





摘要
今天,是成为创业者的绝佳时机。
今天,可能是成为创业者的绝佳时机。
但再强大的大模型 api,距离产品落地,仍有不少距离。
如何寻找最佳落地场景,根据场景找到最合适的大模型,解决模型的工程化部署以及数据的实时交互,以及如何在和用户进行互动时,保证模型本身的的安全性以及用户数据的安全性……
技术的落地,面临着各种苦难和挑战。
所幸,我们不是在 PC 互联网早期的年代,需要手搓代码、自行搭建服务器,所有业务完全从 0 起步。
我们有了云服务,以及围绕云服务诞生的各种上下层的服务,让创业,尤其是 AI 创业这件事,变得「如此简单」。
在 AGI Playground 2024 上,亚马逊云科技大中华区产品部 大数据与人工智能产品总监 Troy Cui,分享了亚马逊云科技在帮助创业者如何实现 AI 应用、乃至应用出海上的优秀经验。
以下内容基于公开演讲,经 Founder Park 整理。

01 让企业更轻松拿下全球市场
英国著名科幻作家亚瑟·克拉克曾提到:「任何非常先进的技术,初看都与魔法无异」,在人类历史上,这句话被一次次的印证。
19 世纪,用电能驱动灯泡的时候,1979 年爱迪生发明电灯泡,极大地推动了第二次工业革命。
1947 年开始的数字革命,晶体管和运算放大器的创新引发了电子学的「大爆炸」,导致了手机和笔记本电脑的诞生,这场革命也彻底改变了通信方式,使科技成为我们日常生活的一部分。
1983 年,TCP/IP、互联网技术的诞生,诞生了基于互联网的各种新业务。亚马逊也应运而生。
亚马逊在线的零售业务,服务于全球数以亿计的客户。这些强大的技术也让亚马逊云科技在早期就关注到怎么去做管理和配置我们的基础设施服务。
不管客户规模大小,不管他有多新,也可以应用到和大公司同等能力的基础设施服务,不管是存储网络还是数据服务,应该有一个拥有同等安全、按需付费、可靠且足够经济的方案。

时至今日,亚马逊云科技在全球 33 个国家和地区有 105 个可用区,提供超过 200 个服务。
而且,这些服务仍旧在持续创新中。
哪怕是已经存在 18 年之久的 Amazon S3 存储服务、数据库服务,在去年也进行了新的发布——Amazon S3 Express。这已经是上一个 18 年,大家认为非常成熟的服务,亚马逊云科技至今仍在做进一步的更新和迭代。
而借助亚马逊云科技的服务,我们让大量客户可以更方便地服务全球客户,开拓更多商业市场。
原来做录像带租赁的 Netflix,用了亚马逊云科技的大量服务,如今在全球 190 多个国家和地区做流媒体服务。
对于中国企业的出海,也有像 OPPO 这样借由亚马逊云科技在海外进行布局的企业,他们已经成功做到全球手机出货量 Top5。
02 构建 AI 应用第一步:选择合适的模型
2023 年,ChatGPT 引领的 AI 之年。
亚马逊云科技在帮助客户做 AI 落地的过程中,也观察到 2023 年是「生成式 AI 的 POC(概念验证测试)年」。我们更多是做原型的验证,以及可行性的验证。
但是从去年年底到今年上半年,我们看到很多场景下,AI 已经真的逐渐被客户用于生产了。很多企业客户已经开始走这一步了,在这中间我们认为不可避免地会有以下四个内容要做。
首先要选好应用场景、切入场景;第二是要选择一个合适的工具帮助落地;第三是真正落地后涉及到的三公里问题:工程化怎么解决?

