




机器之心PRO · 会员通讯 Week 43
---- 本周为您解读 ③个值得细品的 AI & Robotics 业内要事 ----
1. 微调失格?持续反向传播算法将解锁新的训练范式吗?
当前深度学习有什么根本缺陷?微调将来不存在了?Dynamic DL 是什么?反向传播算法是什么?持续学习在 LLM中有哪些进展?反向传播算法会解锁新的训练范式吗?...
2. 从卷文本到卷多模态:国内的大模型公司都在忙什么?
MLLM 和 LMM 两种不同思路,哪种更有可能实现多模态交互?未来的通用智能是否一定是多模态智能?在多模态的竞争中,AI 大模型创企、科技大厂、多模态大模型服务厂商推出的产品表现如何?在布局上,有哪些异同?为什么说虽然产品数据表现亮眼,但距离实现 PMF 还仍有很长的一段路要走?...
3. 三季度对生成式 AI 投资超 39 亿美元:风投仍看好 AI 的长期潜力
第三季度,生成式 AI 的融资情况如何?哪些领域的公司融资情况更好?为何处于早期融资轮次阶段的 AI 创企融资更加困难?有哪些大额融资事件值得关注?为什么投资者依然看好 AI 的长期增长潜力?....
...本期完整版通讯含 3 项专题解读 + 28 项本周 AI & Robotics 赛道要事速递,其中技术方面 10 项,国内方面 8 项,国外方面 10 项。
本期通讯总计 23576 字,可免费试读至 10%
消耗 99 微信豆即可兑换完整本期解读(约合人民币 9.9 元)
要事解读① 微调失格?持续反向传播算法将解锁新的训练范式吗?
引言:深度学习先驱 Richard S。Sutton 近期在 Amii(阿尔伯塔机器学习学院)发表演讲,指出当前的深度学习方法存在根本上的缺陷,进而分享了他对更好的深度学习的愿景,并将新的范式命名为 Dynamic Deep Learning。他在该愿景下提出了反向传播算法,解决了当前持续学习中模型可塑性丧失的问题,并为未来能适应动态环境的深度学习网络指出了可行的方向。
Sutton:现在的深度学习在根本上有缺陷?[31]
大型语言模型会在大型通用训练集上进行训练,然后在针对特定应用或满足政策和安全目标的较小数据集上进行微调,但最后在网络投入使用前会冻结其权重。就目前的方法而言,当有新数据时,简单地继续对其进行训练通常是无效的。新数据的影响要么太大,要么太小,无法与旧数据适当平衡。[32]
1、Sutton 在演讲的开头就直观地介绍了他对深度学习的愿景,他将其称为 Dynamic Deep Learning(动态深度学习),而这种动态是为了让深度学习适应持续学习的环境。
① Sutton 强调了持续学习的重要性,即学习应该在每个时刻都在进行。持续学习更接近自然学习过程,所有自然系统(如动物和人类)都在持续学习,而不是在特定阶段学习。
② 当前的深度学习是瞬态学习(Transient Learning),其在一个特殊的训练阶段学习,且算法会在持续学习环境中失败,失去可塑性,产生灾难性遗忘,并在强化学习策略中崩溃。
2、围绕让深度学习更好地适应持续学习环境的愿景,Sutton 提出了 Dynamic Deep Learning 的范式。
① Dynamic DL 的网络被分为主干(Backbone)和边缘(Fringe)两部分。
② Backbone 是网络中已经学习且对当前功能重要的部分,应当被保护和保留。Fringe 则是网络中动态和探索性的部分,它试图生成对 Backbone 有用的特征。
3、Dynamic DL 的网络是动态地逐步构建的,通过逐个单元的增长来实现,而非预先设定的固定结构。如果 Fringe 生成的特征对 Backbone 有用,它就可以成为 Backbone 的一部分。
