




生成式模型进入「实时」时代?
文生图、图生图已经不是什么新鲜事。但在使用这些工具的过程中,我们发现它们通常运行缓慢,导致我们要等一段时间才能拿到生成结果。
但最近,一种名叫「LCM」的模型改变了这种情况,它甚至能做到实时的连续生图。
 图源:https://twitter.com/javilopen/status/1724398666889224590
图源:https://twitter.com/javilopen/status/1724398666889224590LCM 的全称是 Latent Consistency Models(潜在一致性模型),由清华大学交叉信息研究院的研究者们构建。在这个模型发布之前,Stable Diffusion 等潜在扩散模型(LDM)由于迭代采样过程计算量大,生成速度非常缓慢。通过一些创新性的方法,LCM 只用少数的几步推理就能生成高分辨率图像。据统计,LCM 能将主流文生图模型的效率提高 5-10 倍,所以能呈现出实时的效果。

论文链接:https://arxiv.org/pdf/2310.04378.pdf
项目地址:https://github.com/luosiallen/latent-consistency-model
该文章发布一个月内浏览量超百万,作者也被邀请在 Hugging Face、Replicate、浦源等多个平台部署新研发的 LCM 模型和 demo。其中 Hugging Face 平台上 LCM 模型下载量已超 20 万次,而在 Replicate 中在线 API 调用已超 54 万次。
在此基础上,研究团队进一步提出 LCM-LoRA,可以将 LCM 的快速采样能力在未经任何额外训练的情况下迁移到其他 LoRA 模型上,为开源社区已经存在的大量不同画风的模型提供了一个直接而有效的解决方案。

