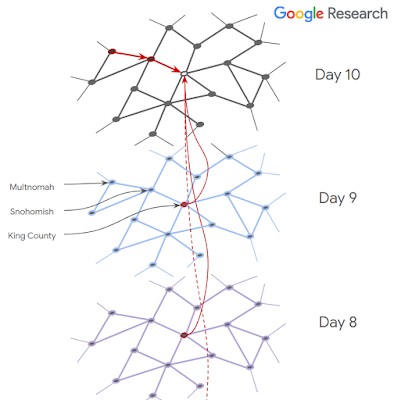 图:一个模拟新冠病毒扩散的时空图
图:一个模拟新冠病毒扩散的时空图我们还致力于帮助识别皮肤疾病,帮助检测老年黄斑变性(在美国和英国是导致失明的主要原因,在全世界是第三大致盲原因) ,以及潜在的新型非侵入性诊断(例如,能够从视网膜图像中检测出贫血的迹象)。
 图:深度学习模型从视网膜图像中量化血红蛋白水平。血红蛋白水平是检测贫血的一项指标
图:深度学习模型从视网膜图像中量化血红蛋白水平。血红蛋白水平是检测贫血的一项指标今年,同样的技术如何可以窥视人类基因组,也带来了令人兴奋的演示。谷歌的开源工具DeepVariant,使用卷积神经网络基因组测序数据识别基因组变异,并在今年赢得了FDA的4个类别中的3个类别的最佳准确性的挑战。丹纳-法伯癌症研究所领导的一项研究使用同样的工具,在2367名癌症患者中,将导致前列腺癌和黑色素瘤的遗传变异的诊断率提高了14% 。
天气、环境和气候变化
机器学习能帮助我们更好地了解环境,并帮助人们在日常生活中以及在灾难情况下做出有用的预测。
对于天气和降水预报,像 NOAA 的 HRRR 这样基于计算物理的模型一直占据着主导地位。然而,我们已经能够证明,基于ML的预报系统能够以更好的空间分辨率预测当前的降水量(“西雅图的本地公园是不是在下雨? ”而不仅仅是“西雅图在下雨吗? ”)它能够产生长达8小时的短期预报,比 HRRR 准确得多,并且能够以更高的时间和空间分辨率更快地计算预报。

我们还开发了一种改进的技术,称为 HydroNets,它使用一个神经网络来建模真实的河流系统,以更准确地了解上游水位对下游洪水的相互作用,做出更准确的水位预测和洪水预报。利用这些技术,我们已经将印度和孟加拉国的洪水警报覆盖范围扩大了20倍,帮助在25万平方公里内更好地保护了2亿多人。
可访问性(Accessibility)
机器学习继续为提高可访问性提供了惊人的机会,因为它可以学会将一种感官输入转化为其他输入。举个例子,我们发布了 Lookout,一个 Android 应用程序,可以帮助视力受损的用户识别包装食品,无论是在杂货店还是在他们家的厨房橱柜里。

