


转自:财联社
《科创板日报》12月11日讯(编辑 宋子乔)日前,加州大学研究人员和英伟达共同发布了新的视觉语言模型“NaVILA”。亮点在于,NaVILA模型为机器人导航提供了一种新方案。


NaVILA模型的相关论文
视觉语言模型(VLM)是一种多模态生成式AI模型,能够对文本、图像和视频提示进行推理。它通过将大语言模型(LLM)与视觉编码器相结合,使LLM具有“看”的能力。
传统的机器人行动往往依赖于预先绘制的地图和复杂的传感器系统。而NaVILA模型不需要预先的地图,机器人只需“听懂”人类的自然语言指令,结合实时的视觉图像和激光雷达信息,实时感知环境中的路径、障碍物和动态目标,就可以自主导航到指定位置。
不仅摆脱了对地图的依赖,NaVILA还进一步将导航技术从轮式扩展到了足式机器人,希望让机器人应付更多复杂场景,使其具备跨越障碍和自适应路径规划的能力。
在论文中,加州大学研究人员使用宇树Go2机器狗和G1人形机器人进行了实测。根据团队统计的实测结论,在家庭、户外和工作区等真实环境中,NaVILA的导航成功率高达88%,在复杂任务中的成功率也达到了75%。
 Go2机器狗接受行动指令:向左转一点,朝着肖像海报走,你会看到一扇敞开的门
Go2机器狗接受行动指令:向左转一点,朝着肖像海报走,你会看到一扇敞开的门
G1人形机器人接受行动指令:立即左转并直行,踩上垫子继续前进,直到接近垃圾桶时停下来
据介绍,NaVILA模型的特点在于:
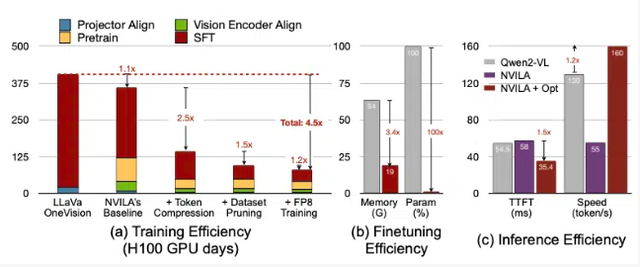
优化准确性与效率:NVILA模型在训练成本上降低了4.5倍,微调所需内存减少了3.4倍。在预填充和解码的延迟上几乎降低了2倍(这些数据是与另一个大型视觉模型LLaVa OneVision进行比较得出的)。
高分辨率输入:NVILA模型并不通过降低照片和视频的大小来优化输入,而是使用高分辨率图像和视频中的多个帧,以确保不丢失任何细节。
压缩技术:英伟达指出,训练视觉语言模型的成本非常高,同时,微调这样的模型也非常耗费内存,7B参数的模型需要超过64GB的GPU内存。因此英伟达采用了一种名为“先扩展后压缩”的技术,通过将视觉信息压缩为更少的token,来减少输入数据的大小,并将像素进行分组,以保留重要信息,平衡模型的准确性与效率。
多模态推理能力:NVILA模型能够根据一张图片或一段视频回答多个查询,具有强大的多模态推理能力。
在视频基准测试中,NVILA的表现超过了GPT-4o Mini,并且在与GPT-4o、Sonnet 3.5和Gemini 1.5 Pro的比较中也表现出色。NVILA还在与Llama 3.2的对比中取得了微弱胜利。
英伟达表示,目前尚未将该模型发布到Hugging Face平台上,其承诺会很快发布代码和模型,以促进模型的可复现性。
(科创板日报 宋子乔)

责任编辑:陈钰嘉

VIP课程推荐
APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