技术报告链接:https://arxiv.org/pdf/2311.05556.pdf
潜在一致性模型的快速生成能力为图像生成技术开辟了新的应用领域。这种模型可以快速地根据输入的文本(Prompt)处理和渲染实时捕捉到的画面,从而实现高速图像生成。这意味着用户可以自定义他们想要展示的场景或视觉效果。
在 X 平台上,不少研究者也晒出了他们利用该模型实现的生成效果,包括图生图、视频生成、图像编辑、实时视频渲染等各类应用。
 图源:https://twitter.com/javilopen/status/1724398666889224590
图源:https://twitter.com/javilopen/status/1724398666889224590 图源:https://twitter.com/javilopen/status/1724398708052414748
图源:https://twitter.com/javilopen/status/1724398708052414748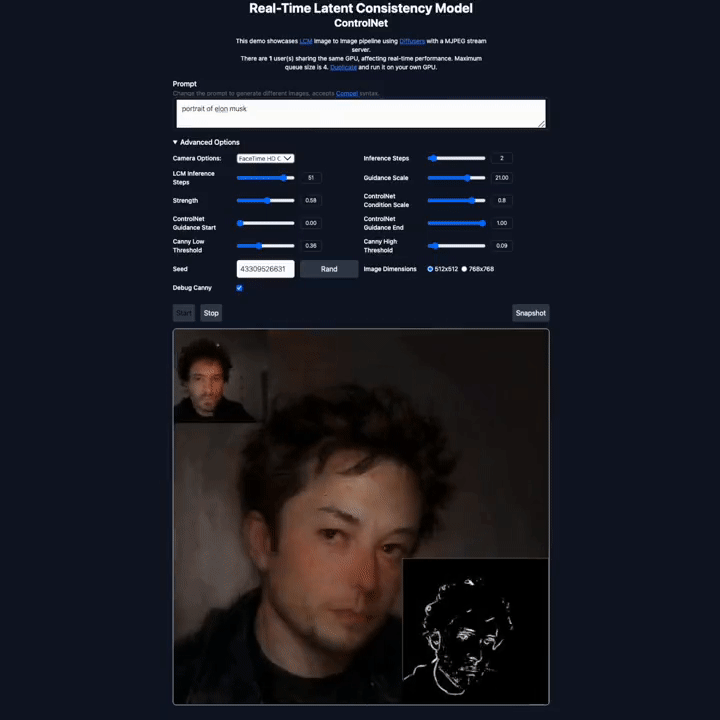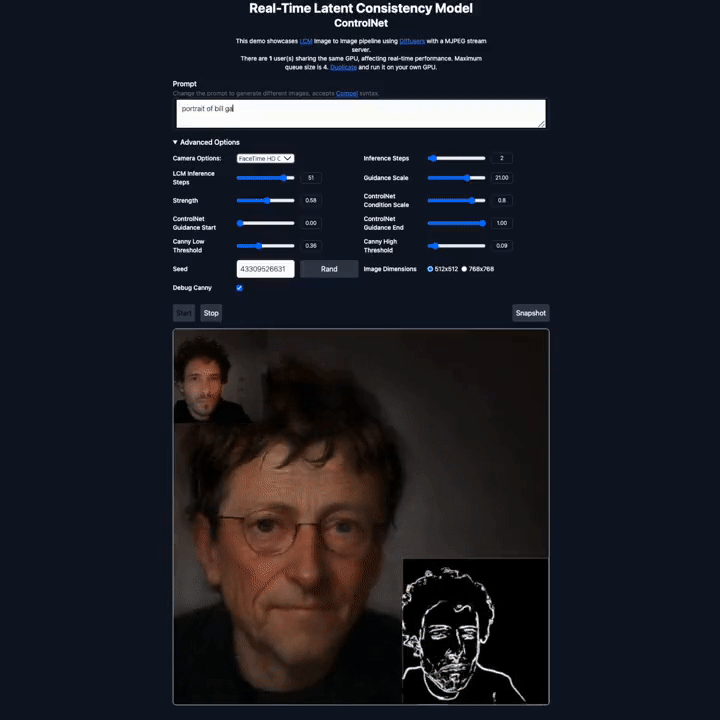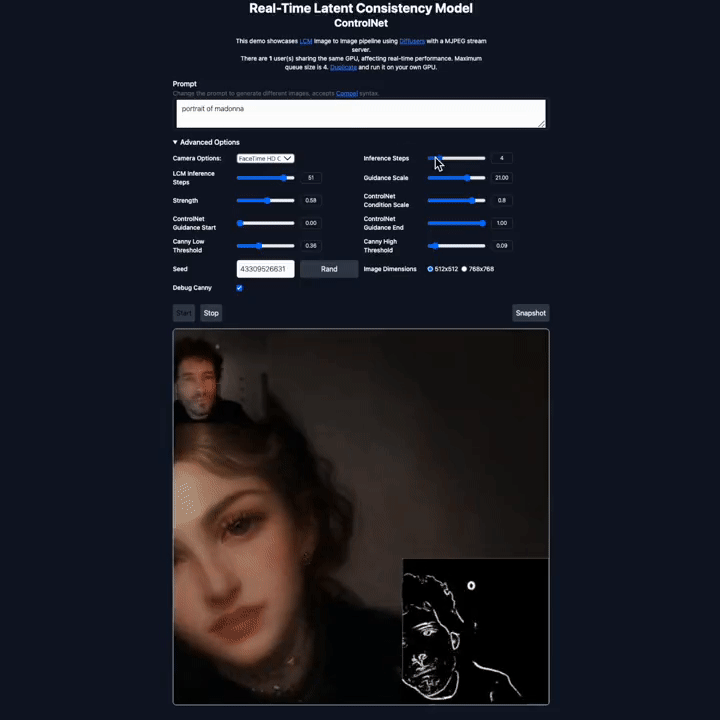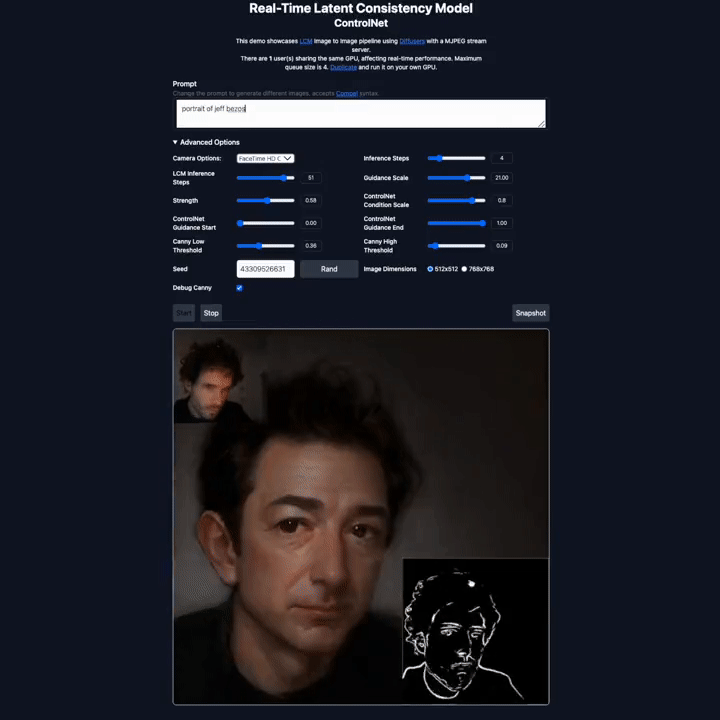
作者团队现已完全开源 LCM 的代码,并开放了基于 SD-v1.5、SDXL 等预训练模型在内蒸馏得到的模型权重文件和在线 demo。此外,Hugging Face 团队已经将潜在一致性模型集成进入 diffusers 官方仓库,并在两个接连的正式版本 v0.22.0 和 v0.23.0 中先后更新了 LCM 和 LCM-LoRA 的相关代码框架,提供了对潜在一致性模型的良好支持。在 Hugging Face 上开放的模型在今日的热度榜中达到全平台文生图模型热度第一,全类别模型热度第三。

