


来源:有新Newin
6 月 2 日晚,英伟达 CEO 黄仁勋在台北 ComputeX 2024 大会上展示了英伟达在加速计算和生成式AI领域的最新成果,还描绘了未来计算和机器人技术的发展蓝图。

这场演讲涵盖了从 AI 基础技术到未来机器人和生成式 AI 在各个行业的应用,全面展示了英伟达在推动计算技术变革方面的卓越成就。

黄仁勋表示,英伟达位于计算机图形、模拟和 AI 的交汇处,这是英伟达的灵魂。今天展示给我们的一切都是模拟的,它是数学、科学、计算机科学、令人惊叹的计算机架构的结合。这些都不是动画,而是自制的,英伟达把它全部融入了 Omniverse 虚拟世界。
▍加速计算与 AI

黄仁勋表示,我们所看到的一切的基础是两项基本技术,加速计算和在 Omniverse 内部运行的AI,这两股计算的基本力量,将重新塑造计算机行业。计算机行业已有 60 年的历史。在很多方面,今天所做的一切都是在 1964 年黄仁勋出生后一年发明的。
IBM System 360 引入了中央处理单元、通用计算、通过操作系统实现硬件和软件的分离、多任务处理、IO子系统、DMA以及今天使用的各种技术。架构兼容性、向后兼容性、系列兼容性,所有今天对计算机了解的东西,大部分在1964 年就已经描述出来了。当然,PC 革命使计算民主化,把它放在了每个人的手中和家中。
2007 年,iPhone 引入了移动计算,把计算机放进了我们的口袋。从那时起,一切都在连接并随时运行通过移动云。这 60 年来,我们只见证了两三次,确实不多,其实就两三次,主要的技术变革,计算的两三次构造转变,而我们即将再次见证这一切的发生。

有两件基本的事情正在发生。首先是处理器,即计算机行业运行的引擎,中央处理单元的性能提升显著放缓。然而,我们需要进行的计算量仍然在迅速增长,呈指数级增长。如果处理需求,数据需要处理的量继续指数级增长但性能没有,计算通货膨胀将会发生。事实上,现在就看到了这一点。全球数据中心使用的电力量正在大幅增长。计算成本也在增长。我们正在经历计算通货膨胀。
当然,这种情况不能继续下去。数据量将继续以指数级增长,而 CPU 性能提升将永远不会恢复。我们有更好的方法。近二十年来,英伟达一直在研究加速计算。CUDA 增强了 CPU,卸载并加速了专用处理器可以更好完成的工作。事实上,性能非常出色,现在很明显,随着 CPU 性能提升放缓并最终显著停止,应该加速一切。

黄仁勋预测,所有需要大量处理的应用程序都会被加速,当然每个数据中心在不久的将来都会被加速。现在加速计算是非常合理的。如果你看看一个应用程序,这里100t 代表 100 单位时间,它可能是100秒,也可能是 100 小时。在很多情况下,如你所知,现在正在研究运行 100 天的 AI 应用程序。
1T 代码是指需要顺序处理的代码,其中单线程CPU是非常关键的。操作系统控制逻辑非常重要,需要一条指令接着一条指令地执行。然而,有很多算法,比如计算机图形处理,可以完全并行操作。计算机图形处理、图像处理、物理模拟、组合优化、图处理、数据库处理,当然还有深度学习中非常著名的线性代数,这些算法都非常适合通过并行处理来加速。
因此,发明了一种架构,通过在 CPU 上添加 GPU 来实现。专用处理器可以将耗时很长的任务加速到极快的速度。因为这两个处理器可以并肩工作,它们都是自主的,独立的,可以将原本需要 100 个时间单位的任务加速到 1 个时间单位,速度的提升是难以置信的,效果非常显著,速度提升了 100 倍,但功耗只增加了大约三倍,成本只增加了约 50%。在 PC 行业一直这样做,英伟达在1000 美元 PC 上加一个 500 美元 GeForce GPU,性能会大幅提升。英伟达在数据中心也这样做,一个价值十亿美元的数据中心,加上 5 亿美元的GPU,突然间它就变成了一个 AI 工厂,这种情况正在全球各地发生。
节省的成本非常惊人。每花一美元就能获得 60 倍的性能提升,速度提升了 100倍,而功耗只增加了三倍,成本只增加了 1.5倍。这种节省是难以置信的。节省的成本可以用美元来衡量。
很明显,许多公司在云端处理数据上花费了数亿美元。如果这些过程被加速,不难想象可以节省数亿美元。这是因为在通用计算上已经经历了很长时间的通货膨胀。

现在终于决定加速计算,有大量被捕获的损失可以现在回收,许多被保留的浪费可以从系统中释放出来。这将转化为金钱的节省和能源的节省,这也是为什么黄仁勋常说‘买得越多,省得越多’。
黄仁勋还表示,加速计算确实带来了非凡的成果,但它并不容易。为什么它能省这么多钱,但这么长时间以来人们却没有这样做呢?原因是因为这非常难。没有一种软件可以通过C编译器运行,突然间应用程序就快了100倍。这甚至不合逻辑。如果可以做到这一点,他们早就改造 CPU了。
事实上,必须重写软件,这是最难的部分。软件必须完全重写,以便能够重新表达在 CPU 上编写的算法,使其能够被加速、卸载并行运行。这种计算机科学的练习极其困难。