这个问题很重要,当做到生产的时候就需要考虑规模化应用。今天是一个人、十个人、一百个人做 POC testing(proof of concept,概念验证测试),但当开始生产的时候,DAU 要做到千万级,你的工程化一定和 100 个人用完全不一样。上线之后,一定会面临非常多的监管,这又涉及到安全的问题怎么解决。
关于业务场景的选择,首先是目标的创新,我们看到一些 toC 的业务,尤其是新的 workflow(工作流),往往是基于「目标」的创新。很多企业客户,他们在思考创新从哪开始的时候,往往想的是从大处着眼、小处着手,think big but start small。先从一个具体的场景做可行性验证,之后才在企业里面争取更大的投入。
在场景选择之外的另外三项,亚马逊科技就有比较强大的能力,能够支撑创业者依次实现项目的落地。
首先是模型和模型工具的选择:Performance & Accepability(高性能,可触达)。
大家普遍都会非常关注性能,在涉及选择 AI 模型的时候,大家首先会思考「我要选择什么样的模型」,「我要保证这个模型在能力上能满足自己应用的需求」。
在进行可行性验证的时候,我们得知道「上限」在哪,选择一个最棒的模型来保证自己的上限达标。
但是当我们去思考生产布局的时候,一个「上限」的 performance,不见得是你需要思考的全部。我们还需要考虑一个大模型的 inference status 能不能保证终端客户的实时性要求?当你开始规模化做业务的时候,单一模型的推理成本是不是可以保证 ROI 在你的口径空间里?
很多时候,我们在很多行业都会碰到一个三角难题,没办法同时满足三项都达到完美。这里面一定会是一个折中的结果。
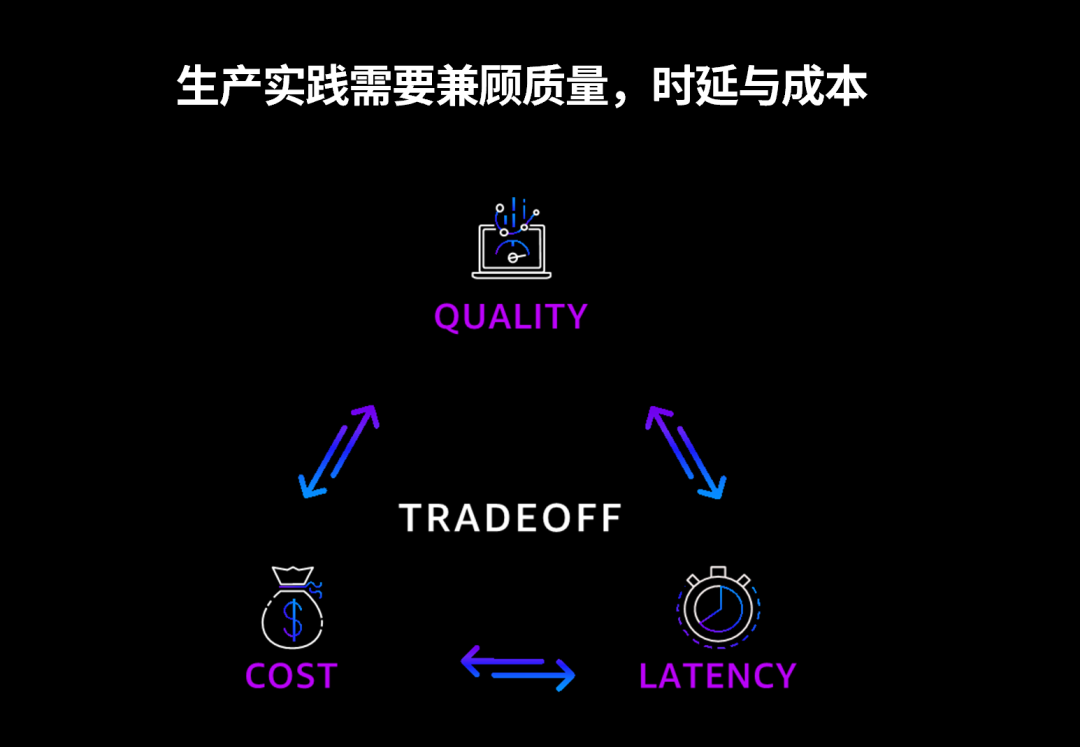
质量、时延和成本的不可能三角
这也是为什么亚马逊云科技会推出 Amazon Bedrock 这款产品,我们致力于给大家提供广泛的有头部能力的模型选择。