接下来,我们将分别介绍 LCM 和 LCM-LoRA 这两项研究成果。
LCM:只用几步推理就能生成高分辨率图像
AIGC 时代,包括 Stable Diffusion 和 DALL-E 3 等基于扩散模型的文生图模型受到了广泛关注。扩散模型通过向训练数据添加噪声,然后逆转这一过程来生成高质量图像。然而,扩散模型生成图片需要进行多步采样,这一过程相对较慢,增加了推理成本。缓慢的多步采样问题是部署这类模型时的主要瓶颈。
OpenAI 的宋飏博士在今年提出的一致性模型(Consistency Model,CM)为解决上述问题提供了一个思路。一致性模型被指出在设计上具有单步生成的能力,展现出极大的加速扩散模型的生成的潜力。然而,由于一致性模型局限于无条件图片生成,导致包括文生图、图生图等在内的许多实际应用还难以享受这一模型的潜在优势。
潜在一致性模型(Latent Consistency Model,LCM)就是为解决上述问题而诞生的。潜在一致性模型支持给定条件的图像生成任务,并结合了潜在编码、无分类器引导等诸多在扩散模型中被广泛应用的技术,大大加速了条件去噪过程,为诸多具有实际应用意义的任务打开了一条通路。
LCM 技术细节
具体而言,潜在一致性模型将扩散模型的去噪问题解读为求解如下所示的增广概率流常微分方程的过程。
传统的扩散模型采用数值方法对常微分方程进行迭代求解,虽然可以通过设计更加精确的求解器来改善每一步的求解精度,减少所需要的迭代次数,但是这些方法中最好的也仍然需要 10 步左右的迭代步数来得到足够好的求解结果。
不同于迭代求解这一常微分方程,潜在一致性模型要求对常微分方程进行直接的单步求解,直接预测方程的最终解,从而在理论上能够在单步内生成图片。

为了训练得到潜在一致性模型,该研究指出可以通过对于预训练的扩散模型(例如,Stable Diffusion)进行参数微调,在极少的资源消耗下赋予模型快速生成的效果。这一蒸馏过程基于对宋飏博士提出的一致性损失函数的优化。为了在文生图任务上获得更好的表现并减少计算开销,本文提出了三点关键技术:
(1)使用预训练的自动编码器将原始图片编码到潜在空间,在压缩图片中冗余信息的同时让图片在语义上具有更好的一致性;
(2)将无分类器引导作为模型的一个输入参数蒸馏进潜在一致性模型中,在享受无分类器引导带来的更好的图片 - 文本的一致性的同时,由于无分类器引导幅度被作为输入参数蒸馏进了潜在一致性模型,从而能够减少推理时的所需要的计算开销;
(3)使用跳步策略来计算一致性损失,大大加快了潜在一致性模型的蒸馏过程。潜在一致性模型的蒸馏算法的伪代码见下图。

