炒股就看金麒麟分析师研报,权威,专业,及时,全面,助您挖掘潜力主题机会!
核心观点
ChatGPT:大模型下计算量高速扩张,算力需求陡增。1)以前,人工智能大多是针对特定场景应用进行训练,难以迁移,属于小模型范畴;而ChatGPT背后的支撑为人工智能大模型,可大幅扩充适用场景、提升研发效率。OpenAI GPT3自发布以来,在翻译、问答、内容生成等领域均有不俗表现,也吸引了海内外科技巨头纷纷推出超大模型、并持续加大投入。2)在大模型的框架下,每一代GPT模型的参数量均高速扩张,GPT-3参数量已达到1750亿个。我们认为,ChatGPT的快速渗透、落地应用,也将大幅提振算力需求。
访问算力:初始投入近十亿美元,单日电费数万美元。1)根据Similarweb的数据,2023年1月,平均每天约有1300万独立访客使用ChatGPT。访问阶段算力每天发生,其成本成为衡量ChatGPT最主要投入的关键指标。2)我们以英伟达A100芯片、DGX A100服务器、现阶段每日2500万访问量等假设为基础,估算得出:在初始算力投入上,为满足ChatGPT当前千万级用户的咨询量,投入成本约为8亿美元,对应约4000台服务器;在单日运行电费上,参考美国平均0.08美元/kwh工业电价,每日电费约为5万美元,成本相对高昂。
前期训练:公有云下,单次训练约为百万至千万美元。1)模型的前期训练成本也是讨论的重要议题。基于参数数量和token数量估算,GPT-3训练一次的成本约为140万美元;对于一些更大的LLM模型(如拥有2800亿参数的Gopher和拥有5400亿参数的PaLM),采用同样的计算公式,可得出,训练成本介于200万美元至1200万美元之间。2)我们认为,在公有云上,对于全球科技大企业而言,百万至千万美元级别的训练成本并不便宜,但尚在可接受范围内。
投资标的:1)服务器:浪潮信息(50.000, 0.19, 0.38%)、紫光股份(25.420, 0.23, 0.91%)、中科曙光(64.420, 0.44, 0.69%)等;2)芯片:景嘉微(91.760, 1.27, 1.40%)、寒武纪(592.000, -2.00, -0.34%)、海光信息(131.780, -1.03, -0.78%)等;3)IDC:宝信软件(27.640, -0.02, -0.07%)、万国数据、数据港(18.790, -0.05, -0.27%)、世纪华通(4.950, 0.08, 1.64%)等;4)光模块等。
风险提示:AI技术迭代不及预期风险、经济下行超预期风险、行业竞争加剧风险
报告正文
01
ChatGPT:大模型下计算量高速扩张,算力需求陡增
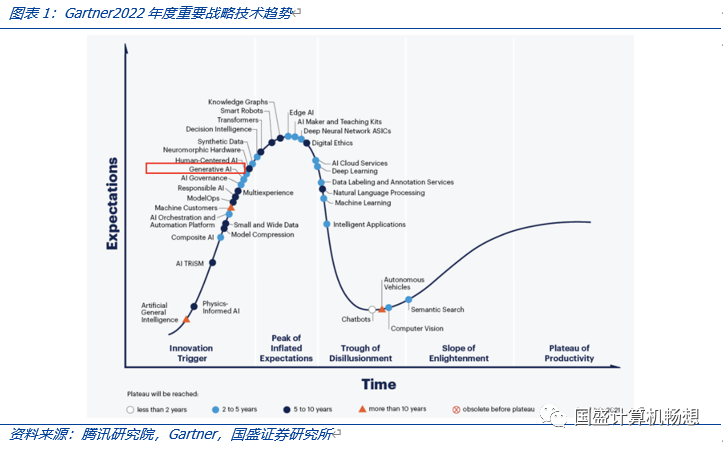
ChatGPT以大模型为基础,在翻译、问答、内容生成等领域表现不俗。1)ChatGPT是生成式AI的一种形式,Gartner将其作为《2022年度重要战略技术趋势》的第一位。2)根据腾讯研究院研究,当前的人工智能大多是针对特定的场景应用进行训练,生成的模型难以迁移到其他应用,属于“小模型”的范畴。整个过程不仅需要大量的手工调参,还需要给机器喂养海量的标注数据,这拉低了人工智能的研发效率,且成本较高。而ChatGPT背后的支撑是人工智能大模型。大模型通常是在无标注的大数据集上,采用自监督学习的方法进行训练。之后,在其他场景的应用中,开发者只需要对模型进行微调,或采用少量数据进行二次训练,就可以满足新应用场景的需要。这意味着,对大模型的改进可以让所有的下游小模型受益,大幅提升人工智能的适用场景和研发效率。3)因此大模型成为业界重点投入的方向,OpenAI、谷歌、脸书、微软,国内的百度、阿里、腾讯、华为和智源研究院等纷纷推出超大模型。特别是OpenAI GPT3大模型在翻译、问答、内容生成等领域的不俗表现,让业界看到了达成通用人工智能的希望。当前ChatGPT的版本为GPT3.5,是在GPT3之上的调优,能力进一步增强。
参数量、数据量高度扩张,算力需求陡增。在大模型的框架下,每一代GPT模型的参数量均高速扩张;同时,预训练的数据量需求亦快速提升。我们认为,ChatGPT的快速渗透、落地应用,也将大幅提振算力需求。

