




来源:华映资本

选择大于努力。
成年人平均每天要做35,000个决策,大到买房买车,小到衣食住行阅读等,毋庸讳言,其中有一部分决策是错误的。如何改善我们决策的质量?诺贝尔经济学奖得主Daniel Kahneman通过在经典著作《快思慢想》中对思维世界的严谨描述,为我们提供了一些科学的方法论。
《快思慢想》出版已十年有余,在全球范围内广受欢迎,一直被视为深度剖析大脑思考运作的“思考圣经”。在AI快速发展迭代的当下再读《快思慢想》,我们发现本轮AI的主角——大语言模型LLM,与书中所提到的人类思考系统的工作机制高度契合,这为AI的未来发展方向提供了深刻洞察。
本期《华映新知》,华映被投企业金柚网CTO邬学宁将带我们从LLM的视角出发,探索如何通过《快思慢想》(“Think,Fast and slow”,不推荐简中版《思考快与慢》,其翻译令人困惑,读者可选择其他版本)中对思考系统的描述,来寻找“可信AI”。


系统1与系统2:思维的双速引擎
我们的大脑有两个系统,对应快思考的系统1和慢思考的系统2。系统1基于本能和过去的经验、直觉运行,快速而没有痛苦,比如,大家在一秒之内就能判读出照片中女生愤怒的表情;慢思考的系统2从事逻辑分析、反思和解决复杂问题等比较耗精力的任务,比如计算43X27。系统1生成直觉、想法和印象,并在必要时调用系统2,系统2负责自我控制,抑制系统1的冲动。
 来源:由GPT-4o生成
来源:由GPT-4o生成作者认为,大脑遵从“最省力原则”,即选择阻力最小最轻松的路径来进行思考,这也是我们在疲劳和有压力的时候,很难深入思考的原因。
从一个简单而知名的例题来观察系统1和2是如何工作的,一个球和球拍的总价格是1.1元,球拍比球的价格高1元,问两者的价格分别是多少?
系统1: 球拍1元,球0.1元
系统2: 假设球的价格是x元,那么球拍的价格为x+1元,两者和为1.1,解方程式可得 2x+1=1.1,x=0.05元。
系统1直觉地想让你按“1.1-1”计算,又感觉可能哪里有点不对,因此调用系统2来进行逻辑思考纠正偏差。