定性和定量化的结果展示了潜在一致性模型的快速生成能力,该模型能够在 1~4 步内生成高质量图片。通过比较实际的推理时间和生成质量指标 FID,可以看到,潜在一致性模型相比于现有的最快的采样器之一的 DPM solver++ 能够在保持同等生成质量的前提下实现约 4 倍的实际推理时间加速。

LCM 生成的图像
LCM-LORA: 一个通用的 Stable Diffusion 加速模块
在潜在一致性模型的基础上,作者团队随后进一步发布了他们关于 LCM-LoRA 的技术报告。由于潜在一致性模型的蒸馏过程可以被视作是对于原有的预训练模型的微调过程,从而可以使用 LoRA 等高效微调技术来训练潜在一致性模型。得益于 LoRA 技术带来的资源节省,作者团队在 Stable Diffusion 系列中参数量最大的 SDXL 模型上进行了蒸馏,成功得到了能够在极少步数内生成与 SDXL 数十步相媲美的潜在一致性模型。
在论文 INTRODUCTION 部分,该研究表示尽管潜在扩散模型(LDM)在文生图、线稿生图等方面取得了成功,但其固有的缓慢反向采样过程阻碍了实时应用,影响了用户体验。目前的开源模型和加速技术还无法在标准消费级 GPU 上实现实时生成。
加速 LDM 的方法一般分为两类:第一类涉及先进的 ODE 求解器,如 DDIM、DPMSolver 和 DPM-Solver++,以加快生成过程。第二类涉及蒸馏 LDM 以简化其功能。ODE - 求解器减少了推理步骤,但仍需要大量的计算开销,尤其是在采用无分类器指导时。同时,蒸馏方法(如 Guided-Distill)虽然前景广阔,但由于其密集的计算要求而面临实际限制。在 LDM 生成图像的速度和质量之间寻求平衡仍然是该领域的一项挑战。
最近,受一致性模型(Consistency Model,CM)的启发,潜在一致性模型(Latent Consistency Model,LCM)出现了,作为图像生成中缓慢采样问题的一种解决方案。LCM 将反向扩散过程视为增强概率流 ODE(PF-ODE)问题。这类模型创新性地预测了潜空间中的解,不需要通过数值 ODE 求解器进行迭代求解。因此,它们合成高分辨率图像的效率非常高,只需 1 到 4 个推理步骤。此外,LCM 在蒸馏效率方面也很突出,只需用 A100 个训练 32 个小时就能完成最小步骤的推理。
在此基础上,Latent Consistency Finetuning(LCF)被开发为一种无需从教师扩散模型开始就能对预训练 LCM 进行微调的方法。对于专业数据集,如动漫、真实照片或奇幻图像数据集,它还需要额外的步骤,如采用潜在一致性蒸馏法(LCD)将预训练的 LDM 蒸馏为 LCM,或直接使用 LCF 对 LCM 进行微调。然而,这种额外的训练可能会阻碍 LCM 在不同数据集上的快速部署,这就提出了一个关键问题:是否可以在自定义数据集上实现快速、无需训练的推理。
为了回答上述问题,研究者提出了 LCM-LoRA,它是一种通用的免训练加速模块,可以直接插入各种 Stable-Diffusion(SD)微调模型或 SD LoRA 中,以最少的步骤支持快速推理。与 DDIM、DPM-Solver 和 DPM-Solver++ 等早期数值概率流 ODE(PF-ODE)求解器相比,LCM-LoRA 代表了一类基于神经网络的新型 PF-ODE 求解器模块。它在各种微调的 SD 模型和 LoRA 中展示了强大的泛化能力。

