


来源:XYQUANT
本篇是系统化资产配置系列报告的第六篇,详细介绍了一种实时预测中国GDP增速的Nowcasting方法。
实时预测(Nowcasting)是识别当前经济状态的流行方法。它的思想就是利用所有可得的信息来获得当前经济状态的估计。举例来说,GDP增速是反映经济状态的最直接指标,但由于它只在每季度发布一次,且发布时间滞后,因此我们总是无法得到当前季度的GDP增速。这样一来,我们就必须使用其他更高频指标如工业增加值增速等来推测当前季度的GDP增速。
宏观经济数据建模面临多个难点,包括数据公布时间不同步、有缺失值、截面维度高和数据频率不一致等。为了解决这些问题,本文介绍了一种基于动态因子模型的Nowcasting方法。在这个模型里,所有可观测的宏观经济数据能够被若干不可观测的隐含因子所解释。
我们从工业、价格、国内外贸易、固定投资、财政、景气调查、银行与货币等方面选取了39个指标建立了中国经济Nowcasting模型。我们在模型中设定了5个隐含因子,分别是全局因子(Global),实际产出因子(Real),金融因子(Finance),情绪因子(Sentiment)和价格因子(Price)。
本文还利用动态因子模型进行了实际测算。通过在样本内构建“伪数据集”的方法,我们展示了对于2019年二、三、四季度GDP同比的Nowcasting过程。结果发现,随着数据集的扩大,对当季GDP的预测值与实际发布值会越来越接近,这初步验证了基于动态因子模型的Nowcasting方法有效性。
最后,基于2020年4月13日的可得数据,我们对2020年一季度GDP同比做了样本外预测,最终预测值为-2.849%。2020年4月17日国家统计局正式公布了我国2020年一季度GDP同比增速为-6.8%。