黄仁勋表示,在过去 20 年里,英伟达让全世界变得更容易。当然,非常著名 cuDNN,即处理神经网络的深度学习库。英伟达有一个 AI 物理库,可以用于流体动力学和许多其他应用中,神经网络必须遵守物理定律。英伟达有一个叫 Arial Ran 新的伟大库,它是一个 CUDA 加速 5G 无线电,能够像定义世界网络互联网一样定义和加速电信网络。加速的能力使我们能够将所有的电信转变为与云计算平台相同类型的平台。
cuLITHO 是一个计算光刻平台,能够处理芯片制造中最计算密集的部分——制作掩膜。台积电正在使用 cuLITHO 进行生产,节省了大量的能源和金钱。台积电的目标是加速他们的堆栈,以便为进一步的算法和更深入、更窄的晶体管的计算做好准备。Parabricks 是英伟达基因测序库,它是世界上吞吐量最高的基因测序库。cuOpt是一个用于组合优化、路线规划优化的令人难以置信的库,用于解决旅行商问题,非常复杂。
科学家们普遍认为需要量子计算机来解决这个问题。英伟达创造了一个在加速计算上运行的算法,运行速度极快,创下了23项世界纪录。cuQuantum是一个量子计算机的模拟系统。如果你想设计一个量子计算机,你需要一个模拟器。如果你想设计量子算法,你需要一个量子模拟器。如果量子计算机不存在,你如何设计这些量子计算机,创建这些量子算法呢?你使用今天世界上最快的计算机,当然就是NVIDIA CUDA。在上面,英伟达有一个模拟器,可以模拟量子计算机。它被全世界数十万研究人员使用,并集成到所有领先的量子计算框架中,广泛用于科学超级计算中心。
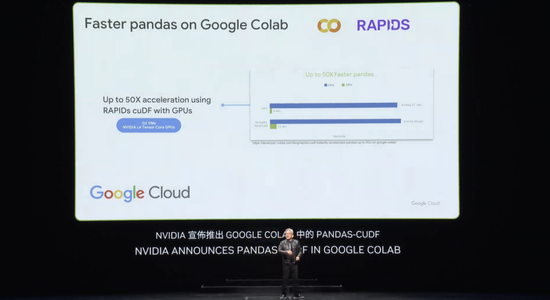
cuDF是一个令人难以置信的数据处理库。数据处理消耗了今天云端支出的绝大部分,所有这些都应该被加速。cuDF加速了世界上使用的主要库,比如Spark,许多公司可能都在使用Spark,Pandas,一个新的叫做Polars的库,当然还有NetworkX,一个图处理数据库库。这些只是一些例子,还有很多其他的。
黄仁勋表示,英伟达必须创建这些库,以便让生态系统能够利用加速计算。如果英伟达没有创建cuDNN,光有 CUDA 是不可能让全世界的深度学习科学家使用的,因为 CUDA、TensorFlow 和 PyTorch中使用的算法之间的距离太远了。这几乎像是在没有OpenGL 情况下做计算机图形处理,或者没有 SQL 的情况下进行数据处理。这些特定领域的库是英伟达的珍宝,总共有350个库。正是这些库使英伟达能够打开如此多的市场。
上周,Google 宣布在云端加速 Pandas,这是世界上最流行的数据科学库。你们中的许多人可能已经在使用Pandas,它被全球 1000 万数据科学家使用,每月下载1.7 亿次。它是数据科学家的电子表格。现在,只需点击一下,你就可以在 Google 云数据中心平台 Colab 中使用由 cuDF 加速 Pandas,加速效果真的非常惊人。
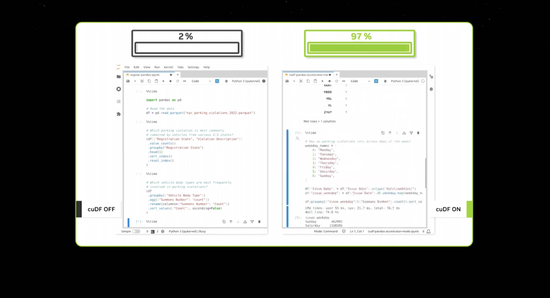
当你将数据处理加速到如此快的速度时,演示确实不会花很长时间。现在 CUDA 已经达到了人们所说的临界点,但它甚至更好。CUDA 现在已经实现了一个良性循环。
这种情况很少发生。如果你看看历史上所有计算架构的平台。以微处理器 CPU 为例,它已经存在了 60 年,并且在这个层面上没有发生变化。这种计算方式,加速计算已经存在,创建一个新平台极其困难,因为这是一个先有鸡还是先有蛋的问题。
如果没有开发人员使用你的平台,那么当然也就不会有用户。但是如果没有用户,就没有安装基础。如果没有安装基础,开发人员就不会对它感兴趣。开发人员希望为大型安装基础编写软件,但大型安装基础需要大量应用程序来吸引用户创建安装基础。
这种先有鸡还是先有蛋的问题很少被打破。而英伟达花了 20 年的时间,一个领域的库接着一个领域的库,一个加速库接着一个加速库,现在有 500 万开发人员在全球范围内使用英伟达的平台。
英伟达服务于每一个行业,从医疗保健、金融服务、计算机行业、汽车行业,几乎所有主要行业,几乎所有科学领域,因为英伟达的架构有这么多客户,OEM 厂商和云服务提供商对构建英伟达的系统感兴趣。像台湾这里的系统制造商这样的优秀系统制造商对构建英伟达的系统感兴趣,这使得市场上有更多的系统可供选择,这当然为我们创造了更大的机会,使我们能够扩大规模,研发规模,从而进一步加速应用。
每次加速应用,计算成本就会下降。100 倍加速转化为 97%、96%、98% 节省。因此,当我们从 100 倍加速到 200 倍加速,再到 1000 倍加速时,计算的边际成本继续下降。
英伟达相信,通过大幅降低计算成本,市场、开发人员、科学家、发明家将继续发现越来越多的算法,这些算法消耗越来越多的计算资源,最终会发生质的飞跃,计算的边际成本如此之低,以至于一种新的计算使用方式出现了。
事实上,这正是现在看到的情况。多年来,英伟达在过去 10 年里将某种特定算法的边际计算成本降低了百万倍。因此,现在训练包含整个互联网数据的 LLM 是非常合理和常识的,没有人会怀疑。这个想法,即你可以创建一个能够处理如此多数据的计算机来编写自己的软件。AI 的出现是因为完全相信,如果让计算变得越来越便宜,总会有人找到一个伟大的用途。
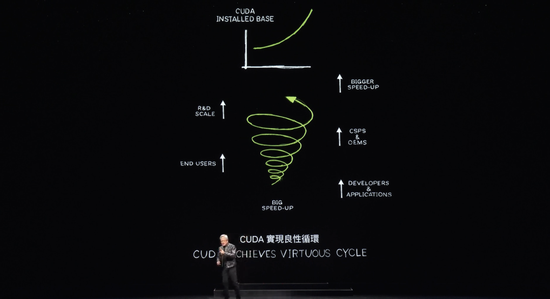
如今,CUDA 已经实现了良性循环。安装基础在增长,计算成本在下降,这导致更多的开发人员提出更多的想法,从而推动更多的需求。现在我们正处在一个非常重要的起点。
黄仁勋接着提到了地球2的想法,将创建地球的数字孪生体,通过模拟地球,可以更好地预测未来,从而更好地避免灾害,更好地理解气候变化的影响,以便更好地适应。

