




来源:36氪

谷歌团队再创量子计算里程碑!全新量子芯片Willow,仅用不到5分就完成了当今最强超算,需要10^25年这个天文数字般的计算。困扰人类近30年量子计算纠错问题,终于被攻克了!
编辑|HYj
封面来源|Pexels
这一刻,注定将被载入史册!
12月10日,谷歌重磅推出全新的量子芯片——Willow(共105个量子比特),在AI圈掀起了海啸级巨震。
在一个标准基准计算任务,Willow用时不到5分钟(300秒)神速完成。
而如今,世界上最快超算Frontier要完成同样任务,则需要10亿亿亿年,也就是10,000,000,000,000,000,000,000,000年。
这一天文般的数字,远远超过了宇宙的年龄(138亿年)!
Willow不仅仅是速度的胜利,更取得了量子计算领域决定性的技术突破——
随着量子比特数量的增加,这款芯片的误差也呈指数级下降。这种精度提升的速率超出了一个关键阈值。
这意味着,曾困扰量子计算近30年的纠错问题,终于迎来曙光。
谷歌量子团队的最新研究,已经刊登在今天的Nature期刊上。

论文地址:https://www.nature.com/articles/s41586-024-08449-y
原本,这又是OpenAI谷歌激烈交战的一天,却在𝕏上呈现出一切祥和的另一面,劈柴奥特曼两人开始了「商业互吹」。

劈柴亲自官宣这一消息后,奥特曼第一时间送上祝贺。
他对此回应道——「量子+AI的多重宇宙未来将至,也恭喜o1发布!」

这边,劈柴还畅想了与马斯克星舰的联动——有朝一日,我们应该借助Starship在太空中建造一个量子集群。
马斯克回应,这很可能实现。

谷歌罕见地敞开了话匣子,在发布前特意召开媒体说明会。
谷歌量子AI团队的大佬们——创始人兼负责人Hartmut Neven、研究科学家Michael Newman、量子硬件主管Julian Kelly和总监兼首席运营官Carina Chou,个个亲自上阵,足见这项研究的分量。

破解30年重大难题,谷歌再创历史
Willow是在谷歌位于圣巴巴拉的最先进制造设施中生产的——这是全球为数不多的、为量子芯片量身定制的、从零开始建的工厂之一。
量子芯片的设计可不是简单的拼拼图,所有组件——从单比特门、双比特门到量子比特复位和读出——都需要精密设计与无缝集成,缺一不可。只要其中一个组件卡壳,整个系统就会掉链子。

Willow目前有105个量子比特,在量子纠错和随机电路采样这两项基准测试中表现出同类最佳的性能。
值得一提的是,Willow的T1时间(量子比特保持激发状态的时间)达到了近100微秒,比上一代约提升了5倍——这是量子计算的关键资源。
如果想跨平台比较量子硬件性能,以下是一些关键数据:

对于谷歌来说,Willow具有划时代意义。
它将成为构建有用量子计算的第一步,未来在药物发现、核聚变、电池设计等诸多领域中,带去不可估量的研究潜力。


首次实现「低于阈值」
为了让量子计算更可靠,谷歌将量子比特分组协同工作,以实现纠正错误。
每个分组形成一个d×d的量子比特网格,称为表面码,每个表面码代表一个编码的或「逻辑」量子比特。
随着晶格的增大,系统能容忍的错误也更多,理论上逻辑量子比特的保护性和性能都会提高。

随规模增加的表面码逻辑量子比特,每个都能够比前一个纠正更多的错误;编码的量子状态存储在数据量子比特阵列(黄色)上;测量量子比特(红色、青色、蓝色)用于检测相邻数据量子比特上的错误
然而,增加晶格也意味着更多的出错风险。
如果物理量子比特的错误率过高,额外增加的错误会多过纠正的错误,增加晶格反而可能拖慢处理器性能。
只有当错误率低到足够的程度,错误纠正才能发挥作用,并实现指数级的错误率下降——这就是所谓的阈值。低于阈值时,量子错误纠正从有害变为有益。

首先将数据量子比特(金色)初始化为一个已知状态,并重复进行奇偶校验检查以检测并标记错误(红色、紫色、蓝色、绿色);最后,测量数据量子比特并解码测量数据,从而得到一个经过错误纠正的逻辑测量结果
谷歌的Willow芯片打破了这个瓶颈:它不仅增加了量子比特的数量,还成功减少了误差,实现了误差率的指数级下降。
在Willow中,随着量子比特从3x3的表面码扩展到5x5、7x7,编码错误率每次减少2.14倍,实现了误差率的指数级下降。

逻辑量子比特性能随表面码规模的扩展而提升:从3×3(红色)扩展到5×5(蓝绿色)再到7×7(蓝色)时,逻辑错误概率大幅下降;Willow上的7×7逻辑量子比特的寿命是其最佳物理量子比特(绿色)的2倍,同时也是谷歌之前在Sycamore(灰色、黑色)上表面码的20倍
这个历史性的成就被领域内称为「低于阈值」——即在扩展量子比特数量时,能够降低误差率。这是量子计算领域追求了近30年的里程碑。
自1995年提出以来,「低于阈值」一直被认为是构建大规模量子计算机的关键。
更重要的是,这是首个在超导量子系统中进行实时误差修正的成功案例——这一点对任何有用的计算至关重要,因为如果无法足够快速地修正误差,计算在完成之前就会被破坏。
而且,这是首个「超越盈亏点」的演示,其中量子比特阵列的寿命超越了单个比特的寿命。这证明量子误差修正确实有效,正在全面改善系统。
Willow是首个「低于阈值」的系统,也是最强有力的可扩展量子比特原型,证明超大规模量子计算机真的能造。它让我们离那些传统计算机无法完成的实用算法更近了一大步!