Lookout 背后的机器学习系统演示了一个功能强大但紧凑的机器学习模型,可以在有近200万个产品的手机上实时完成这一任务。
同样,使用手语交流的人很难使用视频会议系统,因为即使他们在手语,基于音频的扬声器检测系统也检测不到他们在主动说话。为视频会议开发实时自动手语检测,我们提出了一种实时手语检测模型,并演示了如何利用该模型为视频会议系统提供一种识别手语者为主动说话者的机制。
机器学习在其他领域的应用
2020年,我们与 FlyEM 团队合作,发布了果蝇半脑连接体,这是一种大型突触分辨率图谱的大脑连接,重建使用大规模机器学习模型应用于高分辨率电子显微镜成像的脑组织。这些连接体信息将帮助神经科学家进行各种各样的研究,帮助我们更好地理解大脑是如何运作的。
负责任的人工智能
为了更好地理解语言模型的行为,我们开发了语言可解释性工具(LIT) ,这是一个可以更好地解释语言模型的工具包,使得交互式探索和分析语言模型的决策成为可能。
我们开发了在预训练语言模型中测量性别相关性的技术,以及在谷歌翻译中减少性别偏见的可扩展技术。
为了帮助非专业人员解释机器学习结果,我们扩展了2019年引入的 TCAV 技术,现在提供了一套完整而充分的概念。我们可以说“毛”和“长耳朵”是“兔子”预测的重要概念。通过这项工作,我们还可以说,这两个概念足以充分解释预测; 您不需要任何其他概念。
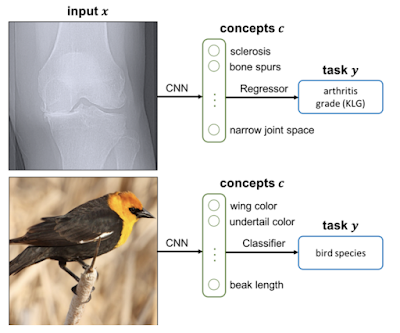
概念瓶颈模型是一种技术,通过训练模型,使其中一层与预先定义的专家概念(例如,“骨刺呈现” ,或“翅膀颜色” ,如下所示)保持一致,然后再对任务做出最终预测,这样我们不仅可以解释这些概念,还可以动态地打开/关闭这些概念。
自然语言理解
更好地理解语言是我们今年看到相当大进展的一个领域。谷歌和其他公司在这个领域的大部分工作现在都依赖于transformer,这是一种特殊风格的神经网络模型,最初是为了解决语言问题而开发的(但是越来越多的证据表明,它们对图像、视频、语音、蛋白质折叠以及其他各种各样的领域也很有用)。
在2020年,我们描述了 Meena,一个对话机器人,可以聊任何事情。
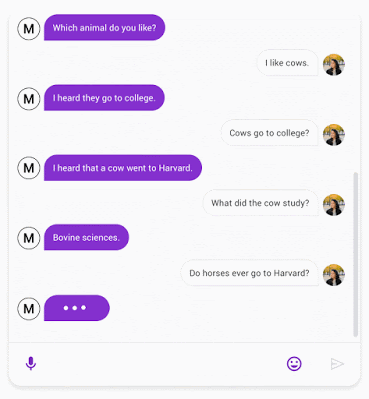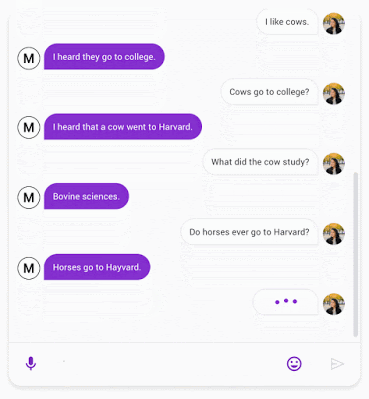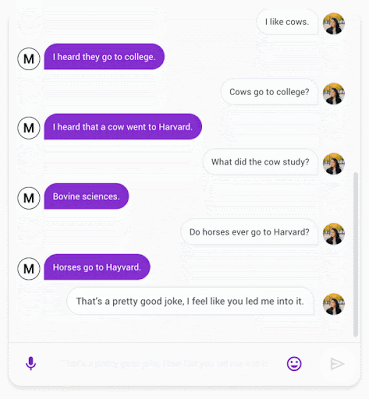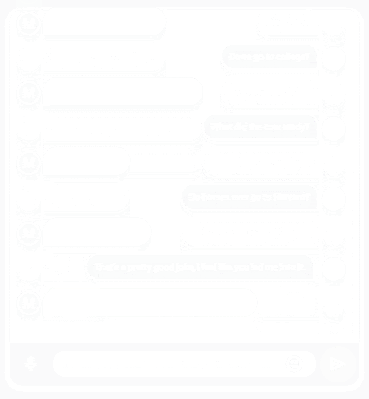
机器学习算法
谷歌仍向无监督学习方向大力发展,例如2020年开发的SimCLR,推进自监督和半监督学习技术。
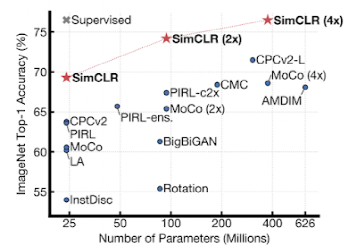 使用不同的自监督方法(在ImageNet上预训练)学习的表示形式,对ImageClass的分类器进行ImageNet top-1准确性训练。灰色十字表示受监管的ResNet-50。
使用不同的自监督方法(在ImageNet上预训练)学习的表示形式,对ImageClass的分类器进行ImageNet top-1准确性训练。灰色十字表示受监管的ResNet-50。强化学习
强化学习通过学习其他主体以及改进探索,谷歌已经提高了RL算法的效率。
他们今年的主要重点是离线RL,它仅依赖于固定的,先前收集的数据集(例如先前的实验或人类演示),从而将RL扩展到了无法即时收集训练数据的应用程序中。研究人员为RL引入了对偶方法,开发了改进的算法以用于非策略评估,此外,他们正在与更广泛的社区合作,通过发布开源基准测试数据集和Atari的DQN数据集来解决这些问题。
 使用DQN重播数据集的Atari游戏的离线RL
使用DQN重播数据集的Atari游戏的离线RL另一个研究方向是通过学徒制学习(apprenticeship learning),向其他代理学习,从而提高了样本效率。
需要注意的是,将RL扩展到复杂的实际问题来说是一个重要的挑战。
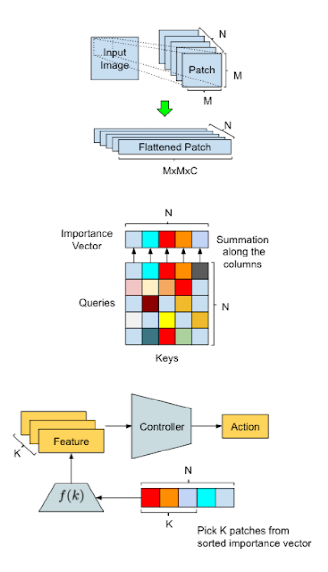
概述我们的方法并说明AttentionAgent中的数据处理流程。顶部:输入转换 - 一个滑动窗口将输入图像分割成更小的补丁,然后将它们 "扁平化",以便将来处理。中间。补丁选举 - 修改后的自我注意力模块在补丁之间进行投票,以生成补丁重要性向量。底部:动作生成--AttentionAgent在补丁之间进行投票,生成补丁的重要性向量。行动生成--AttentionAgent选择重要性最高的补丁,提取相应的特征,并基于这些特征做出决策。
AutoML
毫无疑问,这是一个非常活跃和令人兴奋的研究领域。
我在AutoML-Zero中:不断学习的代码,我们采用了另一种方法,即为演化算法提供一个由非常原始的运算(例如加法,减法,变量赋值和矩阵乘法)组成的搜索空间,以查看是否有可能从头开始发展现代ML算法。
但是,有用的算法实在太少了。如下图所示,该系统重塑了过去30年中许多最重要的ML发现,例如线性模型,梯度下降,校正线性单位,有效的学习率设置和权重初始化以及梯度归一化。