大家可以看到,今年我们陆续更新了 Claude 3.0、Mistral、Llama 3 等模型。6 月 21 日,Claude 3.5 Sonnet 也刚刚上线了亚马逊科技的 Amazon Bedrock,它比 Claude 3 拥有更智能的能力,但价格只有 1/5。模型的迭代在我们看来是非常快的,Claude 3 上线三个月不到,我们就又上线了 Claude 3.5 这个模型。
而且,针对开发者,亚马逊云科技打造了「云上探索实验室」,可以免费体验测试 Amazon Bedrock 上多个最新领先的基础模型。
Amazon Bedrock 是我们提供给大家广泛选择模型的一个平台,在海外大家都可以去访问到 Claude 3 或者其他的模型。但我们也看到很多企业客户,不希望用 AI SaaS 的服务,他们更希望把模型 host 在自己的私有化部署环境里。
这对这些需求,我们也提供了 SageMaker JumpStart,会把模型跟自己的 AIML 的 IDE 进行整合。可以通过 SageMaker JumpStart 把科研界、学术界、工业界各种各样的模型(包括 Hugging Face 上面的模型)集成到 JumpStart 上面,让大家可以做本地化的 hosting。

零一万物的若干模型,以及百川智能的模型也都已经上架了中国区的 SageMaker JumpStart。

有这么多模型可以选择,所以模型的 evaluation 是非常重要的能力,我们需要能随时比较「对于我的 use case,在我的应用场景下,什么模型是最适合我的」。
所以我们还提供了评估能力,同时还支持客户模型导入。大家可以在比较线上的模型之外,把自己基于开源架构微调的模型进行导入,之后再通过 Bedrock API 为客户提供服务。
我们的先锋案例库的客户 WPS,他们在海外是通过 Amazon Bedrock 上 Claude 的能力给上亿客户提供服务,包括对于拼写语法进行 spell check,以及润色等功能。
当一个场景可以快速落地的时候,亚马逊云科技可以提供优秀的模型能力,帮助场景快速实施。
03 选好模型只是创业第一步
真正要把一个生成 AI 的应用完成落地和部署,只靠模型远远不够。
大多数的业务,我们都是调用已经存在的模型,但是这个模型大家都可以用,不是自己最重要的差异点。目前,我们的差异化往往来自于自己的数据,当你的数据足够好,有足够强的数据处理能力,能够更快的把数据连接到 AI 模型或是进行 AI 输出的时候,相对来说,会在市场上具备更强的差异化竞争能力。
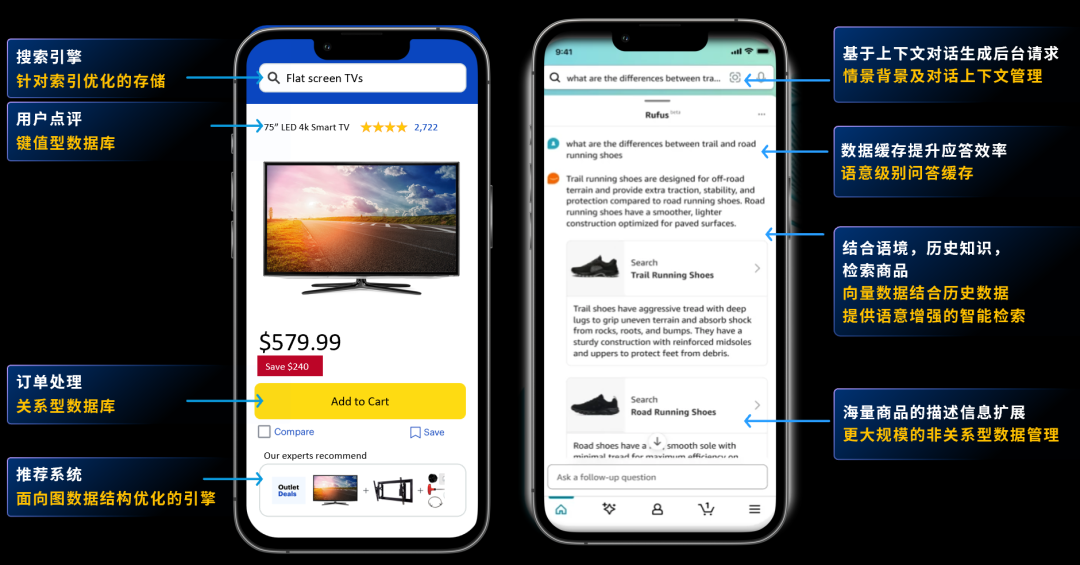
比如说,这张图是亚马逊的购物助手 Rufus,它可以通过自然语言的能力给客户提供购买建议。大家也可以从图中看到,有多少点能够连接到自己的数据处理与管理服务。
做一个搜索引擎,在搜索上面可能会涉及到整个对标签的检索;为了保证搜索的准确度,我们也会加一个 buffer(缓冲区),会加一个 cache(储存器);这里面会涉及到键值 (Key-Value) 存储数据库,我们的评论会在里面,所有的交易都会存在一个关系型数据库里。
所以,如果我们真的要 build 一个有客户体验、有客户交互的应用,只靠模型本身是完成不了大规模应用部署的。
这也是为什么亚马逊云科技会搭一个完整的 Data&AI 的 flow。它会在每一个具体的 AI、user experience 和 data 的 linkage 之间构建数据分析服务和数据库服务。
04 如何解决 AI 应用的实时交互难题
有一个非常好的数据存储和数据分析服务之后,怎么满足实时性?现在会有越来越多的应用进行实时的交互。
我们现在很多时候在 build 前端的,尤其是一些可穿戴设备的时候,会思考它怎么在用户无感知的情况下收集周围信息,并且它需要在一个贴近用户本身需求的场景里做一个载体,或者做一个什么样子的 AI model。
对于这件事情,亚马逊云科技的回答是:「我们会做一个 Zero-ETL(Extract Transform Load,数据的抽取转换加载)的未来。」