研究人员在 2012 年发现了 CUDA,那是英伟达与 AI 第一次接触,这是一个非常重要的日子。有幸与科学家合作,使深度学习成为可能。
AlexNet 取得了巨大的计算机视觉突破。但更重要的是,退一步理解深度学习的背景、基础以及其长期影响和潜力。英伟达意识到这项技术具有巨大的扩展潜力。一种几十年前发明和发现的算法,突然之间,因为更多的数据、更大的网络以及非常重要的更多计算资源,深度学习实现了人类算法无法实现的成就。
现在想象一下,如果进一步扩展架构,更大的网络、更多的数据和更多的计算资源,可能会实现什么。2012年之后,英伟达改变了GPU的架构,增加了 Tensor 核心。英伟达发明了NVLink,那是10年前的事了,CUDA,然后是TensorRT、NCCL,收购了Mellanox、TensorRT-ML、Triton推理服务器,所有这些都整合在一台全新的计算机上。没有人理解,没有人要求,没有人理解它的意义。
事实上,黄仁勋确信没有人想买它,英伟达在 GTC 上宣布了它,OpenAI,一个位于旧金山的小公司,请求英伟达为他们提供一台。
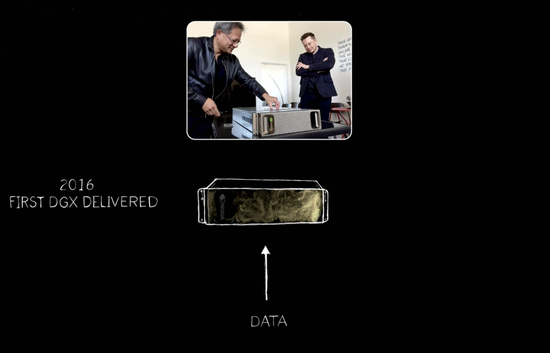
2016 年,黄仁勋向 OpenAI 交付了第一台 DGX,世界上第一台 AI 超级计算机。之后,继续扩展,从一台 AI 超级计算机,一台 AI 设备,扩展到大型超级计算机,甚至更大。
到2017年,世界发现了Transformer,使能够训练大量数据,识别和学习长期序列模式。现在,英伟达可以训练这些 LLM,理解并在自然语言理解方面取得突破。继续前进,建造了更大的系统。
然后在 2022 年 11 月,使用成千上万英伟达 GPU和非常大的 AI 超级计算机进行训练,OpenAI 发布了 ChatGPT,五天内用户达到一百万,两个月内达到一亿,成为历史上增长最快的应用。
在 ChatGPT 向世界展示之前,AI 一直是关于感知,自然语言理解、计算机视觉、语音识别。这一切都是关于感知和检测的。这是第一次,世界解决了生成式 AI,逐个生成 token,而这些 token 是单词。当然,有些 token 现在可以是图像、图表、表格、歌曲、单词、语音、视频。这些 token 可以是任何你能理解其意义的东西,它们可以是化学品的 token ,蛋白质的 token ,基因的 token 。你们之前在地球 2 项目中看到的,生成的是天气的 token 。
我们可以理解,我们可以学习物理。如果你能学习物理,你可以教 AI 模型物理。AI 模型可以学习物理的意义,然后可以生成物理。我们将其缩小到 1 公里,不是通过过滤,而是生成。所以我们可以用这种方法生成几乎任何有价值的 token 。我们可以为汽车生成方向盘控制,为机器人手臂生成动作。我们可以学习的一切,现在都可以生成。
▍AI 工厂
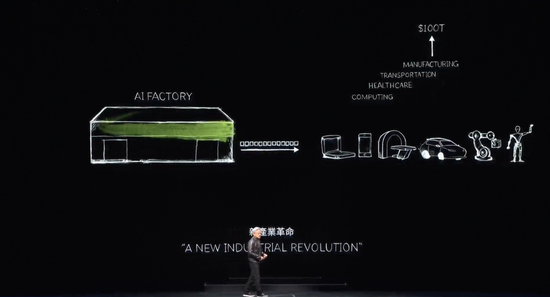
我们现在已经进入了生成式 AI 时代。但是,真正重要的是,这台最初作为超级计算机的计算机现在已经演变成了一个数据中心,它只生成一种东西,那就是 token ,它是一个 AI 工厂,这家 AI 工厂正在生成、创造和生产一种极具价值的新商品。
19 世纪 90 年代末,尼古拉·特斯拉发明了交流发电机,而英伟达发明了AI 生成器。交流发电机生成电子,英伟达 AI 生成器生成 token,这两种东西在市场上都有巨大的机会,在几乎每个行业中都是完全可以替代的,这也是为什么这是一次新的工业革命。
英伟达现在有一个新的工厂,为每个行业生产一种新的商品,这种商品具有非凡的价值。这种方法具有高度的可扩展性,并且这种方法的可重复性也非常高。
注意到每天都有这么多不同的生成式 AI 模型被发明出来。每个行业现在都在涌入。第一次,价值 3 万亿美元 IT 行业,正在创造一些可以直接服务于 100 万亿美元产业的东西。不再只是信息存储或数据处理的工具,而是一个为每个行业生成智能的工厂。这将成为一个制造业产业,但不是计算机制造业,而是使用计算机进行制造业。

这在历史上从未发生过。加速计算带来了AI,带来了生成式 AI,现在带来了工业革命。对行业的影响也非常显著,可以为许多行业创造一种新商品,一种新的产品,称之为 token ,但对我们自己的行业的影响也非常深远。
60 年来,计算的每一层都发生了变化,从 CPU 通用计算到加速 GPU 计算,计算机需要指令。现在计算机处理 LLM,AI模型。而过去的计算模型是基于检索的。几乎每次你触摸手机时,都会为你检索一些预录文本、图像或视频,并基于推荐系统重新组合并呈现给你。
黄仁勋表示,未来计算机将尽可能多地生成数据,只检索必要的信息。原因是生成的数据需要更少的能量去获取信息。生成的数据也更具上下文相关性。它将编码知识,理解你。你不再是让计算机获取信息或文件,而是让它直接回答你的问题。计算机将不再是我们使用的工具,而是生成技能,执行任务。
▍NIMs,英伟达推理微服务