02
访问算力:初始投入近十亿美元,单日电费数万美元
Chatgpt月活过亿,访问量爆发式增长。根据Similarweb的数据,2023年1月,平均每天约有1300万独立访客使用ChatGPT,是2022年12月份的两倍多;累计用户超1亿,创下了互联网最快破亿应用的记录,超过了之前TikTok9个月破亿的速度。
访问阶段的算力每天发生,成为衡量ChatGPT投入的关键指标。
1)计算假设:
英伟达A100:根据OneFlow报道,目前,NVIDIA A100是AWS最具成本效益的GPU选择。
英伟达DGX A100服务器:单机搭载8片A100 GPU,AI算力性能约为5 PetaFLOP/s,单机最大功率约为6.5kw,售价约为19.9万美元/台。

标准机柜:19英寸、42U。单个DGX A100服务器尺寸约为6U,则标准机柜可放下约7个DGX A100服务器。则,单个标准机柜的成本为140万美元、56个A100GPU、算力性能为35 PetaFLOP/s、最大功率45.5kw。
2)芯片需求量:
每日咨询量:根据Similarweb数据,截至2023年1月底,chat.openai.com网站(即ChatGPT官网)在2023/1/27-2023/2/3这一周吸引的每日访客数量高达2500万。假设以目前的稳定状态,每日每用户提问约10个问题,则每日约有2.5亿次咨询量。
A100运行小时:假设每个问题平均30字,单个字在A100 GPU上约消耗350ms,则一天共需消耗729,167个A100 GPU运行小时。
A100需求量:对应每天需要729,167/24=30,382片英伟达A100 GPU同时计算,才可满足当前ChatGPT的访问量。
3)运行成本:
初始算力投入:以前述英伟达DGX A100为基础,需要30,382/8=3,798台服务器,对应3,798/7=542个机柜。则,为满足ChatGPT当前千万级用户的咨询量,初始算力投入成本约为542*140=7.59亿美元。
每月电费:用电量而言,542*45.5kw*24h=591,864kwh/日。参考Hashrate Index统计,我们假设美国平均工业电价约为0.08美元/kwh。则,每日电费约为591,864*0.08=4.7万美元/日。

03
前期训练:公有云下,单次训练约为百万至千万美元
模型的前期训练成本也是讨论的重要议题。根据估算,GPT-3训练成本约为140万美元;对于一些更大的LLM模型,训练成本约达到1120万美元。
1)基于参数数量和token数量,根据OneFlow估算,GPT-3训练一次的成本约为139.8万美元:
每个token的训练成本通常约为6N(而推理成本约为2N),其中N是LLM的参数数量;
假设在训练过程中,模型的FLOPS利用率为46.2%,与在TPU v4芯片上进行训练的PaLM模型(拥有5400亿参数)一致。