本篇是系统化资产配置系列报告的第六篇,详细介绍了一种实时预测中国GDP增速的Nowcasting方法。实时预测(Nowcasting)是识别当前经济状态的流行方法。它的思想就是利用所有可得的信息来获得当前经济状态的估计。但是,对宏观经济数据建模面临多个难点,包括数据公布时间不同步、有缺失值、截面维度高和数据频率不一致等。为了解决这些问题,本文将介绍一种基于动态因子模型的Nowcasting方法,并利用此方法对我国2019年二、三、四季度季度做模拟预测,结果发现预测准确度较高。最后,基于2020年4月13日的可得数据,我们对2020年一季度GDP同比做了样本外预测,最终预测值为-2.849%。
报告正文
1
Nowcasting
1.1. 什么是Nowcasting
对于政府机构来说,当前经济状态直接影响到宏观政策的制定。例如,央行需要判断当前经济是否过热,从而决定是否需要通过加息等措施来给经济降温。对于投资者来说,经济状态也直接影响投资策略。例如在经济上行时,投资者应该配置更多的权益资产。因此准确且及时的识别当前经济环境具有重要的意义。
实时预测(Nowcasting)是识别当前经济状态的流行方法。它的思想就是利用所有可得的信息来获得当前经济状态的估计。举例来说,GDP增速是反映经济状态的最直接指标,但由于它只在每季度发布一次,且发布时间滞后,因此我们总是无法得到当前季度的GDP增速。这样一来,我们就必须使用其他更高频指标如工业增加值增速等来推测当前季度的GDP增速。
那么如何对数量庞大的各种宏观指标建模,从而实现实时的经济状态预测呢? 本文将介绍一种基于动态因子模型的Nowcasting方法,它可以解决宏观经济数据建模面临的多种困难。
1.2. 宏观经济数据建模的难点
宏观经济数据的特点决定了我们难以用简单模型如线性回归来对其建模和预测,宏观数据建模的难点主要有以下几点:
1. 宏观数据公布时间不同步,且可能有缺失值。一般来说,各类宏观数据是随着时间推进而逐渐发布的。PMI这种调查数据可以在当月底获得;工业、价格等数据在次月上旬发布;而M2、社融等数据要在次月中下旬才能获得。也就是说,在任意时刻我们可得的最新宏观数据呈现出“锯齿状”结构。另外,我国宏观数据在每年春节前后有“官方缺失”的特点。根据统计报表制度,2月份不发布1月份规模以上工业和能源生产、固定资产投资、房地产开发投资和销售、社会消费品零售总额和工业经济效益等数据。
2. 宏观数据频率不一致。为了进行宏观数据研究,我们需要将数据统一在一个频率上。对宏观数据来说,月度频率是最常见的,但如GDP增速等重要数据却是季度发布的。如何科学的处理这种频率的不一致是一个问题。
3. 宏观数据截面维度高,但时间序列长度较短。现代市场经济运行极为复杂,各种各样的统计指标都能在一定程度上反映经济运行情况,如工业生产、固定资产投资、国内贸易、对外贸易、财政、银行与货币、价格以及各类景气度调查等等。而由于宏观指标发布频率通常在月频以下,经常会出现宏观数据截面维度高于时间维度的情况,也就是有N>T的问题,这给建立计量模型带来一定困难。另外,截面维度过高也给挑选和剔除指标带来了困难。
4. 宏观数据统计口径可能发生变化。理论上说,统计口径变动是为了让测量值更好的逼近真实值。但统计口径大幅变动带来的不一致性可能会严重影响线性回归等简单模型的预测和推论。因此我们需要某种更加稳健的方法来对宏观数据建模。
2
动态因子模型
2.1. 标准动态因子模型

2.2. 考虑误差项序列自相关

2.3. 模型估计算法
动态因子模型中需要估计的变量包括各个隐含因子和模型参数,它们的取值互相依赖且未知变量数量庞大,因此普通的最大似然法难以有效的估计模型。幸运的是,学界已经提出了可以稳健估计动态因子模型的PCA+EM算法。
具体来说,PCA+EM算法流程如下:

以上的PCA+EM算法将宏观数据映射为若干个隐含因子,可以解决数据截面维度高的问题。其中的EM算法还使用了Kalman滤波,它可以自动处理缺失值,同时对于统计口径的变动具有较强稳健性。
2.4. Nowcasting过程

3
中国经济Nowcasting模型
前文介绍了动态因子模型理论及其估计方法,下面我们开始正式建立中国经济Nowcasting模型并介绍宏观数据的具体处理方法。
3.1. 中国宏观数据处理



3.2. 模型设定
我们从工业、价格、国内外贸易、固定投资、财政、景气调查、银行与货币等度量宏观经济的不同角度选取了39个指标来建立中国经济Nowcasting模型。参考纽约联储Nowcasting模型的隐含因子设定,我们在中国经济Nowcasting模型中设定了5个隐含因子,分别是全局因子(Global),实际产出因子(Real),金融因子(Finance),情绪因子(Sentiment)和价格因子(Price)。
不同的宏观数据根据其类型对5个隐含因子的载荷不同。举例来说,GDP同比增速对全局因子和实际产出因子有载荷,而对金融、情绪和价格因子没有载荷。CPI同比对全局因子和价格因子有载荷,而对实际产出、金融和情绪因子没有载荷。图表1详细给出了每个宏观数据的类型及其对5个隐含因子的载荷设定。
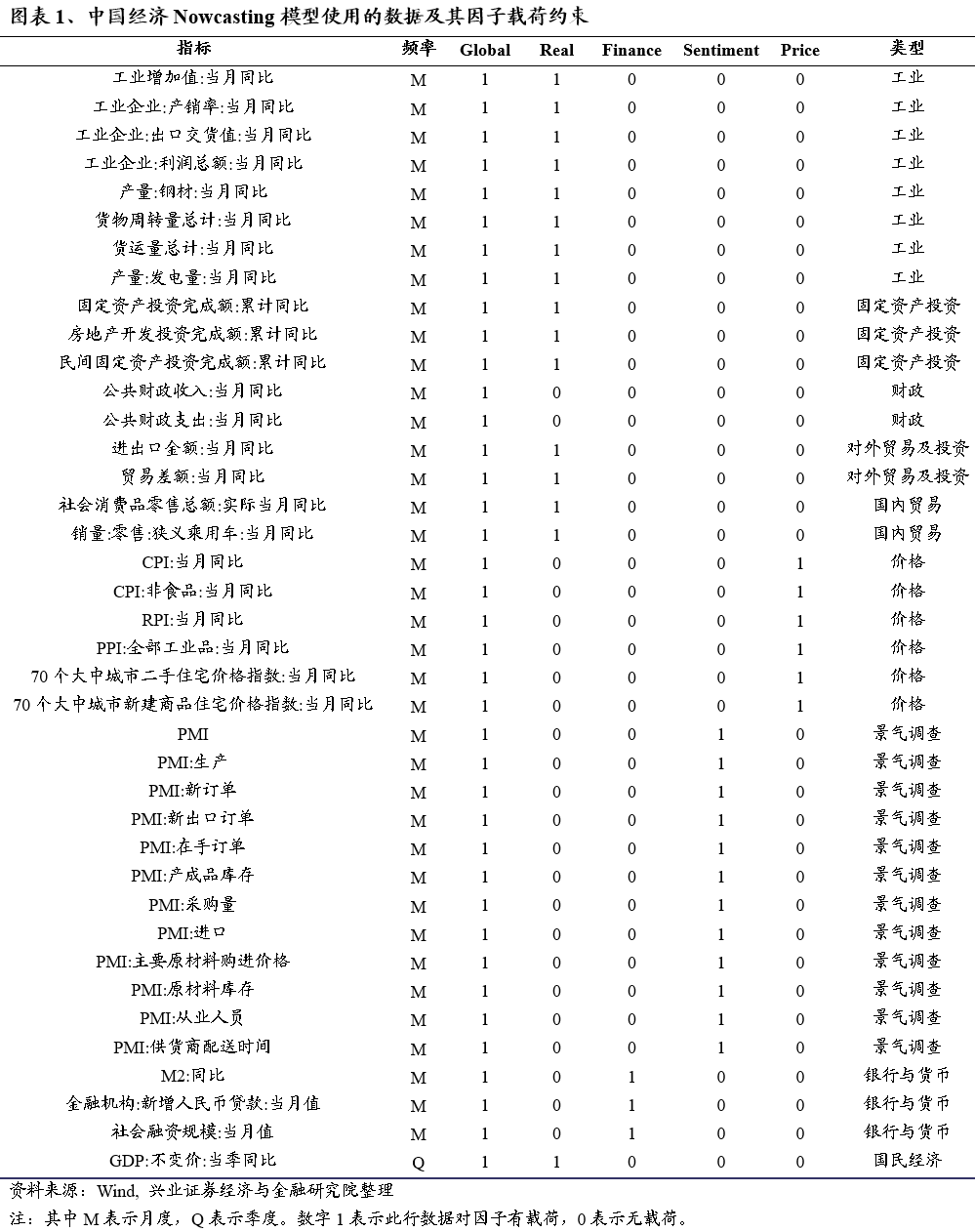
4
实证结果
4.1. DFM模型结果示例
我们首先给出一个DFM模型的估计结果示例。假设当前时点为2020年4月13日,我们从Wind终端获取从2005年1月以来的所有可得宏观数据,然后通过PCA+EM算法估计出模型参数和5个隐含因子序列。