而不是一个生产软件的行业,这在 90 年代初是一个革命性的想法。记得微软创造的软件包装的想法革命化了PC 行业。没有包装软件,我们会用 PC 做什么?它驱动了这个行业,现在英伟达有一个新的工厂,一个新的计算机。我们将在其上运行一种新的软件,称之为 NIMs,英伟达推理微服务。
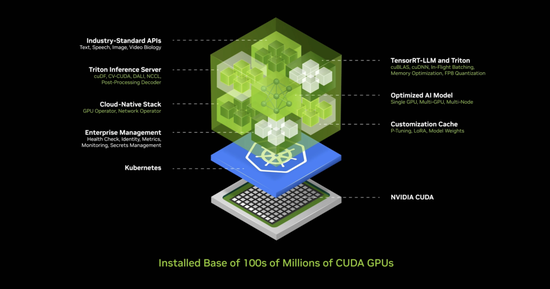
NIM 在这个工厂内部运行,这个 NIM 是一个预训练模型,它是一个AI。这个 AI 本身非常复杂,但运行 AI 的计算堆栈是极其复杂的。当你使用 ChatGPT 时,其背后的堆栈是大量的软件。其背后的提示符是大量的软件,极其复杂,因为模型庞大,有数十亿到数万亿的参数。它不仅在一台计算机上运行,而是在多台计算机上运行。它必须在多个 GPU 之间分配工作负载,使用张量并行、流水线并行、数据并行、各种并行性、专家并行性等各种并行性,在多个 GPU 之间分配工作负载,尽可能快速地处理它。
因为如果你在一个工厂里运行,你的吞吐量直接与收入相关。你的吞吐量直接与服务质量相关,你的吞吐量直接与能使用你服务的人数相关。
我们现在处于一个数据中心吞吐量利用率至关重要的世界。在过去这很重要,但没有现在重要。在过去这很重要,但人们不测量它。今天,每一个参数都被测量,启动时间、运行时间、利用率、吞吐量、空闲时间等,因为这是一个工厂。当某物是一个工厂时,其操作直接与公司的财务表现相关,这对大多数公司来说极其复杂。

所以英伟达做了什么?英伟达创建了这个 AI 盒子,这个容器里装满了大量的软件,这个容器内部包括 CUDA、cuDNN、TensorRT、Triton 推理服务。它是云原生的,可以在 Kubernetes 环境中自动扩展,它有管理服务和钩子,可以监控你的 AI。它有通用 API,标准 API,你可以与这个盒子聊天。下载这个 NIM,可以与它聊天,只要你的计算机上有 CUDA,它现在当然是无处不在的。它在每一个云中可用,来自每一个计算机制造商。它在数亿台 PC 上可用,所有的软件都整合在一起,400 个依赖项都整合在一个里面。
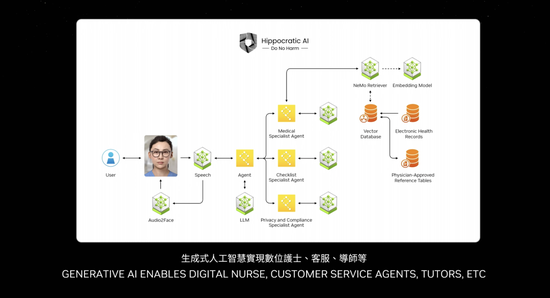
英伟达测试了这个NIM,每一个预训练模型都在整个安装基础上测试,所有不同版本的 Pascal、Ampere 和 Hopper,以及各种不同的版本。我甚至忘记了一些名字。令人难以置信的发明,这是我最喜欢的之一。
黄仁勋表示,英伟达有所有这些不同版本,无论是基于语言的还是基于视觉的,还是基于图像的,或者用于医疗保健、数字生物学的版本,有数字人类的版本,只需访问 ai.nvidia.com。
黄仁勋还表示,今天英伟达刚刚在 HuggingFace 上发布了完全优化的 Llama3 NIM,它在那里可以供你尝试,你甚至可以带走它。它免费提供给你。你可以在云中运行它,在任何云中运行。你可以下载这个容器,将其放入你自己的数据中心,并可以使其可用于你的客户。
英伟达有各种不同领域的版本,物理学,一些用于语义检索,称为 RAGs,视觉语言,各种不同的语言。你使用它们的方法是将这些微服务连接到大型应用程序中。
未来最重要的应用之一当然是客户服务。几乎每个行业都需要 Agent。这代表了数万亿美元的客户服务。护士在某些方面也是客户服务 Agent,一些非处方或非诊断性的护士基本上是零售业的客户服务,快速服务食品、金融服务、保险业。数以千万计的客户服务现在可以通过语言模型和AI增强。因此你看到的这些盒子基本上就是NIMs。
一些 NIM 是推理 Agent,给出任务,确定任务,分解成计划。一些 NIM 检索信息。一些 NIM 可能会进行搜索。一些 NIM 可能会使用工具,比如黄仁勋之前提到的 cuOpt。它可以使用在 SAP 上运行的工具。因此它必须学习一种叫做 ABAP 的特定语言。也许一些 NIM 必须进行 SQL 查询。因此,所有这些 NIM 都是专家,现在被组装成一个团队。
所以发生了什么变化?应用层发生了变化。过去用指令编写的应用程序,现在是组装AI团队的应用程序。很少有人知道如何编写程序,但几乎每个人都知道如何分解问题并组装团队。我相信未来每家公司都会有大量 NIM 集合。你会下载你想要的专家,将它们连接成一个团队,你甚至不必确切知道如何连接它们。你只需将任务交给一个 Agent,一个NIM,让它确定如何分配任务。那个团队领导 Agent 将会分解任务并分配给各个团队成员。团队成员会执行任务,将结果返回给团队领导,团队领导会对结果进行推理并将信息呈现给你,就像人类一样,这是不久的未来,应用的未来形态。
当然,可以通过文本提示和语音提示与这些大型 AI 服务互动。然而,有许多应用程序希望与人类形式互动。英伟达称之为数字人类,并一直在研究数字人类技术。
黄仁勋继续介绍,数字人类有可能成为与你互动的伟大 Agent,使互动更加引人入胜,更有同情心。当然,我们必须跨越这个巨大的现实鸿沟,使数字人类显得更加自然。想象一下未来,计算机能够像人类一样与我们互动。这就是数字人类的惊人现实。数字人类将彻底改变从客户服务到广告和游戏的各个行业。数字人类的可能性是无穷无尽的。
使用你当前厨房的扫描数据。通过你的手机,它们将成为AI室内设计师,帮助生成美丽的照片级建议,并提供材料和家具的来源。
英伟达已经为你生成了几种设计选项可供选择。它们还将成为 AI 客户服务 Agent,使互动更加生动和个性化,或数字医疗工作者,检查病人,提供及时和个性化的护理,它们甚至会成为 AI 品牌大使,设定下一波市场营销和广告趋势。
生成式 AI 和计算机图形学的新突破让数字人类能够以类似人类的方式看见、理解和与我们互动。从我所看到的情况来看,你似乎是在某种录音或制作设置中。数字人类的基础是建立在多语言语音识别和合成、以及能够理解和生成对话的LLM模型上的AI模型。
这些 AI 连接到另一个生成式 AI,以动态地动画化一个逼真的 3D 面部网格。最后,AI模型重现逼真的外观,实现实时路径跟踪的次表面散射,模拟光线如何穿透皮肤、散射并在不同点出射,使皮肤具有柔和和半透明的外观。
Nvidia Ace 是一套数字人类技术,打包成易于部署的完全优化的微服务或NIMs。开发者可以将Ace NIMs集成到他们现有的框架、引擎和数字人类体验中,Nematons SLM和LLM NIMs 理解我们的意图并协调其他模型。
Riva Speech Nims 用于交互式语音和翻译,Audio to Face 和 Gesture NIMs 用于面部和身体动画,Omniverse RTX 与 DLSS 用于皮肤和头发的神经渲染。
相当令人难以置信。这些 Ace 可以在云端运行,也可以在 PC 上运行,在所有 RTX GPU中都包括了张量核心 GPU,所以英伟达已经在出货 AI GPU,为这一天做准备。原因很简单,为了创建一个新的计算平台,首先需要一个安装基础。
最终,应用程序会出现。如果不创建安装基础,应用程序怎么会出现呢?所以如果你建造它,他们可能不会来。但如果你不建造它,他们就不能来。因此,英伟达在每一个 RTX GPU 中安装了张量核心处理器。现在英伟达在全球有 1 亿台 GeForce RTX AI PC,并且英伟达正在出货 200 台。
在本次 Computex,英伟达展示了四款新的令人惊叹的笔记本电脑。它们都能够运行AI。未来的笔记本电脑、PC 将成为一个AI。它将不断在后台帮助你、协助你。PC还将运行由AI增强的应用程序。
当然,你所有的照片编辑、写作工具、你使用的一切工具都将由AI增强。你的PC还将托管带有数字人类的 AI 应用程序。因此,AI 将在不同的方式中表现出来并被用于PC中。PC 将成为非常重要的 AI 平台。
那么我们从这里往哪里走?我之前谈到了数据中心的扩展。每次扩展时,我们都会发现一个新的飞跃。当从 DGX 扩展到大型 AI 超级计算机时,英伟达使 Transformer 能够在非常大的数据集上进行训练。一开始,数据是人工监督的,需要人工标注来训练 AI。不幸的是,人类标注的数据是有限的。Transformer 使得无监督学习成为可能。现在,Transformer 只需查看大量的数据、视频或图像,它就能通过研究大量的数据自己找到模式和关系。
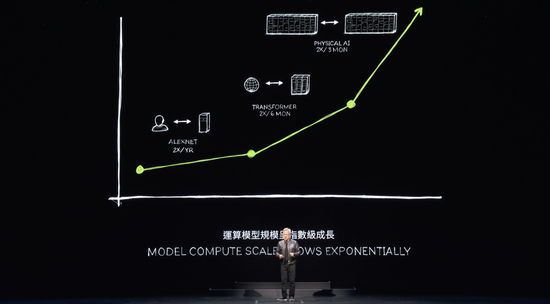
下一代 AI 需要基于物理。今天的大多数 AI 不了解物理定律,它们没有扎根于物理世界。为了生成图像、视频和3D图形以及许多物理现象,我们需要基于物理并了解物理定律的 AI。你可以通过视频学习来实现这一点,这是一种来源。
另一种方法是合成数据、模拟数据,另一种方法是让计算机相互学习。这实际上与 AlphaGo 自我对弈没有什么不同,通过相同能力的对弈,经过很长时间,它们会变得更加聪明。你将开始看到这种类型的AI出现。
如果 AI 数据是合成生成的,并使用强化学习,数据生成的速度将继续提高。每次数据生成增长,需要提供的计算量也需要增长。
我们即将进入一个阶段,AI 可以学习物理定律,并扎根于物理世界的数据中。因此,英伟达预计模型将继续增长,我们需要更大的GPU。
▍Blackwell