2)对于一些更大的LLM模型(如拥有2800亿参数的Gopher和拥有5400亿参数的PaLM),采用同样的计算公式,可得出,训练成本介于200万美元至1200万美元之间。

我们认为,在公有云上,对于以谷歌等全球科技大企业而言,百万至千万美元级别的训练成本并不便宜,但尚在可接受范围内、并非昂贵。
04
投资建议
1)服务器:浪潮信息、紫光股份、中科曙光等。
2)芯片:景嘉微、寒武纪、海光信息等。
3)IDC:宝信软件、万国数据、数据港、世纪华通等。
4)光模块等。
05
风险提示
AI技术迭代不及预期风险:若AI技术迭代不及预期,NLP技术理解人类意图水平未能取得突破,则对产业链相关公司会造成一定不利影响。
经济下行超预期风险:若宏观经济景气度下行,固定资产投资额放缓,影响企业再投资意愿,从而影响消费者消费意愿和产业链生产意愿,对整个行业将会造成不利影响,NLP技术应用落地将会受限。
行业竞争加剧风险:若相关企业加快技术迭代和应用布局,整体行业竞争程度加剧,将会对目前行业内企业的增长产生威胁。

具体分析详见2023年2月12日发布的报告《ChatGPT需要多少算力》
分析师 刘高畅 分析师执业编号S0680518090001
分析师 杨然 分析师执业编号S0680518050002
特别声明:《证券期货投资者适当性管理办法》于2017年7月1日起正式实施。通过微信形式制作的本资料仅面向国盛证券客户中的专业投资者。请勿对本资料进行任何形式的转发。若您非国盛证券客户中的专业投资者,为保证服务质量、控制投资风险,请取消关注,请勿订阅、接受或使用本资料中的任何信息。因本订阅号难以设置访问权限,若给您造成不便,烦请谅解!感谢您给予的理解和配合。
重要声明:本订阅号是国盛证券计算机团队设立的。本订阅号不是国盛计算机团队研究报告的发布平台。本订阅号所载的信息仅面向专业投资机构,仅供在新媒体背景下研究观点的及时交流。本订阅号所载的信息均摘编自国盛证券研究所已经发布的研究报告或者系对已发布报告的后续解读,若因对报告的摘编而产生歧义,应以报告发布当日的完整内容为准。本资料仅代表报告发布当日的判断,相关的分析意见及推测可在不发出通知的情形下做出更改,读者参考时还须及时跟踪后续最新的研究进展。
本资料不构成对具体证券在具体价位、具体时点、具体市场表现的判断或投资建议,不能够等同于指导具体投资的操作性意见,普通的个人投资者若使用本资料,有可能会因缺乏解读服务而对报告中的关键假设、评级、目标价等内容产生理解上的歧义,进而造成投资损失。因此个人投资者还须寻求专业投资顾问的指导。本资料仅供参考之用,接收人不应单纯依靠本资料的信息而取代自身的独立判断,应自主作出投资决策并自行承担投资风险。




















热门推荐
TikTok呼吁美政府“立即明确”不强制执行禁令:否则将于19日被迫“关闭” 收起TikTok呼吁美政府“立即明确”不强制执行禁令:否则将于19日被迫“关闭”
- 2025年01月18日
- 01:34
- APP专享
- 广西台新闻910
 55,015
55,015
呼和浩特市农牧局致歉:邀请“李维刚”直播带货期间,对经销商审核把关不到位
- 2025年01月17日
- 15:20
- APP专享
- 我是山河君
- 3,832
董明珠被停职审查?格力刚刚回应
- 2025年01月18日
- 07:22
- APP专享
- 我是山河君
- 2,691