未来我们会 build 一个所有数据的 flow 的时候,会不再需要一个 hard coded 的 ETL 的代码和流程。我们希望把一些 heavy lifting 的,复杂的 ETL 工作做到无感知的数据流动。
数据拿过来之后,最后的落地还有很多工程化的工作。比如,我们要把所有的 data flow 跟客户已经存在的数据管理的系统链接起来,我们要把数据的访问权限管理起来等等。这些都是我们工程化工作的一部分。
有三个例子,介绍亚马逊云科技怎么帮助我们客户做到这一点的。
首先是西门子。西门子上线了一个内部 IT 和 HR 的问答系统,系统后面有非常多的数据访问,涉及到历史政策,历史文档,产品说明书等,实际上通过向量化,向量数据库,向量存储以及 RAG 方案,提供一些 sample code 给到客户。然后由西门子的开发团队自己搭建起来,把它付诸上线。它已经服务于内部大概四五千人的规模,现在在向西门子全国各个工厂做下一步的延伸。
德比软件,每到月末的时候,业务团队有大量口语化的 BI 查询需求,BI 查询现在有非常多 text2SQL 能力。但是在这家这个场景里,Prompt Engineering 加 text2SQL,暂时没办法完整地达到客户对 BI 或者 Generative BI 的要求。
那这件事情在工程化怎么实现?我们把常用的问题,以及对应的查询导入向量数据库。对于新的查询,用 vector database 去搜索最近的解,再通过 prompt engineering 做一个最优的反馈回来,实际上有非常多的工作化落地的方式,没办法通过一个技术完整的完成,而是通过后面很多的 workaround 一起做实施。
对于某制造型企业,有超过 21 万份的产品说明书,多达几千的 SKU,多语言。我们在帮企业客户落地的时候,非常依赖自己的合作伙伴。这个 Case 我们用的是鸿翼,为其提供一个产品化能力的实现。
AI 应用落地的最后三公里,从一个 typical use case 落地,再到落地 10 个,100 个,很多客户都在说要把已有的 use case 用生成式 AI 做重构,这需要企业有一个专业化团队来完成,通过第一个,第二个、第三个项目做 On Project Training,把这个团队训练起来,尽可能完成所有的 genAI 的重构。
05 负责任的 AI 应该怎么做?
最后一点,我想跟各位分享的是 Responsible AI——负责任的人工智能。
大家现在非常关心用生成式 AI 来做什么?做什么样的创新 use case?刚才也提到企业客户用生成式 AI 重写已经存在的 workflow。但是生成式 AI 赋能生产落地的时候,会带来很多我们之前没有预知到的风险。
亚马逊云科技最高的标准就是要做负责任的人工智能。我们分成 6 个点:公正性,可解释性,稳健性,隐私安全和治理,透明。亚马逊云科技在给客户提供服务的时候,会说 Security 是我们的 Job-Zero,是首先要保证的。