Blackwell 是为这一代设计的,拥有几项非常重要的技术。首先是芯片的大小。英伟达在台积电制造了最大的芯片,并将两个芯片通过每秒 10TB的连接连接在一起,世界上最先进的 SerDes 将这两个芯片连接在一起。然后英伟达将两个芯片放在一个计算节点上,通过 Grace CPU 连接。
Grace CPU 可以用于多种用途。在训练情况下,可以用于快速检查点和重启。在推理和生成情况下,可以用于存储上下文记忆,使AI了解你想要进行的对话的上下文,这是英伟达的第二代Transformer引擎,允许根据计算层所需的精度和范围动态调整精度。
这是第二代具有安全 AI 的 GPU,可以要求服务提供商保护 AI 免受盗窃或篡改。这是第五代 NVLink,允许将多个 GPU 连接在一起,我会稍后详细介绍。
这是英伟达的第一代具有可靠性和可用性引擎的 GPU。这个 RAS 系统允许测试每个晶体管、触发器、片上内存、片外内存,以便现场确定某个芯片是否故障。拥有 1 万个 GPU 的超级计算机的平均故障间隔时间是以小时计算的。拥有10 万个GPU的超级计算机的平均故障间隔时间是以分钟计算的。
因此,如果不发明技术来提高可靠性,超级计算机长时间运行并训练几个月的模型几乎是不可能的。可靠性会提高正常运行时间,从而直接影响成本。最后是解压引擎,数据处理是必须做的最重要的事情之一。英伟达添加了一个数据压缩引擎和解压引擎,使英伟达够从存储中提取数据的速度提高 20 倍,比今天可能的速度更快。

Blackwell 正在生产中,拥有大量的技术,可以看到每一个 Blackwell 芯片,两个连接在一起。你看到这是世界上最大的芯片。然后将两个芯片通过每秒 10TB 连接在一起,性能是惊人的。
英伟达的每一代计算的浮点运算能力增加了 1000 倍。摩尔定律在八年内增长大约 40~60 倍。而在过去的八年里,摩尔定律的增长速度大大减慢。即使在摩尔定律最好的时候,也无法与 Blackwell 性能相比。
计算量是惊人的。每次提高计算能力,成本就会下降。英伟达已经通过增加计算能力,将训练 GPT-4 能量需求从 1000 GWh 降低到 3 GWh。Pascal 需要 1000 GWh 的能量。1000 GWh 意味着需要一个 GW 数据中心。世界上没有一个 GW的数据中心,但如果你有一个 GW 数据中心,它需要一个月。如果你有一个100 MW 数据中心,需要大约一年。因此,没有人会建造这样的设施。
这就是为什么在八年前,像 ChatGPT 这样的 LLM 是不可能的。通过提高性能,随着能效的提高,英伟达现在将 Blackwell 的能量需求从 1000 GWh 降低到 3 GWh,这是一个令人难以置信的进步。如果是1万个GPU,例如,需要几天,可能需要10天左右。在短短八年内取得的进展是惊人的。
这部分是关于推理和生成 token 的。生成一个GPT-4 token 需要两个灯泡运行两天。生成一个单词大约需要三个 token 。因此,Pascal 生成 GPT-4 并与你进行 ChatGPT 体验所需的能量几乎是不可能的。但是现在每个 token 只使用 0.4 焦耳,并且可以以极低的能量生成 token 。