5分钟计算,世界最快超算却用10亿亿亿年
为了测试Willow的性能,研究团队使用了随机电路采样(RCS)基准测试。
RCS是当前量子计算机上可以完成的计算中最难的基准测试,可以将其视为量子计算的入门测试——它检查量子计算机是否能做一些经典计算机无法做到的事情。

Willow在这个基准上的表现令人震惊:它在不到五分钟的时间内完成了一个计算,而这个计算如果由今天最快的超级计算机Frontier来完成,将需要10^25年,也就是10,000,000,000,000,000,000,000,000年。

这个令人难以置信的数字超出了物理学中已知的时间尺度,远远超过了宇宙的年龄。
它支持了量子计算发生在多个平行宇宙中的观点,这与我们生活在多元宇宙中的理论相一致,这一预测最早由大卫·德意志提出。
这些最新的Willow结果,如下图所示,是迄今为止取得的的最佳成绩,而且它还将继续进步。

计算成本受可用内存的影响很大。因此,我们的估算考虑了多种情况,从理想的无限内存环境(▲)到在GPU上实现的更实际、易于并行化的方案(⬤)
研究团队对Willow超越经典超级计算机Frontier的评估,建立在保守假设之上,比如假设Frontier拥有无带宽限制的二级存储——这显然是个不现实的理想假设。
虽然经典计算机会继续进步,但快速扩大的差距表明,量子计算正以双重指数级速度拉开差距,随着规模扩大,量子计算机将继续遥不可及地领先。

300多人,12年心血
Hartmut Neven在博客中写道:「当我在2012年创办谷歌量子AI时,我们的愿景是构建一台实用的大规模量子计算机,利用量子力学——我们今天所理解的自然操作系统——来造福社会,推动科学发现、开发有益的应用,并解决一些社会面临的重大挑战。」
Willow,是这个长期愿景中关键的一步,也是朝着商业化量子计算迈进的重要里程碑。
今天,谷歌量子AI团队拥有约300名成员,并计划扩展。他们还在加州大学圣巴巴拉分校(UCSB)建立了自己的制造设施。
如今,AI和量子计算都将被证明是我们这个时代最具变革性的技术。
特别是,先进的AI技术将在量子计算的支持下取得显著突破,而这也是谷歌将实验室命名为Quantum AI的原因。
正如在随机电路采样中所观察到的,量子算法在基本的扩展定律(Scaling Law)上具有显著优势。对于很多基础的计算任务,这些扩展优势同样适用,而这些任务对AI来说至关重要。
因此,量子计算将在以下方面将不可或缺:
收集经典计算机无法获取的训练数据
训练和优化某些学习架构
建模量子效应重要的系统
具体来说,包括帮助我们发现新药物、设计更高效的电动车电池,以及加速聚变和新能源替代品的研究进展。
这些未来改变游戏规则的应用,有很多在经典计算机上是无法实现的——它们都在等待通过量子计算来解锁。

展望未来
一旦突破阈值,设备的小幅改进将通过量子纠错被指数级放大。
例如,虽然Willow的操作保真度大约是Sycamore的2倍,但其编码错误率却改善了大约20倍。

能否构建一个近乎完美的编码量子比特?
量子错误纠正现在看起来已经初见成效,但从今天的千分之一错误率到未来所需的万亿分之一错误率之间仍然存在巨大差距。
那么,会不会是我们遇到了新的物理现象,从而阻碍我们构建量子计算机的进程呢?
为了回答这个问题,谷歌开发了一种「重复码」。
与保护所有(局部)量子错误的表面码不同,重复码仅专注于比特翻转错误,但效率更高。通过运行重复码实验并忽略其他错误类型,谷歌在采用许多与表面码相同的错误纠正原则的同时,实现了更低的编码错误率。
通俗地讲,重复码就像一个先行侦察兵,用于验证错误纠正是否能够持续降低到最终需要的近乎完美的编码错误率。
在Willow上运行重复码时,谷歌能够实现约100亿次错误纠正循环而未发现任何错误。然而,当尝试通过进一步增加编码规模来降低编码错误率时,却发现错误率停滞不前。