更好地理解ML算法和模型
随着神经网络被做得更宽更深,它们往往训练得更快,泛化得更好。这是深度学习中的一个核心奥秘,因为经典学习理论表明,大型网络应该超配更多。
在无限宽的限制下,神经网络呈现出惊人的简单形式,并由神经网络高斯过程(NNGP)或神经切线核(NTK)来描述。谷歌研究人员从理论和实验上研究了这一现象,并发布了Neural Tangents,这是一个用JAX编写的开源软件库,允许研究人员构建和训练无限宽度的神经网络。
 左:该示意图显示了深层神经网络如何随着简单的输入/输出图变得无限宽而引发它们。右图:随着神经网络宽度的增加,我们看到在网络的不同随机实例上的输出分布变为高斯分布。
左:该示意图显示了深层神经网络如何随着简单的输入/输出图变得无限宽而引发它们。右图:随着神经网络宽度的增加,我们看到在网络的不同随机实例上的输出分布变为高斯分布。机器感知
对我们周围世界的感知--对视觉、听觉和多模态输入的理解、建模和行动--仍然是一个具有巨大潜力的研究领域,对我们的日常生活大有裨益。
2020年,深度学习使3D计算机视觉和计算机图形学更紧密地结合在一起。CvxNet、3D形状的深度隐含函数、神经体素渲染和CoReNet是这个方向的几个例子。此外,他们关于将场景表示为神经辐射场的研究(又名NeRF,也可参见本篇博文)是一个很好的例子,说明Google Research的学术合作如何刺激神经体量渲染领域的快速进展。
在与加州大学伯克利分校合作的《学习因素化和重新点亮城市》中,谷歌提出了一个基于学习的框架,用于将户外场景分解为时空变化的照明和永久场景因素。这能为任何街景全景改变照明效果和场景几何,甚至将其变成全天的延时视频。

2020年,他们还使用神经网络进行媒体压缩的领域不断扩大,不仅在学习的图像压缩方面,而且在视频压缩的深层方法,体压缩以及深不可知的图像水印方面都取得了不错的成绩。

第一行:没有嵌入消息的封面图像。第二行:来自HiDDeN组合失真模型的编码图像。第三行:来自我们模型的编码图像。第四行:HiDDeN组合模型的编码图像和封面图像的归一化差异。第五行:模型的归一化差异
通过开源解决方案和数据集与更广泛的研究社区进行互动是另一个重要方面。2020年,谷歌在MediaPipe中开源了多种新的感知推理功能和解决方案,例如设备上的面部,手和姿势预测,实时身体姿势跟踪,实时虹膜跟踪和深度估计以及实时3D对象检测。

“最后,展望这一年,我特别热衷于构建更多通用机器学习模型的可能性,这些模型可以处理各种模式,并且可以通过很少的培训示例来自动学习完成新任务。
该领域的进步将为人们提供功能更强大的产品,为全世界数十亿人带来更好的翻译,语音识别,语言理解和创作工具。
这种探索和影响使我们对工作感到兴奋!”


作者简介

新智元
作者文章

推荐阅读
- “工具人”钉钉
-

- 被钉钉寄予厚望的钉钉宜搭平台,在“云钉一体”战略后,该平台的出现做实了钉钉“工具人”的定位。详细>>
- “印钞机”悦刻,为何着急上市
-

- 中国烟草是没机会了,但它的“替换股”电子烟龙头老大——雾芯科技即将赴美上市。详细>>
- 快手通过聆讯:9个月营收407亿 需平衡主播与平台关系
-

- 1月16日报道 快手科技通过港交所上市聆讯,并更新招股书,预计2月初在港交所上市。详细>>
- Playtika上市:市值130亿美元 史玉柱资本腾挪数年
-

- 以色列棋牌游戏Playtika(股票代码为“PLTK”)昨日在美国纳斯达克上市,发行价为27美元,之前发行区间为22美元到24美元。详细>>