24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)
投资研报 扫码订阅






投顾直播
-

海通证券.盈投顾2024-01-17 08:35:33
宏观要闻1、省部级主要领导干部推动金融高质量发展专题研讨班16日上午在中央党校(国家行政学院)开班。中共中央总书记、国家主席、中央军委主席习近平在开班式上发表重要讲话强调,坚定不移走中国特色金融发展之路,推动我国金融高质量发展。据了解,这是1999年以来、时隔25年后再次以金融为主题专题研讨。2、国务院国资委召开国有企业经济运行座谈会,推动中央企业做好提质增效开局起步工作,努力实现一季度“开门红”。国务院国资委党委书记、主任张玉卓强调,狠抓提升经营效益,切实改善预期、提振信心,更好发挥稳定器、压舱石作用。3、昨日沪指探底回升,下午2点以后,跟踪沪深300指数4只ETF成交量显著放大,护盘资金或又出动。截至昨日收盘,华泰柏瑞沪深300ETF、嘉实沪深300ETF、华夏沪深300ETF、易方达沪深300ETF成交额分别为59.25亿、36.43亿、40.67亿和47.17亿,该4只ETF昨日成交额分别为30.31亿、8亿、5.99亿和5.67亿,尤其是后三只ETF,成交额分别增4倍、6倍和8倍。行业新闻1、昨日一则消息称“上午同花顺大部分融资盘爆仓,并称某大户爆仓10亿遭强平,进而引发创业板崩盘“,对此,有媒体多方采访了解到,这一说法不合理,同花顺大跌有两个因素干扰:一是传言竞争对手有降价预期;二是悲观情绪引发补跌概率更大。2、从多位产业链人士处获悉,为了保证市场地位,宁德时代正在梳理产线资源,推动降本。“24年中旬有几家车企都会切换到这款产品,电芯价格不超过0.4元/Wh,加量不加价,目标就是10-20万元的纯电市场。”有行业知情人士透露。动力电池正在逐步进入0.3元/Wh时代。3、“工农中建交邮”六大国有行理财公司及招银、兴银、信银、光大、浦银理财共11家公司去年下半年规模净流入逾1.1万亿,大行理财公司较去年初仍有缺口。国有行理财公司方面,除交银理财外的其余5家大行理财公司存续规模较2023年初仍然差距约460亿至4000亿元的缺口,合计降幅仍将近9000亿元。4、比尔盖茨在达沃斯闭门演讲中表示,ChatGPT之后,AI可以读,也可以写。这是一个巨大的进步,对于白领工作者而言,可以处理很多日常的工作,很多大量的分析工作都可以瞬间完成,工作效率提升极大。在五年之内,会对生产力有一个极大的提升。5、针对昨日市场消息指平安银行将包括万科、保利、龙湖、金地等41家开发商列入可获融资支持名单,平安银行回应媒体称,去年12月召集房企开会,并推出相应举措。6、2024年春运将于1月26日拉开帷幕。从1月16日召开的国新办发布会上获悉,预计春运期间全国跨区域人员流动量将达到90亿人次,铁路、公路、水路、民航等营业性客运量将超18亿人次,高速公路及普通国省干线非营业性小客车人员出行量将近72亿人次,自驾出行占比将突破8成。7、2024年开年仅半个月,先后有正荣、旭辉、奥园、龙光等多家房企披露了境外债务重组方面的阶段性进展,包括重组方案获法院批准、与债权人小组签署支持协议、给出较为成熟的债务重组方案等,且皆达成了不同程度的削债规模,基本均在40%以上。业内预计,行业风险出清将加速。环球市场1、美股三大指数集体收跌,道指跌0.62%,纳指跌0.19%,标普500指数跌0.37%,热门中概股普跌,纳斯达克中国金龙指数跌3.81%。2、WTI原油期货跌1.06%,布伦特原油期货跌0.2%。3、COMEX黄金期货跌0.97%,COMEX 白银期货收跌1.01%。公司新闻1、普瑞眼科公告,预计2023年净利润同比增长1164%-1286%。2、海康威视公告,控股股东一致行动人电科投资拟继续增持3亿元-6亿元股份。3、扬电科技公告,股东赵恒龙拟减持不超过3%股份。4、锐科激光发布业绩预告,2023年净利预增389.32%-511.64%。5、金龙羽公告,实控人之一致行动人吴玉花拟减持不超过3%股份。6、乐华娱乐在港交所发布公告,公司经营正常,董事均未出售所持股份。