Blackwell是一个巨大的飞跃。即便如此,它还不够大。因此必须建造更大的机器。因此英伟达建造的方法叫做 DGX。

这是一个 DGX Blackwell,这是空气冷却的,内部有8个GPU。看看这些GPU上的散热片的大小,大约15千瓦,完全是空气冷却的。这一版本支持x86,并进入了英伟达一直在发货的 Hoppers 基础设施,英伟达有一个新的系统,称之为MGX,意为模块化系统。
两块Blackwell板子,一个节点有四个 Blackwell 芯片。这些 Blackwell 芯片是液冷的,72 个 GPU通过新的 NVLink 连接在一起。这是第 5 代 NVLink 交换机,NVLink 交换机本身就是一个技术奇迹,这是世界上最先进的交换机,数据速率惊人,这些交换机将每一个 Blackwell 连接在一起,因此有一个巨大的 72 个 GPU 的 Blackwell。
这样做的好处是,在一个域中,一个 GPU 域现在看起来像一个 GPU,这个 GPU 有 72个,而上一代是 8 个。因此增加了九倍的带宽。AI 浮点运算性能增加了 18 倍,提高了 45 倍。而功耗仅增加了 10 倍,这是 100 千瓦,而那是 10 千瓦。这是一个。
当然,你总是可以将更多这些连接在一起,我稍后会展示如何做到这一点。但奇迹在于这个芯片,这个 NVLink 芯片。人们开始意识到这个 NVLink 芯片的重要性,因为它连接了所有这些不同 GPU。因为 LLM 非常庞大,不能仅仅放在一个GPU上,也不能仅仅放在一个节点上。它需要整个 GPU 机架,比如我刚刚站在旁边的新DGX,它可以容纳数万亿参数的 LLM。
NVLink 交换机本身就是一个技术奇迹,拥有 500 亿个晶体管,74 个端口,每个端口 400Gbps,横截带宽 7.2Tbps。但重要的是它在交换机内有数学运算能力,这在深度学习中非常重要,可以在芯片上进行归约运算。所以这就是现在的DGX。
黄仁勋表示,许多人问,有人对英伟达的工作产生了困惑,为什么英伟达通过制造 GPU 变得如此庞大。因此有人认为这就是 GPU 的样子。
现在这是一个GPU,这是世界上最先进的GPU之一,但这是一个游戏GPU。你和我知道这就是GP的样子。这是一个GPU,女士们先生们,DGX GPU。你知道这个GPU的背面是NVLink主干。NVLink 主干有 5000 根线,两英里长,它将两个GPU连接在一起,这是一个电气、机械奇迹。收发器使能够在铜线上驱动整个长度,能够在一个机架中节省 20 千瓦的功耗。

黄仁勋表示,有两种类型的网络。InfiniBand 在全球超级计算和 AI 工厂中被广泛使用,增长速度惊人。然而,不是每个数据中心都能处理 InfiniBand,因为他们已经在其生态系统中投资了太多 Ethernet,并且管理 InfiniBand 交换机和网络需要一些专业知识。
因此英伟达将 InfiniBand 能力带到了 Ethernet 架构,这是非常困难的。原因很简单。Ethernet 是为高平均吞吐量设计的,因为每个节点,每台计算机都连接到互联网上的不同人,大多数通信是数据中心与互联网另一端的人进行的。
然而,深度学习和 AI 工厂,GPU 主要是相互通信的。它们彼此通信,因为它们在收集部分产品,然后进行归约并重新分发。部分产品的收集、归约和重新分发。这种流量是非常突发的,重要的不是平均吞吐量,而是最后一个到达的。因此英伟达创建了几项技术,创建了端到端架构,使网络接口卡和交换机可以通信,并应用了四种不同的技术来实现这一点。首先,英伟达拥有世界上最先进的 RDMA,现在能够在 Ethernet 上进行网络级 RDMA,这是非常了不起的。
第二,英伟达有拥塞控制。交换机一直在进行快速遥测,当 GPU 或网络接口卡发送太多信息时,可以告诉它们退后,以免造成热点。
第三,自适应路由。Ethernet 需要按顺序传输和接收。英伟达看到拥塞或未使用的端口,不论顺序如何,将发送到可用端口,BlueField 在另一端重新排序,以确保顺序正确,自适应路由非常强大。
最后,噪声隔离。数据中心总是有多个模型在训练或其他事情在进行,它们的噪声和流量可能相互干扰并导致抖动。因此,当一个训练模型的噪声导致最后一个到达的时间过晚时,整体训练速度会显著降低。
记住,你已经建造了一个价值 50 亿美元或 30 亿美元的数据中心,用于训练。如果网络利用率降低 40%,导致训练时间延长 20%,50 亿美元的数据中心实际上相当于一个 60 亿美元的数据中心。因此成本影响非常大。使用 Spectrum X 的 Ethernet 允许大幅提高性能,而网络基本上是免费的。
英伟达有一整条 Ethernet产品线。这是 Spectrum X800,速度为每秒51.2Tbps,256个端口。接下来的是512个端口,明年推出,称为 Spectrum X800 Ultra,再接下来是 X16。重要的理念是 X800 设计用于成千上万个 GPU,X800 Ultra 设计用于数十万个 GPU,X16 设计用于数百万个 GPU,数百万 GPU 数据中心时代即将到来。
未来几乎你与互联网或计算机的每一次互动都会在某个地方运行一个生成式AI。这个生成式AI与你合作,与你互动,生成视频、图像或文本,甚至是一个数字人类。你几乎一直在与计算机互动,总有一个生成式 AI 连接着,部分在本地,部分在你的设备上,大部分可能在云端。这些生成式 AI 还会进行大量推理能力,不是一次性的回答,而是通过多次迭代改进答案的质量。所以未来生成的内容量将是惊人的。
Blackwell当然是英伟达平台的第一代,在世界认识到生成式AI时代来临之际发布。正当世界意识到AI工厂的重要性,正值这一新工业革命的开始。英伟达得到了几乎所有 OEM、计算机制造商、云服务提供商、GPU云、主权云,甚至电信公司的支持。Blackwell 的成功、采用和热情真是难以置信。我想感谢大家。
黄仁勋继续比哦啊是,在这个惊人的增长期间,英伟达要确保继续提高性能,继续降低训练成本和推理成本,并继续扩展 AI 能力,使每家公司都能接受。英伟达推动性能的提升,成本的下降越大。Hopper 平台当然是历史上最成功的数据中心处理器,这真的是一个不可思议的成功故事。
然而,Blackwell 已经到来,每一个平台,如你所见,都包含了几样东西。你有CPU,有 GPU,有NVLink,有网络接口,还有连接所有GPU的 NVLink 交换机,尽可能大规模的域。无论能做什么,英伟达都将其连接到大规模、非常高速的交换机。
每一代产品,你会发现不仅仅是 GPU,而是整个平台。构建整个平台。将整个平台集成到一个 AI 工厂超级计算机中。然而,再将其分解并提供给世界。这样做的原因是因为你们所有人都可以创建有趣和创新的配置,并适应不同的数据中心和不同的客户需求,有些用于边缘计算,有些用于电信。所有不同的创新都是可能的,如果将系统开放,并使你们能够创新。因此英伟达设计了集成的,但将其分解提供给客户,以便可以创建模块化系统。
Blackwell 平台已经到来,英伟达的基本理念非常简单:每年构建整个数据中心,分解并以零件形式销售,将一切推向技术的极限,无论是台积电的工艺技术、封装技术、内存技术、SerDes技术、光学技术,一切都被推向极限。之后,确保所有软件都能在整个安装基础上运行。
软件惯性是计算机中最重要的事情之一。当计算机向后兼容,并与所有已创建的软件架构兼容时,你进入市场的速度会快得多。因此,当能够利用已经创建的整个软件安装基础时,速度是惊人的。