图表一给出了模型估计的5个隐含因子序列,他们分别代表全局因子(Global)、实际产出(Real),金融(Finance),情绪(Sentiment)和价格(Price)。我们可以看到在2008年金融危机前后各个因子水平出现了剧烈波动,且其中情绪因子变动较其他因子有明显领先性。另外,在2020年2、3月份,由于疫情冲击,可以看到实际产出和情绪因子出现大幅下跌。
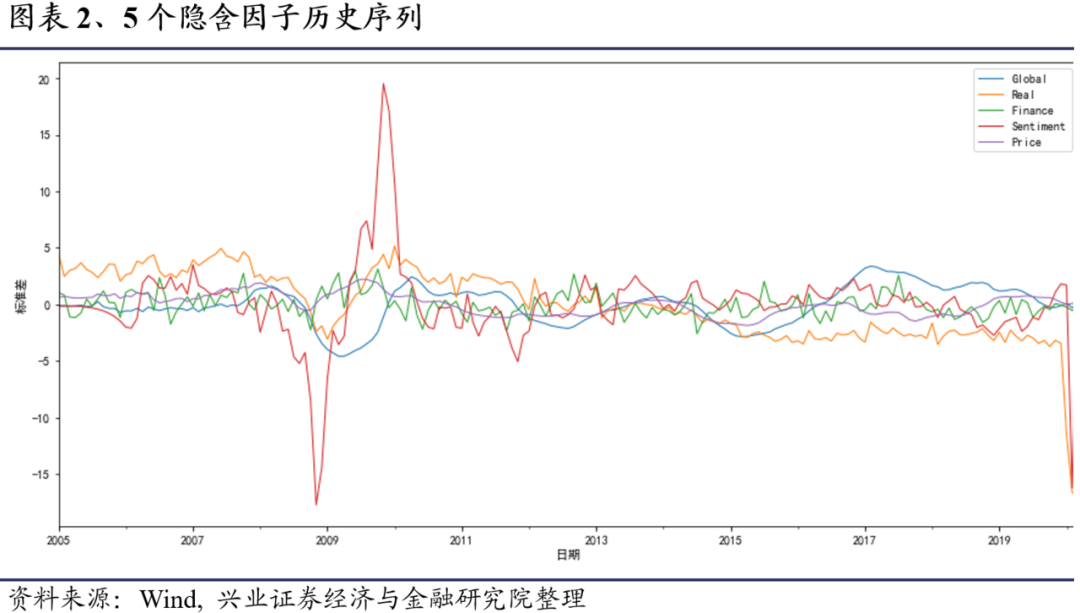
我们之所以在模型中纳入全局因子,目的是为了捕捉所有宏观变量的共同推动因素,从而在后续做某一宏观指标的预测时能够纳入所有新信息对目标指标的冲击。另外,全局因子捕捉了经济运行中的共同推动因素,某种程度上可以作为经济整体活跃水平的一种度量。图表3给出了全局因子与本文使用的所有标准化宏观数据的历史序列,直观地看全局因子确实能够捕捉到变量间的总体变动趋势。
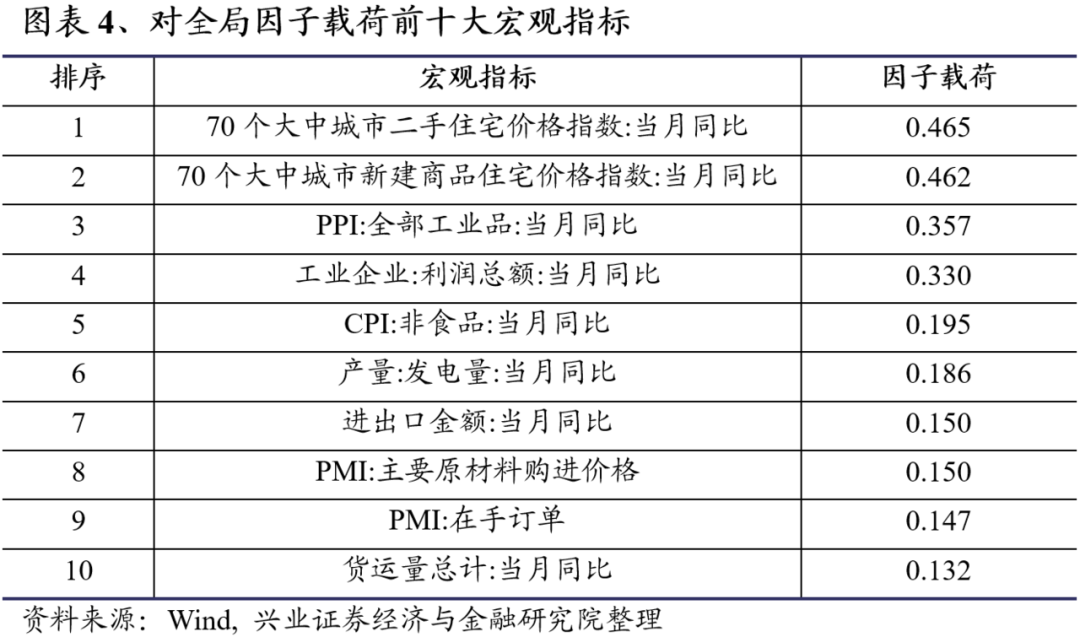
各宏观指标在因子上的载荷大小能在一定程度上表示其蕴含的信息量。图表4给出了对全局因子载荷最大的10个宏观指标,其中房地产价格载荷最大,这可能表明我国经济在最近15年里确实受房地产行业影响较大。

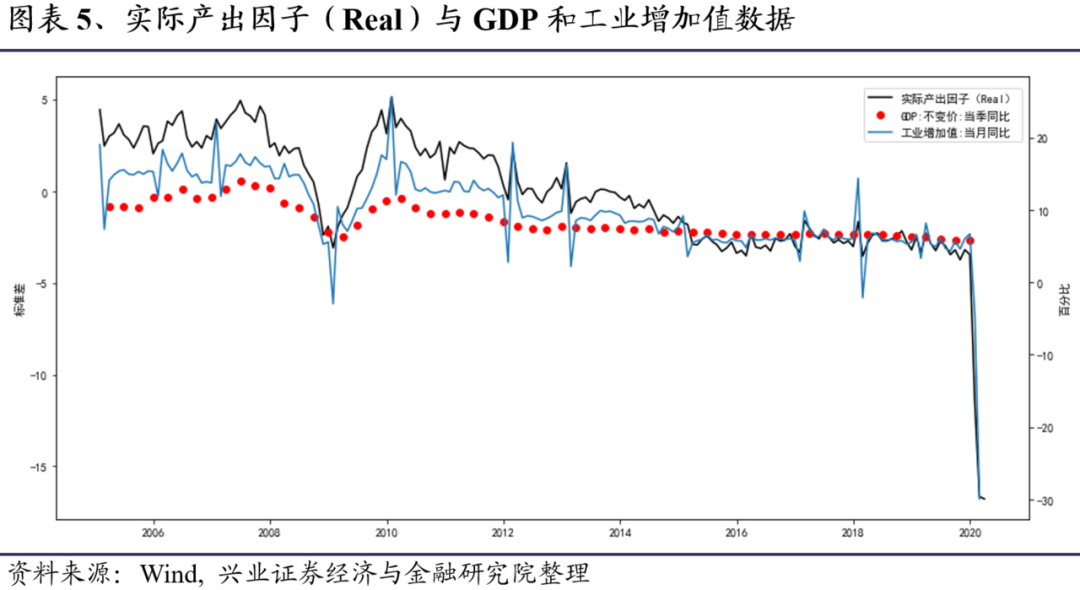
图表5给出了实际产出因子与GDP同比和工业增加值同比的变动关系。从图表看,隐含因子走势与GDP同比和工业增加值同比走势非常一致,这说明实际产出因子能够捕捉到经济体中的实际产出变动。
在以上的讨论中我们发现,各隐含因子具有衡量经济运行状态的潜在能力。不同的隐含因子代表经济运行的不同方面,在未来,我们会进一步探究利用隐含因子序列来对经济周期进行划分的可行性。不过,本文的重点是探究动态因子模型对宏观指标的预测能力,下面我们以GDP同比的预测为例,给出Nowcasting模型的结果。
4.2. Nowcasting样本内预测示例