7、宁夏建材公告,重组事项未通过上交所重组委审核。投资机会参考1、头部网红正式开启海外直播带货,跨境直播或成出海新风口近日,据抖音账号“Tiktok事业部(三只羊)”视频显示,小杨哥公司三只羊网络近日已开启海外带货布局,第一站为新加坡,带货模式为联合海外达人赋能直播带货,带货品牌多为中国本土品牌。有媒体就该事联系三只羊公司,三只羊回应该账号为公司官方账号,海外带货确已开启,且近日已完成在新加坡的海外直播,并逐渐开始在更多国家布局。随着国内短视频平台市场越来越饱和,很多网络红人和电商卖家开始寻求新的市场机遇,出海或成头部直播电商机构的新增长点。市场分析称,相比于中国,电商直播在海外市场似乎还是一片未完全开发的全新商业领域。根据ForesightResearch统计,2022年美国电商直播预计收入只有110亿美元,这与庞大的中国直播电商市场相比差距甚远。艾媒咨询分析师进一步分析指出,随着TikTok电商平台的迅速发展,各大平台也将发力跨境直播电商,中国跨境直播电商潮流势不可挡。预计2025年跨境直播电商市场规模将达到8287亿。2、氢能最具潜力的应用领域之一,这类产品落地商用加速推进据媒体报道,麻省理工大学(MIT)电动汽车团队近日探索推出了全新的氢基试验台,演示了氢动力电动摩托车原型,并开源相关代码,欢迎其他汽车开发人员测试交流,共同推进氢动力产品的研发。氢能可广泛应用于储能、发电、汽车、航空、冶金、建筑供热等领域。氢燃料电池车是最具潜力的应用领域之一。与电动汽车相比,燃料电池车能量密度高,加注燃料便捷、续航里程较高,更适用于长途、大型、商用车领域,可有效解决商用货车高续航要求、高污染排放等问题。燃料电池汽车规划明晰,产业发展有望提速。参考国家能源局、发改委联合发布的《氢能产业中长期规划(2021-2035年)》,2025年全国燃料电池汽车保有量需达到5万台,而根据国内20个氢能发展主要省市规划,2025年燃料电池汽车保有量将达10.88万台。市场分析认为,随着政策力度加3、先进封装+半导体设备+人工智能,龙头公司去年净利同比预增超50%北方华创公告,预计2023年归母净利36.10亿元-41.50亿元,同比增长53.44%-76.39%;扣非后归母净利润33亿元-38亿元,同比增长56.69%-80.43%。报告期内,公司2023年主营业务呈现良好发展态势,市场认可度不断提高,应用于高端集成电路领域的刻蚀、薄膜、清洗和炉管等数十种工艺装备实现技术突破和量产应用,工艺覆盖度及市场占有率均得到大幅提升;2023年公司新签订单超过300亿元,其中集成电路领域占比超70%。机构人士指出,公司产品矩阵持续扩张,平台化布局彰显公司竞争力。截至2023年5月,ICP刻蚀产品出货累计超过2000腔,8寸CCP刻蚀设备已批量供应,12寸CCP刻蚀设备已进入客户端验证,同时公司清洗、12寸去胶机等均取得进展。市场人士看好2024年中国本土晶圆制造商资本开支维持高强度及半导体设备国产市场进程加速,国产半导体设备厂商业绩有望持续放量。4、国家电网预计2024年电网建设投资总规模超5000亿元,特高压工程仍是重中之重近日,国家电网公司对外透露,2024年将继续加大数智化坚强电网的建设,促进能源绿色低碳转型,推动阿坝至成都东等特高压工程开工建设。围绕数字化配电网、新型储能调节控制、车网互动等应用场景,打造一批数智化坚强电网示范工程,预计电网建设投资总规模将超5000亿元。近年来,国家电网一直把建设特高压工程作为工作重点,2024年度特高压工程仍是重中之重。除8条特高压工程有望在年内开工。国家电网还将推动推动数条特高压工程的核准工作。国家电网年初工作会议再次提到以特高压和超高压为骨干网架,首次提到柔性直流”,特高压技术方向朝着柔性直流方向发展更为明确。机构人士认为,特高压作为主网基础,依旧是投资重心,2023年特高压直流开工规模为历史年度最高值,预计2024-2025期间柔直总投资或达1,005亿元,设备总投资/核心零部件换流阀投资或为603亿/146亿。免责声明:市场有风险,投资需谨慎。本文所载内容仅供海通证券股份有限公司的客户参考使用,客户须自主做出判断和投资决策。 -