大语言模型:预训练与生成的智慧
所有的语言模型(Language Model),包括大语言模型LLM,其本质都是完成一个非常简单的任务:基于已有的文字,预测下一个词。只不过以前采用的是统计的方法,现在是基于神经网络。在已知前半句话的情况下,预测下一个词,这其实与系统1的本能直觉是类似的,只是现在GPT(Generative Pretrained Transformer)们已臻高精准度,今天各种复杂的(下游)任务都是基于这个预训练(pretrained)的生成(generate)模型。生成模型的工作机制分为两步:
(1)学习数据分布。GPT通过训练,将全世界的知识压缩到万亿神经网络参数中(参数量:GPT3达1750亿,GPT4估计约100万亿);
(2)生成。即基于上一步学习到的数据分布进行采样,生成新的数据。生成的过程则非常类似于系统1的直觉,毫不费力,快速而准确。
机器学习的模型使用分为训练和推理两个阶段,训练模型的过程类似于我们人类学习的过程比较费力,而推理阶段,只是使用训练好的模型参数进行计算,时间更短,有点类似于人的直觉。GPT使用了混合专家(Mixture of Experts, MoEs)模型,在相同模型参数量的情况下,8个专家会诊决策,进一步提升了表现,和本书的关系不太大,先不赘述。
其实预训练的方法,上一个十年被广泛使用了,但是彼时预训练的数据量和模型都太小(这是以目前的眼光来看,当时看也很大了),可类比对仅接受基础教育的小学毕业生便进行了专业训练;目前的大语言模型的思路是收集几乎所有人类的高质量数据进行训练,相当于通识教育至本科毕业的跨越,再进行专业训练,迈向博士级深造。如此一来,不同的领域之间的知识相关联,甚至不同模态(如图像和文字)之间的数据相关联的价值都被发掘出来。
最新的研究表明(2024年5月),对于同一个现实概念Z,可以被投影到图像X和文字Y两种不同模态。基于这两种不同的数据和模态训练的深度学习神经网络,在它们的表示空间(representation spaces)中,收敛为一个共享的现实统计模型,被称为柏拉图表示假设(The Platonic Representation Hypothesis)。这里借用了大家熟悉的柏拉图山洞火光哲学故事的寓意。
再进一步,我们的大脑也是多模态的,眼耳鼻舌身意,大脑皮层分别进行处理,最终融合,这很可能是大模型未来的重要发展方向,GPT-4v等最新的大模型中都已出现了雏形。
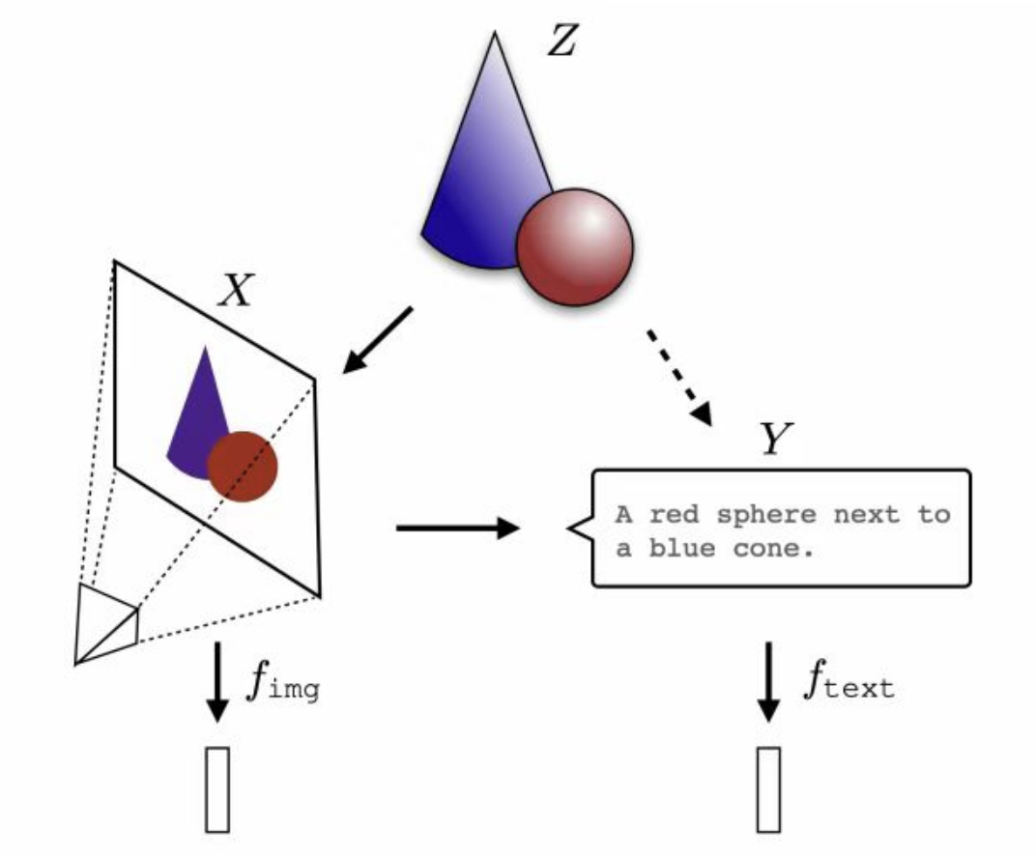 来源:https://arxiv.org/pdf/2405.07987
来源:https://arxiv.org/pdf/2405.07987
来源:2022年谷歌大脑论文《Chain-of-Thought Prompting Elicits Reasoning in Large Language Models》
完全依赖直觉可能会犯错,大语言模型有时也会产生幻觉。目前的大语言模型在逻辑思考方面尚显不足,比较接近的功能是思维链(Chain of Thoughts, CoT),对于复杂的问题,用户如果在提示词中加入“请一步步思考”,大模型的错误回答会减少,这在某种程度上类似于系统2对系统1的决策优化。
不过,幻觉的问题暂时还无法彻底解决,这是“可信AI”的研究重点,系统2可能为可信AI提供了重要的灵感, 但可能仍需基于因果的逻辑推理, 这里顺便推荐另一本书,图灵奖得主Judea Pearl的 《为什么》, 阐述了一种研究新因果关系的科学。
大语言模型产生幻觉的原因之一是在模型训练的过程中的数据质量问题所致,用户的问题缺少高质量的数据支持,大模型“一本正经的胡说八道”的概率就会上升,解决之道在于收集全面的高质量数据。对我们的大脑来说,要培养优秀的系统1,同样需要高质量的输入,避免“garbage in,garbage out”的情况发生。我们把注意力放在哪里,就收获什么,阅读《快思慢想》这种经典,能提升认知,慢慢读,反复读,让其进入您的潜意识,在需要的时候,您的系统1就能瞬间进行高质量的输出。
GPT的T表示Transformer,一个以注意力为核心的架构,类似于人类的注意力机制,模型在阅读文本或处理图像时,对不同的部分给予不同的关注度。而我们人类的注意力被很多厂商所瓜分,产品经理们使用心理学知识,比如不确定的回报让用户沉迷和上瘾,10亿用户每天刷150分钟短视频,人们的注意力被破坏,阅读长一点的文章都很困难,长此以往,大脑缺乏有营养的输入,系统1自然也难以给出高质量的输出。
本书中也提到,一个领域真正的大师往往依赖直觉判断,比如经验丰富的医生基于病人的症状快速诊断疾病,同时保持适度的警觉,避免主观的过于自信。过于自信,接近于自大和傲慢,《三体》里有句话,深以为然:弱小和无知,不是生存的障碍,傲慢才是。
在企业管理过程中,管理者并不都永远正确,因此,一方面管理者需要系统2的深思熟虑来帮助系统1做更优的决策,另一方面,塑造平等沟通的企业文化,让员工也能从不同的角度贡献自己的想法,是减少系统1决策失误的重要途径。