如本文2.4部分所述,标准的Nowcasting过程是在每个时点获取所有可得数据,然后据此拟合DFM模型、更新预测结果。不过由于难以获取各宏观指标的历史发布时间数据,我们在这里通过构建历史月度“伪数据集”的形式来展示Nowcasting过程。
举例来说,假设我们处在2019年二季度,此时二季度GDP同比数据尚未发布,我们要利用其他已有数据来对其进行预测。假设在某时刻(如2019年4月下旬)2019年3月份及之前的所有数据已经发布完毕,我们便利用2005年1月至2019年3月的所有月度数据拟合DFM模型,从而获得2019年二季度的GDP同比增速预测值。图表6中的2019-03行就表示基于2019年3月及之前数据对二季度GDP同比增速的预测结果。可以看到,此时二季度GDP预测值为6.873%,与二季度实际发布增速6.2%差距较大。同样的,基于2019年4月及以前的数据,我们再次拟合DFM模型,获得二季度GDP预测值为6.491%,预测值较上月预测有明显下降。基于2019年5月数据的二季度GDP预测值为6.238%,较上月预测值继续下降,且与实际值的差距明显缩小。图表6中最后一行假设了除二季度GDP以外的其他2019年6月数据均已发布,基于此伪数据集的二季度GDP预测值为6.336%。从以上预测过程可以看出,随着时间推移和数据集的扩大,对于GDP增速的预测会越来越准确,逐渐贴近实际发布值。
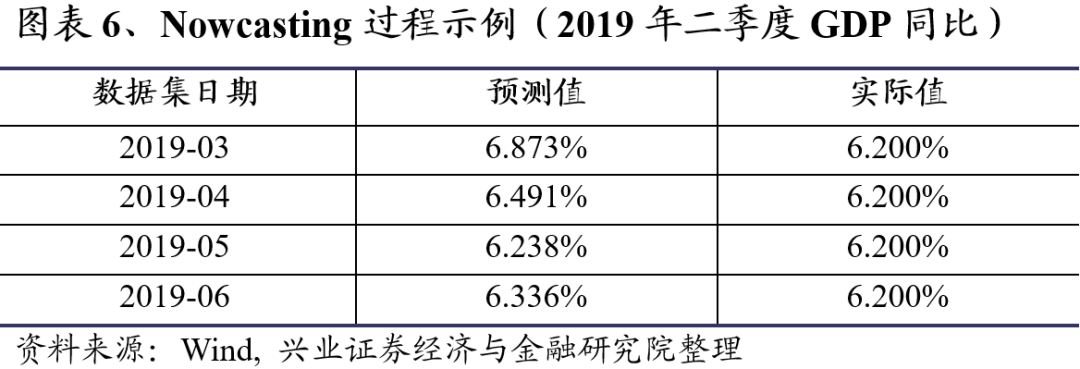
使用相同的方法,我们再给出对于2019年三、四季度GDP同比增速的预测过程示例。
从图表7看,基于2019年6月及之前数据的三季度GDP同比预测为6.697%,与6.0%的实际值差距较大。而基于2019年8月和2019年9月的数据集对三季度GDP预测分别为5.957%和5.988%,与实际值已经非常接近。