华林证券郑崇丰2023-08-01 12:55:43
【先手午评】AI算力线中际旭创和浪潮信息重回成交榜前10. 成交榜前10中有5只券商,榜一坐着太平洋,高位搏杀剧烈。科技早盘科大讯飞的减持影响,还有昨日先涨停的鸿博股份早盘核按钮,还有浪潮信息昨日盘中跳水后早盘顺势低开,加上券商股的开局一度冲高,所以泛科技线开局是走低,随后券商和银行等大金融线调整,板块轮动大幕开启,汽车线众泰汽车涨停,江淮汽车冲高,CPO这边天孚通信快速拉升大涨,带动中际旭创,之后再带动浪潮信息,信创中国软件、太极股份等受益昨日盘后消息,均开始一起联动。今天跷跷板被抽血的是新能源,如果不是锂光储这些跌的多,泛科技线还真不一定能反弹这么多。预判日内的高潮轮动阶段已经过去,已经轮涨到的板块小跌,轮跌的板块小涨。操作上如果上午10点半前没做出调仓动作,下午基本就不适宜有追涨想法。 -

点金搏股2022-07-25 08:54:24
发布观点《点金计划】有信号就干,大涨就走人》 -

股王擒牛2022-07-06 14:45:20
【龙头狙击】注意双龙跌停,新机会机遇开启,注意这一机会! 高低切换注意挖掘底部超跌反弹牛,VIP持股拉升冲击涨停,后市机会在哪?注意成交量放大过程才有持续性,股王骑牛VIP连续止盈多只超短,速度运用底部起涨骑牛指标预警战法狙击,市场轮动加快,对标龙头股注意查看!短线操作上注意空间板的带动,博取底部超跌绩优牛+擒牛指标预警牛的博弈机会,如果被套的 安心等待急跌之后的反抽。股王骑牛指标狙击超短一绝,天天都有新机会,右上角+关注! 龙头狙击 前一日涨停的连板强股目前仅剩余了$赣能股份 sz000899$ 、$大连重工 sz002204$ 、$高乐股份 sz002348$ 、$金智科技 sz002090$ 这几只独立晋级,而其余的均出现了分歧。短线操作上,可重点关注低位品种的接力机会,例如$宏达高科 sz002144$ 等这类超跌票的接力;而高位股要暂时远离。 机会关注 日内盘中资金攻击了“机器人”方向。其中$矩子科技 sz300802$ 、$景业智能 sh688290$ 纷纷拉板20%涨停,外加高标人气股$巨轮智能 sz002031$ 拉板涨停,带动了$中大力德 sz002896$ 、$咸亨国际 sh605056$ 、$雷柏科技 sz002577$ 等相关个股纷纷拉板涨停,板块处于资金强势炒作中。短线操作上,可重点关注近几日有过涨停品种的个股,仅有低吸潜伏最佳(因为资金有记忆力,跟随板块强度会进行反包拉升)。龙头股很多是作为人气风向标,敬请期我们继续底部绩优标的的挖掘,即将到来挖掘潜力个股的黄金期。建议多挖掘超跌突破或者龙回头才是机会。但可对近期热点再出现调整时可做低吸参与,继续挖掘底部起涨标的机会。 特别提醒低位股补涨逐步成为了市场资金重要方向。当下大盘有回补前期3300点的跳空缺口,操作上谨慎为主,冲高注意减仓,行情上完全符合早间对市场的判断。中微公司公告,预计2022年半年度营业收入约19.7亿元,同比增长约47.1%;新增订单约30.6亿元,同比增长约62%。公司预计2022年半年度净利润为4.2亿元到4.8亿元,同比增加5.89%到21.02%。今年半导体行业国产替代加快,年初至今国产设备中标数接近上年总量,预计今年国产设备中标数量有望进一步提升。