黄仁勋表示,Blackwell 已经到来,明年是 Blackwell Ultra,就像有 H100 和H200,你们可能会看到一些令人兴奋的新一代 Blackwell Ultra,推动极限。我提到的下一代 Spectrum 交换机,这是第一次实现这种飞跃,下一代平台叫做Ruben,再一年后将有 Ruben Ultra 平台。
展示的所有这些芯片都在全速开发中,100% 的开发。这是英伟达一年的节奏,所有 100% 架构兼容,英伟达正在构建的所有丰富的软件。
▍AI 机器人

让我谈谈接下来会发生什么,下一波 AI 是物理 AI,了解物理定律,能够在我们中间工作。因此,它们必须理解世界模型,理解如何解释世界,如何感知世界。它们当然还需要出色的认知能力,以便理解我们的问题并执行任务。
机器人是一个更广泛的概念。当然,当我说机器人时,通常指的是人形机器人,但这并不完全正确。一切都将是机器人。所有的工厂将是机器人化的,工厂将协调机器人,这些机器人将制造机器人产品,机器人相互协作,制造机器人产品。为了实现这一点,需要一些突破。
接下来,黄仁勋展示了一段视频,视频中提到:
机器人时代已经到来。一天内,所有移动的东西都将是自主的。世界各地的研究人员和公司正在开发由物理AI驱动的机器人,这些AI模型能够理解指令,并在现实世界中自主执行复杂任务。多模态 LLM 是突破,使机器人能够学习、感知和理解周围的世界,并规划它们的行动。
通过人类演示,机器人现在可以学习所需的技能,使用粗大和精细的运动技能与世界互动。推进机器人技术的一个关键技术是强化学习。就像 LLM 需要 RLHF来学习特定技能一样,生成物理 AI 可以使用物理反馈在模拟世界中学习技能。这些模拟环境是机器人通过在遵循物理定律的虚拟世界中执行动作来学习决策的地方。在这些机器人健身房中,机器人可以安全快速地学习执行复杂和动态的任务,通过数百万次试验和错误行为来提高技能。
英伟达构建了Nvidia Omniverse 作为物理AI的操作系统。Omniverse 是一个虚拟世界模拟开发平台,结合了实时物理渲染、物理模拟和生成式AI技术。在Omniverse 中,机器人学习如何成为机器人。它们学习如何自主精确地操控物体,比如抓取和处理物体,或自主导航环境,找到最佳路径,同时避免障碍和危险。在 Omniverse 中学习最大限度地减少模拟与现实的差距,并最大限度地转移所学行为。
构建具有生成物理AI的机器人需要三台计算机:Nvidia AI超级计算机来训练模型,Nvidia Jetson Orin 和下一代 Jetson Thor 机器人超级计算机来运行模型,以及Nvidia Omniverse,机器人可以在模拟世界中学习和改进技能。构建了开发人员和公司所需的平台、加速库和AI模型,并允许他们使用最适合的堆栈。下一波AI已经到来。由物理 AI 驱动的机器人将彻底改变各个行业。
黄仁勋提到,这不是未来,这正在发生。英伟达将通过几种方式服务市场。首先,英伟达将为每种类型的机器人系统创建平台,一个用于机器人工厂和仓库,一个用于操纵物体的机器人,一个用于移动的机器人,一个用于人形机器人。因此,每个机器人平台就像英伟达做的几乎所有事情一样,都是计算机、加速库和预训练模型。计算机、加速库、预训练模型。在 Omniverse 中测试、训练和集成所有东西,正如视频所说,机器人在这里学习如何成为机器人。
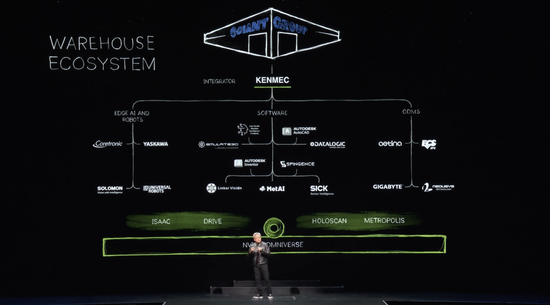
当然,机器人仓库的生态系统非常复杂。建造现代仓库需要很多公司、很多工具、很多技术,仓库正日益自动化。有一天,它们将完全自动化。因此,在每个生态系统中,都有连接到软件行业的 SDK 和 API,连接到边缘 AI 行业和公司的 SDK 和 API,以及为 Odms 设计的 PLC 和机器人系统的系统集成。这些最终由集成商集成,构建给客户的仓库。这里有一个例子,Kenmac 为 Giant 集团构建的机器人仓库。
黄仁勋继续表示,工厂有一个完全不同的生态系统,富士康正在建造一些世界上最先进的工厂。它们的生态系统再次包括边缘计算机和机器人,设计工厂的软件、工作流程、编程机器人以及协调数字工厂和 AI 工厂的 PLC 计算机。英伟达有连接到每个生态系统的 SDK,这在整个台湾都在发生。

