




在视频理解这一领域,尽管多模态模型在短视频分析上取得了突破性进展,展现出了较强的理解能力,但当它们面对电影级别的长视频时,却显得力不从心。因而,长视频的分析与理解,特别是对于长达数小时电影内容的理解,成为了当前的一个巨大挑战。
究其原因,导致模型理解长视频困难的一个主要原因是缺乏高质量、多样化的长视频数据资源,而且收集和注释这些数据需要庞大的工作量。
面对这样的难题, 腾讯和复旦大学的研究团队提出了 MovieLLM,一个创新性的 AI 生成框架。MovieLLM 采用了创新性的方法,不仅可以生成高质量、多样化的视频数据,而且能自动生成大量与之相关的问答数据集,极大地丰富了数据的维度和深度,同时整个自动化的过程也极大地减少了人力的投入。

论文地址:https://arxiv.org/abs/2403.01422
主页地址:https://deaddawn.github.io/MovieLLM/
这一突破性的进展不仅提高了模型对复杂视频叙事的理解能力,还增强了模型针对长达数小时电影内容的分析能力,克服了现有数据集在稀缺性和偏差方面的限制,为超长视频的理解提供了一条全新而有效的思路。
MovieLLM 巧妙地结合了 GPT-4 与扩散模型强大的生成能力,应用了一种「story expanding」连续帧描述生成策略,并通过「textual inversion」来引导扩散模型生成场景一致的图片来构造出一部完整电影的连续帧。

方法概述
MovieLLM 巧妙地结合了 GPT-4 与扩散模型强大的生成能力,构造了高质量、多样性的长视频数据与 QA 问答来帮助增强大模型对长视频的理解。
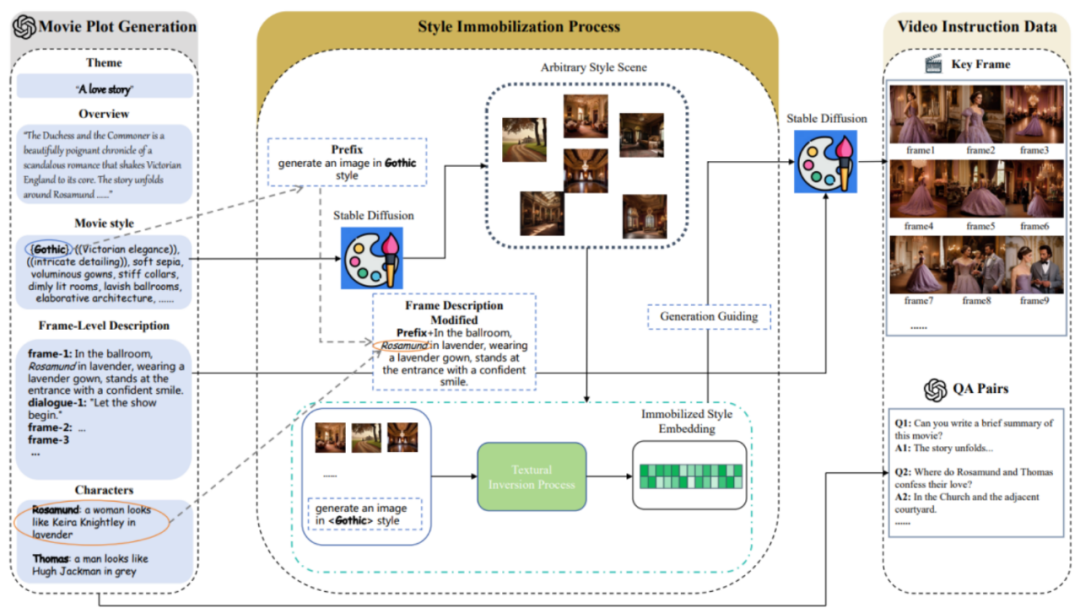
MovieLLM 主要包括三个阶段:
1. 电影情节生成。
MovieLLM 不依赖于网络或现有数据集来生成情节,而是充分利用 GPT-4 的能力来产生合成数据。通过提供特定的元素,如主题、概述和风格,引导 GPT-4 产生针对后续生成过程量身定制的电影级关键帧描述。
2. 风格固定过程。
MovieLLM 巧妙地使用「textual inversion」技术,将剧本中生成的风格描述固定到扩散模型的潜在空间上。这种方法指导模型在保持统一美学的同时,生成具有固定风格的场景,并保持多样性。
3. 视频指令数据生成。
在前两步的基础上,已经获得了固定的风格嵌入和关键帧描述。基于这些,MovieLLM 利用风格嵌入指导扩散模型生成符合关键帧描述的关键帧并根据电影情节逐步生成各种指令性问答对。

经过上述步骤,MovieLLM 就创建了高质量、风格多样的、连贯的电影连续帧以及对应的问答对数据。电影数据种类的详细分布如下:

实验结果
通过在 LLaMA-VID 这一专注于长视频理解的大模型上应用基于 MovieLLM 构造的数据进行微调,本文显著增强了模型处理各种长度视频内容的理解能力。而针对于长视频理解,当前并没有工作提出测试基准,因此本文还提出了一个测试长视频理解能力的基准。
虽然 MovieLLM 并没有特别地去构造短视频数据进行训练,但通过训练,仍然观察到了在各类短视频基准上的性能提升,结果如下:
在 MSVD-QA 与 MSRVTT-QA 这两个测试数据集上相较于 baseline 模型,有显著提升。

在基于视频生成的性能基准上,在五个测评方面都获得了性能提升。

在长视频理解方面,通过 MovieLLM 的训练,模型在概括、剧情以及时序三个方面的理解都有显著提升。

此外,MovieLLM 相较于其他类似的可固定风格生成图片的方法,在生成质量上也有着较好的结果。

总之,MovieLLM 所提出的数据生成工作流程显著降低了为模型生产电影级视频数据的挑战难度,提高了生成内容的控制性和多样性。同时,MovieLLM 显著增强了多模态模型对于电影级长视频的理解能力,为其他领域采纳类似的数据生成方法提供了宝贵的参考。
对此研究感兴趣的读者可以阅读论文原文,了解更多研究内容。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