半导体板块的业绩在上半年是没有太大的问题,后续可以继续关注机会。中报业绩:湘潭昨晚出了业绩预告,整体来看还是不错的,目前也是高位盘整了一段时间,关注上主要看20日线的支撑,后续关注中报业绩披露的个股,特别是有叠加电力产业链,消费,汽车产业链的个股,如有吧回调都是可以把握低吸的机会。市场虽然高低切换明显,今天也是开启调整回落,但是现在调整反而是为后续的上涨提供空间,不用太过担心,关注上看中报预报业绩好的个股做绿盘低吸机会。谨慎的家人可等候调整结束。震荡行情中个股波动很正常,继续安心狙击超短隔夜强势股,如果盲目的持股或者持股时间较长会比较被动。蓄势待发注意机会,挖掘后面开启强反做铺垫,聪明散户逆向抄底的好时机!不能轻易追高,择机低吸低位股或调整充分的股票比较好,这是目前擒强势股的目标股,等待我的VIP通知。我们一起运用擒强势股超短章法,挖掘超短快进快出,规避盘中震荡的风险,尾盘进次日出,相当于变相T+0,操作更灵活,更加适合我们散户朋友,小资金做好收获! 敬请期待我们VIP体系升级---股王骑牛VIP新的擒强势股策略,注意查看! 1、永远不做股票超市(持股不超过3只)2、接下来只做低吸,涨停突破+擒牛指标预警机会3、强势股是突破介入,底部骑牛是底部介入不追涨杀跌4、止盈空间3-10% 5、持股快进快出,尽量隔夜止盈,做完一支给下一支 短线底部涨停启动叠加擒牛指标预警 ,只要加入股王骑牛战队的粉丝,这些战法都会在视频课中教学,都是实实在在的有效战法,学到就是赚到! 新模式擒强势股看得见的改变,我们继续擒强势股,方向不对努力白费,期待大家一起并肩战斗,一票一操作,超短不含糊,相信不会让您失望!订阅VIP加送【VIP专享诊股+核心热点干货直播+风口报告内享+仓位管理实战技巧+核心超短战法(龙回头+底部抓涨停+狙击涨停板等)文档(以及视频版】方向不对努力白费,期待大家一起并肩战斗,一票一操作,超短不含糊,相信不会让您失望!!【股王骑牛VIP持股昨日安徽建工拉升止盈,今日短线已经锁定,尽请期待放入新的挖掘!!】看一百次,不如行动一次,看都是问题,做才是答案。痛快的人赚痛快的钱,近期连续出击的短线标的都做的不错,后面会持续保持这个节奏,一票一操作,超短不含糊,相信股王骑牛不会让您失望! 擒牛指标预警✘选股体系,欢迎加入VIP,一起干!!越来越多的新学员加入到股王的VIP战队之中,股王为了不辜负学员们的信任信任创造价值,优中选优精选每天的出击目标!!招募名额有限抓强势股!股王骑牛VIP只做超短-速度订阅快!只有50个福利名额珍惜机会!订阅还送价值2980元 擒牛主升课程 股王骑牛VIP,名额有限大家都在抢!擒强势股VIP服务+每周一场干货直播!战绩实实在在这一次真正的倾囊相授,多名学员已经开抢!!大家都看到了吗?擒强势股热点直播里面有非常多的干货和实战案例!股王骑牛的VIP就是这样,做完一支再给下一支,不让你们做选择题,要加入VIP的老铁们速度了!新模式擒强势股看得见的改变,我们继续擒强势股,你还等什么? 方向不对努力白费,期待大家一起并肩战斗,一票一操作,超短不含糊,相信不会让您失望!你还想继续被动挨打吗?点击下方按钮,现在开通,解锁股王骑牛最新VIP出击策略!! -