针对 LLM,OWASP(开放式 Web 应用程序安全项目)提出了 10 个潜在的安全风险。

比如,聊天对话的场景,要保证输出要符合核心价值观;查询问答场景,要保证个人信息不会被泄露;在做严肃讨论的时候,法律等等,得保证给的回答不能是错误的,你可以告诉我不知道。出海的话,很多问答场景对于种族、对于性别、对于年龄不可以有偏见。这些是在模型本身准确记录率之外需要关注的点。
此外,我们自己不会用客户任何的数据做训练,且一直在践行这种承诺。如果我们客户需要做微调的模型,数据会在一个私有化环境里,不会暴露到外网。
Amazon Bedrock 还会支持已经存在的国际化标准,出海的话,医疗要满足 HIPPA,欧洲有 GDPR,欧盟还在对 GenAI 有一个额外的法律法规出台,亚马逊云科技非常紧跟对应的监管要求。
我们专门 build 了一个 Bedrock 上面的工具,确保用户与应用之间的交互是安全,合规,可控的。Amazon Bedrock Guardrails 是目前主流的云厂商里面提供的唯一的解决方案,可帮助客户阻止多达 85% 的有害内容。

大家用 Guardrails,可以用自动化的方式去做,可以预设需要它达到一个什么样的安全合规标准。也可以带入自己的实际需求,通过 Guardrails 和人工双向解决这样的问题。实际上当我们把一个产品落地的时候,要解决一个具体的安全合规和有标准监控的时候,Guardrails 这样的工具可以帮助大家非常快的实现这一点。
06 现在是成为创业者的绝佳时机
当我们拥抱生成式 AI 技术时,往往面对三个大的挑战:底层算力的资源短缺,缺乏一个部署和访问一流模型的构建工具,以及开箱即用快速上手的应用。我们深知客户的这些痛点,并一直在努力,让生成式 AI 普惠化。
为此,亚马逊云科技推出了生成式 AI 技术栈,底层以 GPU 和自研芯片为代表,用于基础模型训练以及在生产环境中运行推理;中间层以 Amazon Bedrock 为代表,提供各种基础模型和工具。顶层则是以 Amazon Q 为代表,提供开箱即用的生成式 AI 应用程序,用户无需任何专业知识即可快速上手。

开发者做创新,做一个新的 workflow,往往是在它的最上层应用层。但你在搭应用时,往下有我们的 framework,infrastructure,亚马逊云科技有非常多的能力支撑大家 build 一个非常出圈的应用。
我们没有赶上工业革命,很多年轻创业者甚至没有经历上一代 PC 和互联网,但是今天,我们所有人,都有幸处在下一个技术变革的伟大时代,大家可以去 build 自己的 magic。
*头图来源:极客公园
本文为极客公园原创文章,转载请联系极客君微信 geekparkGO



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