4、Sutton 进而探讨了寻找、保护和缓慢增长 Backbone 的新想法,以及通过「印记」(imprinting)、「主单元」(master units)和「影子权重」(shadow weights)、「效用传播」(Utility Propagation)、「持续反向传播算法」(Continual Backpropagation)以及「步长优化」(Step Size Optimization)在边缘创建特征的新想法。
5、Sutton 强调他在演讲中的分享的工作仅仅是实现 Dynamic DL 的第一步,尚不完整。他的想法建立于许多已完成的工作,部分研究已经发表,而其他案例则出现在别人的论文中。
① Sutton 在演讲中提到了一种持续反向传播方法。该方法出自 Sutton 团队 8 月 21 日发表于 Nature 上的论文《Loss of plasticity in deep continual learning》,该工作解决了深度学习网络在持续学习环境中会失去可塑性的问题。[32]
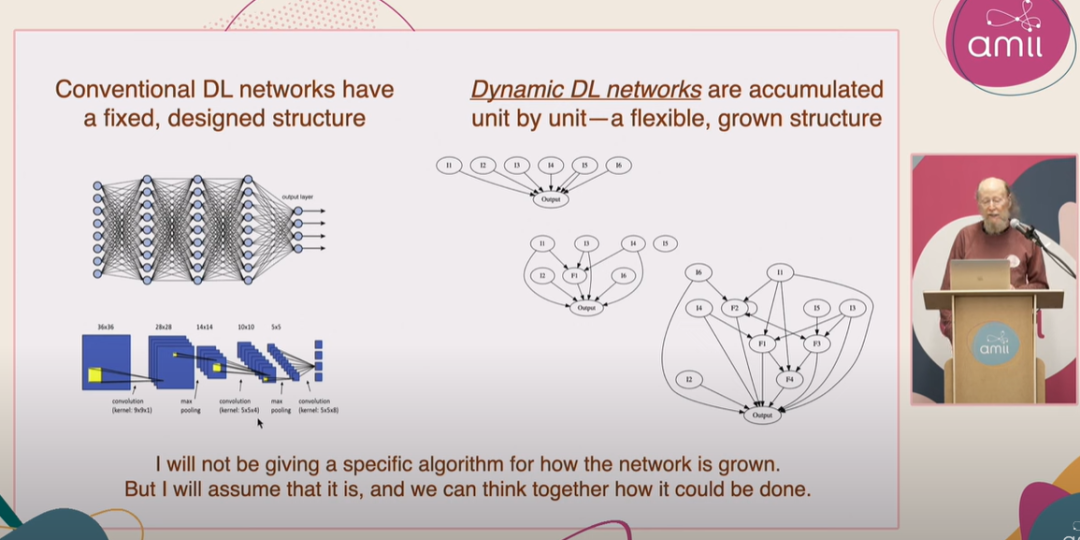
图:Sutton 演讲中展示 Dynamic Deep Learning 网络的特征。这种网络会逐个单元积累,从只有一个输出节点和许多输入开始成长,不断引入中间的特征单元(有用的 Fringe),然后不断增加 Bakebone 单元,最终成为一个大型的多层网络。[31]
持续反向传播算法了解一下?[32]
持续反向传播算法最初由 Sutton 在 CoLLAs 2022 会议中,题为「Maintaining Plasticity in Deep Continual Learning」 的演讲中提出[33] 。而后,Sutton 团队在 2024 年 9 月于《Nature》发表论文《Loss of plasticity in deep continual learning》,阐述了持续反向传播的技术细节。[32]
1、持续反向传播算法是 Sutton 团队提出的一种反向传播的变体,解决标准深度学习方法在持续学习环境中遇到的可塑性丧失问题。
① 现有方法往往是一个阶段更新网络权重,另一个阶段在使用或评估网络时权重保持不变。这与许多需要持续学习的应用程序形成鲜明对比。
② 持续反向传播算法的核心思想是选择性地对网络中贡献效用(contribution utility)较低的的单元进行初始化处理,从而向网络注入可变性并保持其某些权重较小,实现无限期地保持深度网络的可塑性(Plasticity)。
2、选择性初始化的思想受到了 2012 年 Mahmood 和 Sutton 提出的生成和测试方法的启发。该方法只需要生成一些神经元并测试它们的实用性。持续反向传播算法将这一概念扩展到多层网络,并使用深度学习方法进行优化。[34]
3、该工作定义了一个名为「贡献效用」的值来衡量每个单元的重要性。贡献效用通过计算即时贡献的移动平均值来衡量,这个值由衰减率表示。
① 如果一个隐藏单元对下游单元的影响很小,那么它的作用可能会被网络中其他更有影响力的隐藏单元掩盖。
② 在前馈神经网络中,每个隐藏单元的贡献效用会根据其输出和下游单元的权重进行更新。当一个隐藏单元被重新初始化时,它的输出权重将被初始化为零,以确保新添加的隐藏单元不会影响模型已经学到的功能。
4、为了防止新的隐藏单元很快被重新初始化,研究团队设置了「成熟阈值」(maturity threshold),在一定次数的更新前,即使新的隐藏单元的效用是零,也不会被重新初始化。
① 当更新次数超过成熟阈值后,每一步中会有一定比例的「成熟单元」(mature unit)被重新初始化。这个比例称为替换率,通常设置为一个非常小的值,这意味着在数百次更新后只替换一个单元。
5、最终的持续反向传播算法结合了传统的反向传播和选择性重新初始化两种方法,以持续地从初始分布中引入随机单元。每次更新时,持续反向传播将执行梯度下降并选择性地重新初始化。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