跟庄探险队老季2022-05-19 11:31:35
5月19日午间收评:指数早间低开高走,风电、光伏等新能源方向走强,房地产板块继续活跃 受外围影响,三大指数早盘均大幅低开,随后震荡回升跌幅收窄,沪指、创业板指临近午盘翻红。风电、光伏等新能源方向走强,天顺风能、大金重工、中利集团、晶科科技等多股涨停。房地产板块继续活跃,南国置业、京投发展、中国武夷、我爱我家等近10股封板。此外教育、农业、林业等走势活跃,个股涨跌互现。午间收盘沪指跌0.08%,深成指跌0.25%,创业板跌0.12%。 -

一个掘金者2022-05-13 11:29:53
上午走得是真震荡,涨跌幅绝大多数比例都非常温和,汽车煤炭地产今天是撑起指数的主要力量,形态都是做底和超跌反弹。现在就到了筛选形态的阶段了。没有形态不可只说热门题材,有形态就是没有题材也可以上涨。就像昨天涨停的诺德股份的选股就是这样。现在只要不追高,不去追涨停板,温和震荡形态不破坏就坚定持股即可! -

雅悦——非著名投顾2022-04-14 13:36:38
策略配置中配置的酒ETF开始发力。 -

金股捕手2022-04-06 13:23:49
地产板块和中药板块的爆发都是有相关的主题意义存在,地产产业链的爆发主要是国内经济的压力增加,各地纷纷放开了限售限购相关的政策,这一政策预期打开了地产相关板块的补涨空间,简单说这是在炒作预期;因为大家都知道地产的业绩并未出现好转,市场炒作都是先行的,也许等政策真的落地了,那么就是到了资金兑现的时候,现在很多人也都是看好地产的相关行情,毕竟大家也都看得到,不过我这里需要提示一下:地产相关对于经济支撑固然重要,但是4月份也是业绩落地的阶段,地产股价已经先行,业绩和一季度的销量可能大家现实中都可以看到是不及预期的,资本市场情绪想来是多变的,所以追涨需谨慎;如果真的要去考虑,依据未来是否有做大做强的资本,未来是否有被兼并收购这两个预期去选择;而对于中药来讲,祖宗留下来的东西自然是好的,事实证明对于抗疫有着积极的效果,不过这一波有些也不低了,时刻关注国内数据变化,一旦数据出现拐点下行,那么中药行情股价也会跟随出现下行,这两者基本上是属于同步的关系! -

华林证券梁财华2022-03-29 17:16:56
江南化工(002226)一.基本面:公司主营工业炸药,雷管研发,生产,销售风力发电,光伏发电开发,建设,运营。2021年营业收入64.81亿元,同比增长65.39%,归母净利润10.53亿元,同比增长135.58%,扣费净利润5.415亿元,同比增长33.98%。PE16.58倍,PE相对低。二.消息面:国家能源局印发《2022年能源工作指导意见》稳步推进结构转型。煤炭消费比重稳步下降,非化石能源占能源消费总量比重提高到17.3%左右,新增电能替代电量1800亿千瓦时左右,风电、光伏发电发电量占全社会用电量的比重达到12.2%左右。国家能源局:.继续实施整县屋顶分布式光伏开发建设,加强实施情况监管.三.技术面:近期股价突破年线,量价齐升,均线多台排列,换手率比较高,3月24日涨停,说明有主力介入,25,28日股价回调,29号股价企稳。短期支撑位5.95元,短期压力位7.40.止盈价:7.40附近,止损价:5.95以上仅是个人看法,仅供参考,不构成投资建议,风险自担! -

股海飞扬2022-03-23 14:33:34
#市场凌乱,小心一日游行情在出现,地产高位风险较大# 大盘还在回暖,指数有点超出预期了,不过盘面给我个人呢感觉就是难受,乱套,今天海联金汇和宁波建工比较靓眼,这都是好的反馈,高位资金并没有全面撤退,下午做了中富通,中兴通讯不管你再烦,实实在在的几十亿封单在那了。下午这波地产拉的我是十分懵逼的,看看是不是像前天晚上医药一样








 产品入口: 新浪财经APP-股票-免费问股
产品入口: 新浪财经APP-股票-免费问股