重复码性能随重复码规模的扩展而提升:与Sycamore相比,实现了10000倍的性能改进,但逻辑错误率在每循环约10⁻¹⁰时达到了一个瓶颈
如何提升纠错量子计算机的速度?
与正在使用的经典设备相比,纠错量子计算机的速度实际上非常之慢。
即便是超导量子计算机——目前最快的量子比特技术之一,其测量时间也长达约一微秒。相比之下,经典计算的亚纳秒级操作时间则快了超过1000倍。
而量子纠错操作,就更慢了。部分原因在于,现在还需要依靠「量子错误解码器」这一经典软件来解释测量结果进而识别错误。
在超导量子比特领域,谷歌首次展示了能够与设备同步实时解码测量信息的能力。但即使解码速度能够跟上设备,对于某些纠错操作,解码器仍可能拖慢整体速度。
目前,谷歌在设备上测得解码延迟时间为50至100微秒,并预计这种延迟会随着晶格规模的增大而进一步增加。这种延迟可能会显著影响纠错操作的速度。
如果想让量子计算机成为一种能够用于科学发现的实用工具,就必须对此加以改进。
接下来是什么?
通过量子纠错,我们原则上已经能够扩展系统,实现近乎完美的量子计算。
然而在实践中,这并不容易——距离构建大规模、容错的量子计算机的目标仍有很长的路要走。
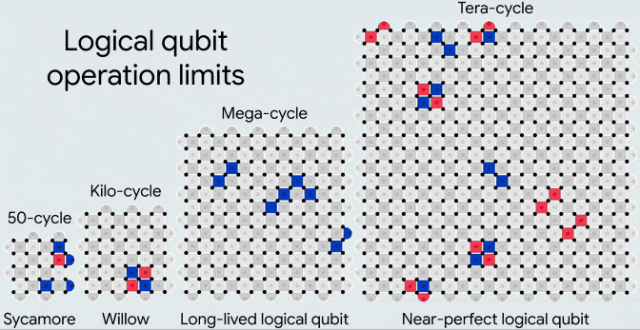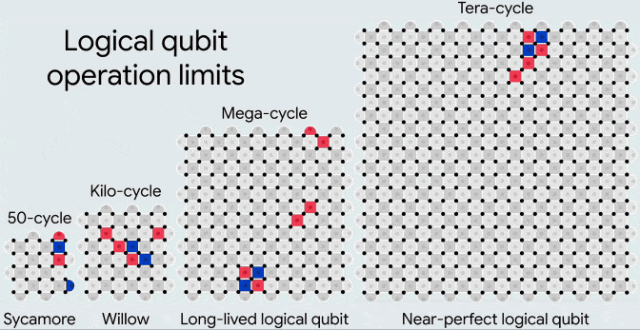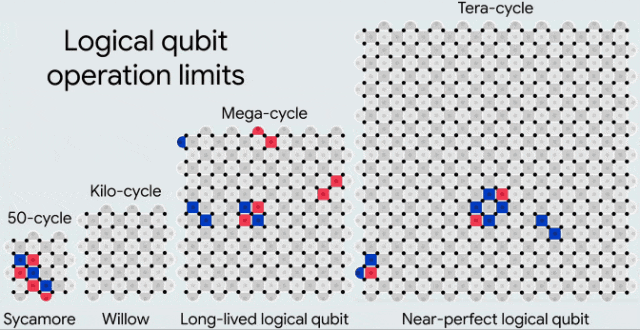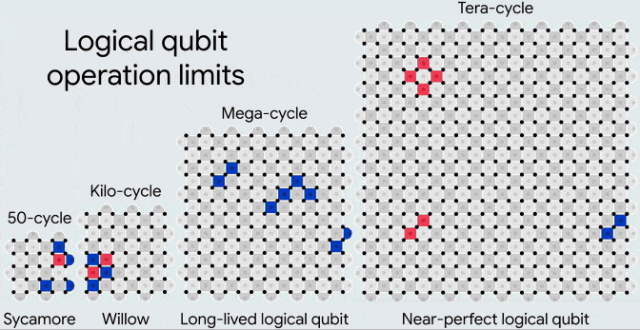
在逐步改进的处理器上,实现了逻辑量子比特,每次升级时物理量子比特的数量翻倍,且处理器规模逐渐增大。红色和蓝色方块表示用于检测附近错误的奇偶性检查。这些处理器分别能够可靠地执行大约50次、10³次、10⁶次和10¹²次循环
以当前的物理错误率来看,要实现相对适中的编码错误率(10⁻⁶),我们可能需要每个表面码网格使用超过一千个物理量子比特。
目前,所有这些都是在一个拥有105个量子比特的处理器上实现的。那么,我们是否能够在拥有1000个量子比特的处理器上实现相同的性能?如果是拥有一百万个量子比特的处理器呢?
虽然面临的工程挑战是前所未有的,但进展也令人瞩目。毕竟,量子纠错所带来的改进是指数级的。
自去年以来,谷歌的编码性能已经提升了20倍——还需要多少个这样的20倍,才能运行大规模的量子算法?
或许,答案比我们想象中要少得多。
参考资料:
https://research.google/blog/making-quantum-error-correction-work/
https://blog.google/technology/research/google-willow-quantum-chip/



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