富士康正在为其工厂建造数字孪生体。台达正在为其工厂建造数字孪生体。顺便说一下,一半是真实的,一半是数字的,一半是Omniverse。和硕正在为其机器人工厂建造数字孪生体,广达正在为其机器人工厂建造数字孪生体。
黄仁勋继续演示了一段视频,视频中提到:

随着世界将传统数据中心现代化为生成式AI工厂,对Nvidia加速计算的需求正在飙升。富士康,世界上最大的电子制造商,正准备通过Nvidia Omniverse和AI建造机器人工厂来满足这一需求。工厂规划人员使用Omniverse将来自西门子Team Center X和Autodesk Revit等领先行业应用程序的设施和设备数据集成到数字孪生体中。
在数字孪生体中,他们优化了地板布局和生产线配置,并定位了最佳相机位置,以使用Nvidia Metropolis支持的视觉AI监控未来的操作。虚拟集成节省了规划人员在建设期间巨大的物理变更订单成本。富士康团队使用数字孪生体作为准确设备布局的真实来源进行沟通和验证。
Omniverse数字孪生体也是机器人健身房,富士康开发人员在这里为机器人感知和操作训练和测试Nvidia Isaac AI应用程序,以及用于传感器融合的Metropolis AI应用程序。
黄仁勋继续表示,在Omniverse中,富士康模拟了两个机器人AI,在将运行时部署到装配线上的 Jetson 计算机之前。他们模拟了 Isaac Manipulator 库和用于自动光学检测的AI模型,以进行物体识别、缺陷检测和轨迹规划。他们还模拟了Isaac Perceptor驱动的Ferrobot AMRS,这些机器人通过3D映射和重建感知和移动他们的环境。通过Omniverse,富士康建立了运行在Nvidia Isaac上的机器人工厂,这些机器人建造了Nvidia AI超级计算机,反过来训练富士康的机器人。
一个机器人工厂设计了三台计算机。首先在Nvidia AI上训练AI,然后在PLC系统上运行机器人以协调工厂操作,最后在Omniverse中模拟一切。机器人手臂和机器人AMRS也是如此,三台计算机系统的区别在于两个Omniverse将结合在一起,共享一个虚拟空间。当它们共享一个虚拟空间时,机器人手臂将进入机器人工厂。再次强调,三台计算机,提供计算机、加速层和预训练AI模型。
英伟达将Nvidia Manipulator和Nvidia Omniverse与世界领先的工业自动化软件和系统公司西门子连接起来。这真的是一个非常棒的合作,他们正在世界各地的工厂中工作。
Semantic Pick AI现在集成了Isaac Manipulator,Semantic Pick AI运行并操作ABB、Kuka、安川、Fanuc、Universal Robotics和Techman。因此,西门子是一个绝佳的整合。
黄仁勋继续演示了一段视频,视频中提到:
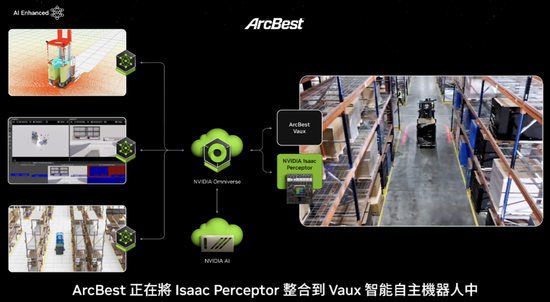
Arcbest正在将Isaac Perceptor集成到Fox智能自主机器人中,以增强物体识别和人体动作跟踪及材料处理。比亚迪电子正在将Isaac Manipulator和Perceptor集成到他们的AI机器人中,以提高全球客户的制造效率。Ideal Works正在将Isaac Perceptor集成到他们的iOS软件中,用于工厂物流中的AI机器人。
Gideon正在将Isaac Perceptor集成到托盘AI驱动的叉车中,以推进AI驱动的物流。Argo Robotics正在采用Isaac Perceptor用于高级视觉AMRS的感知引擎。Solomon正在他们的Acupic 3D软件中使用Isaac Manipulator AI模型进行工业操作。Techman Robot正在将Isaac Sim和Manipulator集成到TM Flow中,以加速自动光学检测。Teradine Robotics正在将Isaac Manipulator集成到Polyscope X用于协作机器人,并将Isaac Perceptor集成到MiR AMRS中。
Vention正在将Isaac Manipulator集成到Machine Logic中,用于AI操作机器人。机器人技术已经到来,物理AI已经到来。
黄仁勋继续介绍,这不是科幻小说,它正在整个台湾被广泛应用,真的非常令人兴奋。这是工厂,里面的机器人,当然所有产品也将是机器人化的。
有两种非常高产量的机器人产品。一种当然是自动驾驶汽车或具有高度自动驾驶能力的汽车。英伟达再次构建了整个堆栈。
明年,英伟达将与梅赛德斯车队一起投入生产。之后,在 2026 年,将是 JLR 车队。英伟达向世界提供整个堆栈。然而,你可以选择英伟达堆栈中的任何部分,任何层,就像整个 Drive 堆栈是开放的。
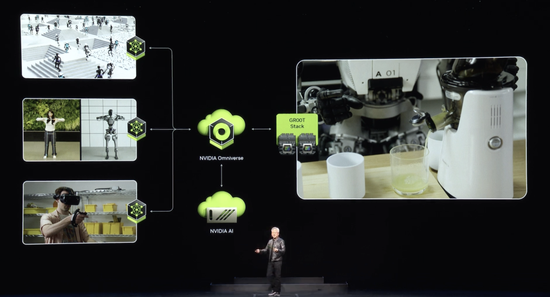
下一个将由机器人工厂内的机器人制造的高产量机器人产品可能是人形机器人。近年来在认知能力和世界理解能力方面取得了巨大进展,这要归功于基础模型和英伟达正在开发的技术。
黄仁勋表示,他对这一领域非常兴奋,因为显然,最容易适应世界的机器人是人形机器人,因为我们为自己建造了这个世界,还可以通过演示和视频提供大量的训练数据,远远超过其他类型的机器人。因此,英伟达将在这一领域看到很多进展。

下一波AI。台湾不仅制造带键盘的计算机,还制造用于口袋的计算机、用于数据中心的计算机。在未来,你们将制造会走动的计算机和四处滚动的计算机。这些都是计算机。事实证明,构建这些计算机的技术与今天你们已经构建的所有其他计算机的技术非常相似,这将是一个非常非凡的旅程。

责任编辑:尉旖涵

VIP课程推荐
APP专享直播
热门推荐
收起
24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)