从图表8看,基于2019年9月及之前数据的四季度GDP同比预测为6.227%。而基于2019年11月的数据集,四季度GDP预测值修正为6.045%,非常接近实际值。
总体来看,随着数据的不断发布,对于当季GDP的预测值与实际发布值会越来越接近,这初步验证了本文基于动态因子模型的Nowcasting方法有效性。
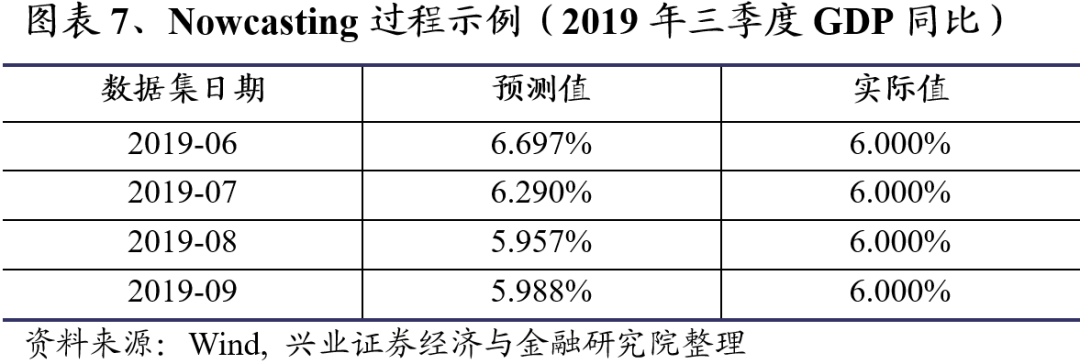
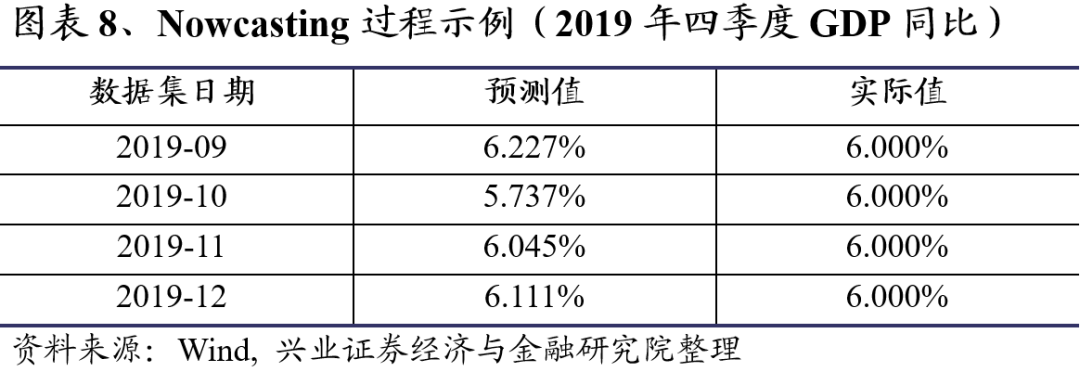
4.3. Nowcast2020年一季度GDP同比
4.2部分的Nowcasting结果示例是基于伪数据集的样本内预测,还不能完全展示Nowcasting实际过程和证明DFM模型的预测有效性。在撰写本报告时,2020年一季度GDP同比数据尚未发布,我们在此利用DFM模型对其进行样本外预测。
我们以2020年4月6日和2020年4月13日获取的两组数据集来展示实际Nowcasting过程。为了更好的展示一季度GDP同比预测值的变动过程,我们首先依然利用本文4.2部分的方法构建截止2020年2月的月度历史伪数据集,并用每个数据集拟合DFM模型从而获得一季度GDP同比预测值序列。
从图表9看,基于2019年12月及之前数据的一季度GDP同比预测值为6.470%。而随着一月份数据发布,GDP同比预测降为4.847%。同时二月份经济数据出现较大下滑,这直接导致一季度GDP预测转为负增长3.398%。
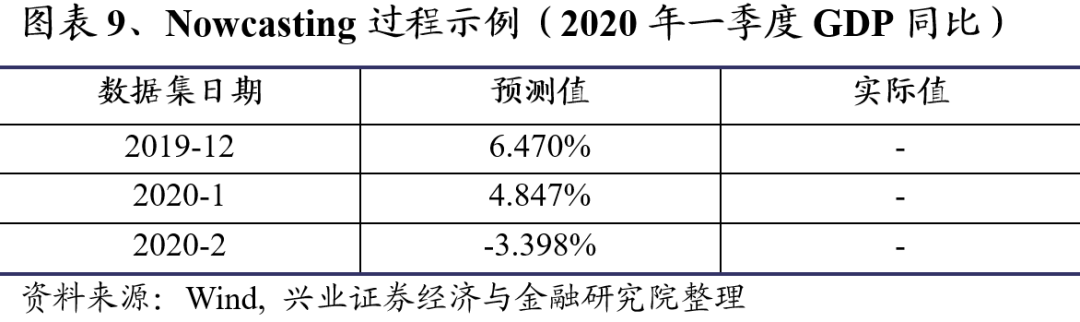

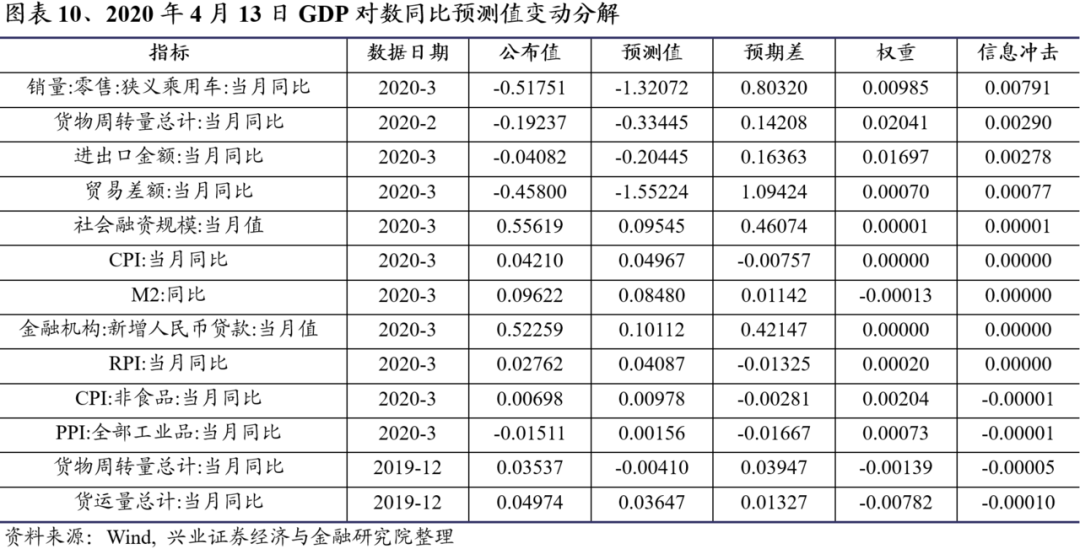
从图表10看,3月份乘用车销量、货物周转量以及进出口情况超出预期,公布值均高于上次预测值,这使得模型上调了GDP对数同比预测值。因此,截止2020年4月13日我们对一季度GDP同比的最新预测值为-2.849%。
