







【TechWeb】5月14日消息,今日凌晨,OpenAI正式发布了新一代的旗舰模型GPT-4o,可以利用语音、视频和文本信息进行实时推理。
据介绍,GPT-4o在英文文本和代码中的表现与GPT-4 Turbo相当,但在非英文文本上的能力大幅提升,在视频和音频的理解上,GPT-4o要明显强于当前的其他模型。
此外,能力更全面的GPT-4o,响应速度也更快,最快232毫秒响应音频输入,平均响应时间为320毫秒,与人类在对话中的响应速度相当。

除了更强、更全面的能力,OpenAI也在推动GPT-4o更广泛的应用。GPT-4o的文本和图片功能自推出之日起就向ChatGPT推送,ChatGPT用户可免费使用,ChatGPT Plus用户的数据量上限将是免费用户的5倍,新版本的音频模式将在未来几周向ChatGPT Plus用户推送。
TechWeb记者第一时间对GPT-4o进行了实测,不过目前免费用户还不能使用图片生成功能。我们使用GPT-4o来描述图片,并让其分别对一张中文图表和一张英文图表进行了分析,来看看结果。
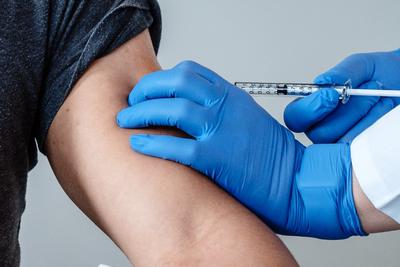
我们首先让GPT-4o描述了一张图片,发现描述的非常准确,并可以对单独人物的动作进行描述,最后还可以用文字来分析该图片场景。
随后是一张中文图表,不但可以读懂上面的数字含义,还可以对差异和趋势进行非常详细的分析。
最后是一张英文图表,GPT-4o可以读懂并翻译图表展示的数据内容,最后根据图表数据总结得出分析结论。
总体来说,GPT-4o的能力的确有了很大的提升,未来在所有功能开放的时候,TechWeb也将继续为大家带来更详细的实测体验。(萧健)



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)










官方微博






公众号

新浪科技
新浪科技为你带来最新鲜的科技资讯

苹果汇
苹果汇为你带来最新鲜的苹果产品新闻

新浪众测
新酷产品第一时间免费试玩

新浪探索
提供最新的科学家新闻,精彩的震撼图片