认知偏差严重影响决策的正误
认知偏差会严重影响正确的决策,比如锚点和可用性。
两个锚点的例子:
在星巴克情境下,消费者习惯于咖啡标价 30元左右,相比之下,店内22元依云矿泉水,消费者也不会感觉多贵,但实际上每瓶依云的市场价只有5元左右。
在谈判过程中,不论是买方还是卖方,都应该首先出价,卖方出个离谱的高价,买方出个离谱的低价,都是对自己有利的,这不是不诚心交易,而是设定锚点,使得后面的谈判对自己更有利。因此,永远不要接受第一次报价,甚至在初次报价基础上进行还价都是错的,因为你已经被对手种了“心锚”,跟着对方的节奏走了。
可用性的例子:
实验中,随机分组的两组人分别写下12个和6个行事果断的例子,写完之后问他们是否觉得自己是一个有决断性的人。一般前几个例子大家很快能想到,越到后面越难想出来,对于绞尽脑汁想出12个例子的人来说,写完之后,对自己的决断性评分的均值要低于6个例子的那一组,因为他们想到/提取这些例子不顺畅,提取数据的顺畅度/可用性甚至超越数据本身的价值。我们大脑倾向于使用易得的数据进行决策,而这些数据可能与实际的情况存在较大不一致,大脑也很容易忽略。
损失厌恶:
人们丢失100元的不悦远超过意外获得100元的喜悦,即便理性上认识到这不过是得而复失,情感上还是觉得难受。这被查理·芒格统称为被剥夺超级反应倾向。
类似的容易让人引起误判的情况还有很多,比如过度自信、回归均值、计划谬误等。
受篇幅所限,无法一一列出书中所有的思维陷阱,总的来说,本书的核心观点可概括为三个差异:
(1)自动化/快速思考的系统1与深思熟虑且费力的系统2之间的差异;
(2)经典经济学和行为经济学中代理人(Agent)概念的差异,作者就是因此(行为经济学)得诺奖,在行为经济学中,代理人都是理性的前提并不成立,而这却是经典经济学的前提之一;
(3)经验自我和记忆自我的差异。
从AI的角度,目前的大语言模型和系统1的行为方式很相似,也具有初步的系统2的能力,如何加强和发展系统2的能力,可预见将成为大语言模型未来的发展方向,也是通向通用人工智能(AGI)的发展方向。也许有一天,会进化到如Deepmind创始人Demis Hassabis预言的:在每个领域,都出现了各自的“AlphaGo”,不断推动各个领域向前发展。OpenAI创始人Sam Alterman在很多问题上也有类似的想法。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