值得注意的是,本文使用的动态因子模型是一种纯粹基于数据的计量模型,它的准确与否取决于数据的质量和更新的速度。另外,相比模型给出的预测绝对值,新信息带来的预测值边际变化可能对于指导投资有更重要的意义。
5
结论
本文首先介绍了实时预测(Nowcasting)的概念和思想,列举了宏观经济数据建模的难点。然后介绍了动态因子模型及其估计方法,动态因子模型本身的特性使其可以方便的处理中国宏观经济数据具有的发布时间不一致、缺失值、截面维度高和数据频率不一致等问题。
随后我们从工业、价格、国内外贸易、固定投资、财政、景气调查、银行与货币等度量宏观经济的不同角度选取了39个指标建立了中国经济Nowcasting模型。参考纽约联储Nowcasting模型的隐含因子设定,我们在中国经济Nowcasting模型中设定了5个隐含因子,分别是全局因子(Global),实际产出因子(Real),金融因子(Finance),情绪因子(Sentiment)和价格因子(Price)。
我们还利用动态因子模型进行了实际测算。通过在样本内构建“伪数据集”的方法,我们展示了对于2019年二、三、四季度GDP同比的Nowcasting过程。结果发现,随着数据集的扩大,对当季GDP的预测值与实际发布值会越来越接近,这初步验证了本文基于动态因子模型的Nowcasting方法有效性。
最后,基于2020年4月13日的可得数据,我们对2020年一季度GDP同比做了样本外预测,最终预测值为-2.849%。2020年4月17日国家统计局正式公布了我国2020年一季度GDP同比增速为-6.8%。






APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