LCM-LoRA 概况图。通过在 LCM 的蒸馏过程中引入 LoRA,该研究大大减少了蒸馏的内存开销,这使得他们能够利用有限的资源训练更大的模型,例如 SDXL 和 SSD-1B。更重要的是,通过 LCM-LoRA 训练获得的 LoRA 参数(acceleration vector)可以直接与在特定风格数据集上微调获得的其他 LoRA 参数(style vetcor)相结合。无需任何训练,通过 acceleration vector 和 style vetcor 的线性组合获得的模型就能以最少的采样步骤生成特定绘画风格的图像。
LCM-LoRA 技术细节
通常来讲,潜在一致性模型的训练采用单阶段指导蒸馏方式进行,这种方法利用预训练的自编码器潜在空间将指导扩散模型蒸馏为 LCM。此过程涉及增强概率流 ODE,我们可以将其理解为一种数学公式,这样一来可确保生成的样本遵循生成高质量图像的轨迹。
值得一提的是,蒸馏的重点是保持这些轨迹的保真度,同时显着减少所需的采样步骤数量。算法 1 提供了 LCD 的伪代码。

由于 LCM 的蒸馏过程是在预训练扩散模型的参数上进行的,因此我们可以将潜在一致性蒸馏视为扩散模型的微调过程,从而就可以采用一些高效的调参方法,如 LoRA。
LoRA 通过应用低秩分解来更新预训练的权重矩阵。具体而言,给定一个权重矩阵
,其更新方式表述为


h 代表输出向量,从公式(1)可以观察到,通过将完整参数矩阵分解为两个低秩矩阵的乘积,LoRA 显着减少了可训练参数的数量,从而降低了内存使用量。
下表将完整模型中的参数总数与使用 LoRA 技术时的可训练参数进行了比较。显然,通过在 LCM 蒸馏过程中结合 LoRA 技术,可训练参数的数量显着减少,有效降低了训练的内存需求。
 该研究通过一系列实验表明 :LCD 范式可以很好地适应更大的模型如 SDXL 、 SSD-1B ,不同模型的生成结果如图 2 所示。
该研究通过一系列实验表明 :LCD 范式可以很好地适应更大的模型如 SDXL 、 SSD-1B ,不同模型的生成结果如图 2 所示。
除了使用 LoRA 技术来让蒸馏过程更加高效,作者还发现了由此训练得到的 LoRA 参数可以被作为一种泛用的加速模块,直接与其他 LoRA 参数结合。
如上图 1 所示,作者团队发现,只需要将在特定风格数据集上微调得到的 “风格参数” 与经过潜在一致性蒸馏得到的 “加速参数” 进行简单的线性组合,就可以获得兼具快速生成能力和特定风格的全新潜在一致性模型。这一发现为现有开源社区内已存在的大量开源模型提供了极强的助力,使得这些模型甚至可以在无需任何额外训练的情况下享受潜在一致性模型带来的加速效果。
下图展示了使用这一方法改善 “剪纸画风” 模型后得到的新的模型的生成效果。

总之,LCM-LoRA 是一种用于 Stable-Diffusion (SD) 模型的通用免训练加速模块。其可以作为独立且高效的基于神经网络的求解器模块来预测 PF-ODE 的解,从而能够在各种微调的 SD 模型和 SD LoRA 上以最少的步骤进行快速推理。大量的文本到图像生成实验证明了 LCM-LoRA 强大的泛化能力和优越性。
团队介绍
论文作者成员全部来自清华叉院,两位共同一作分别是骆思勉,谭亦钦。
骆思勉是清华叉院二年级硕士,导师为赵行老师。本科毕业于复旦大学大数据学院。研究方向为多模态生成模型,研究兴趣为扩散模型,一致性模型,AIGC加速,致力于研发下一代生成模型。此前也以一作身份多篇论文发表在ICCV,NeurIPS顶会上。
谭亦钦是清华叉院二年级硕士,导师为黄隆波老师。本科毕业于清华大学电子工程系。研究方向包括深度强化学习、扩散模型。此前以一作身份在ICLR等会议上发表spotlight论文和口头报告。
值得一提的是,两位共一是在叉院李建老师的高等计算机理论课上,提出了LCM的想法,并最后作为期末课程项目进行了展示。三位指导老师中,李建和黄隆波是清华交叉信息院副教授,赵行是清华交叉信息院助理教授。

第一行(从左到右):骆思勉、谭亦钦。第二行(从左到右):黄隆波、李建、赵行。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











