




AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
OpenR 研究团队成员包括:汪军教授,伦敦大学学院(UCL)计算机系教授,阿兰・图灵研究所 Turing Fellow,其指导的 UCL 一年级博士生宋研。利物浦大学助理教授方蒙。上海交通大学 Apex 和多智能体实验室张伟楠教授(上海交通大学计算机系教授、博士生导师、副系主任),温颖副教授(上海交通大学约翰・霍普克罗夫特计算机科学中心副教授)以及其指导的博士生万梓煜、温睦宁、朱家琛。张伟楠教授和温颖副教授博士期间就读于 UCL,指导教师为汪军教授。香港科技大学(广州)创校校长,倪明选(Lionel M. Ni),香港工程科学院院士,香港科技大学(广州)讲席教授。陈雷,香港科技大学(广州)信息枢纽院长,讲席教授。香港科技大学(广州)一年级博士生刘安杰、龚子钦受汪军教授和杨林易博士联合执导,以及西湖大学工学院助理教授(研究)杨林易。
o1 作为 OpenAI 在推理领域的最新模型,大幅度提升了 GPT-4o 在推理任务上的表现,甚至超过了平均人类水平。o1 背后的技术到底是什么?OpenAI 技术报告中所强调的强化学习和推断阶段的 Scaling Law 如何实现?
为了尝试回答这些问题,伦敦大学学院(UCL)、上海交通大学、利物浦大学、香港科技大学(广州)、西湖大学联合开源了首个类 o1 全链条训练框架「OpenR」,一个开源代码库,帮助用户快速实现构建自己的复杂推断模型 。整个项目由 UCL 汪军教授发起和指导,实验主要由上海交大团队完成。

我们介绍了 OpenR,首个集过程奖励模型(PRM)训练、强化学习、多种搜索框架为一身的类 o1 开源框架,旨在增强大型语言模型(LLM)的复杂推理能力。
论文链接:https://github.com/openreasoner/openr/blob/main/reports/OpenR-Wang.pdf
代码链接:https://github.com/openreasoner/openr
教程链接:https://openreasoner.github.io/
OpenR 将数据获取、强化学习训练(包括在线和离线训练)以及非自回归解码集成到一个统一的平台中。受到 OpenAI 的 o1 模型成功的启发, OpenR 采用了一种基于模型的方法,超越了传统的自回归方法。我们通过在 MATH 数据集上的评估来展示 OpenR 的有效性,利用公开的数据和搜索方法。初步实验表明,相对改进达到了显著提升。我们开源了 OpenR 框架,包括代码、模型和数据集,我们旨在推动推理领域开源社区的发展,欢迎感兴趣的从业人员加入到我们的开源社区。代码、文档、教程可通过 https://openreasoner.github.io 访问。
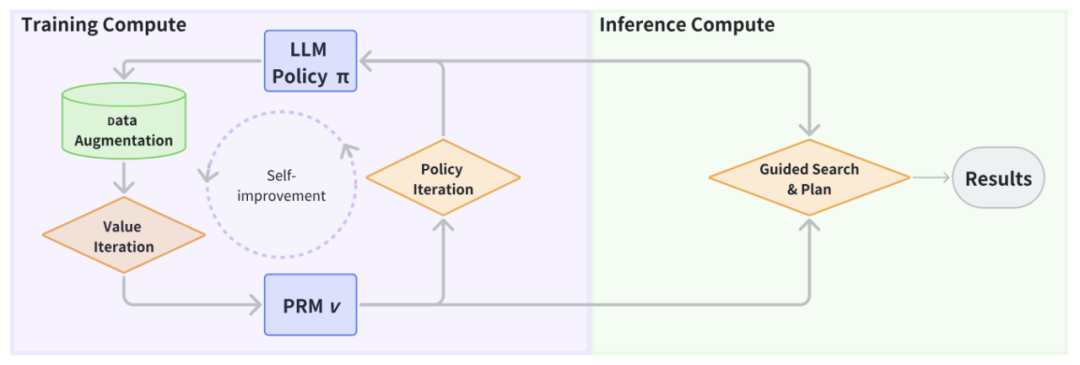
系统设计。过程奖励模型 (PRM) 在两个关键方面增强了 LLM 的策略。首先,在训练期间,PRM 通过策略优化技术(如上图所示的策略迭代)改进 LLM 策略。其次,在解码阶段,PRM 引导 LLM 的搜索过程,使推理朝着更有效的结果发展(如上图所示)。接下来我们将展示,LLM 策略还可以帮助识别缺失的中间推理步骤,这反过来又可以进一步训练和改进 PRM。正如上图所示,这种迭代的互动使 LLM 和 PRM 能够持续地释放各自的潜力以改进推理。


数据增强.在使用 LLM 进行推理时,我们不仅仅依赖最终答案的反馈,而是使用更详细的反馈方式,逐步收集和标注数据。这样可以在问题解决的过程中,识别出具体的错误位置并给出反馈,从而帮助模型更好地学习和改进。
MATH-APS.我们通过自动生成合成样本来增强数据。与依赖昂贵且难以扩展的人工标注的 PRM800k 数据集不同,我们引入了一个新数据集 MATH-APS。这个数据集基于 MATH 数据集,并使用 OmegaPRM 等自动化方法来生成样本,从而减少了对人工标注的依赖,更易于大规模收集数据。自动化方法如 OmegaPRM、Math-Shepherd 和 MiPS 可以高效地收集高质量的过程监督数据。虽然 Math-Shepherd 和 MiPS 提供了过程监督的自动化标注,但它们需要大量的策略调用,计算成本较高。OmegaPRM 改进了这个过程,通过迭代地划分解决方案、回溯分析并找出模型推理中的第一个错误步骤来提高效率。
我们通过自动生成合成样本来增强数据。与依赖昂贵且难以扩展的人工标注的 PRM800k 数据集不同,我们引入了一个新数据集 MATH-APS。这个数据集基于 MATH 数据集,并使用 OmegaPRM 等自动化方法来生成样本,从而减少了对人工标注的依赖,更易于大规模收集数据。自动化方法如 OmegaPRM、Math-Shepherd 和 MiPS 可以高效地收集高质量的过程监督数据。虽然 Math-Shepherd 和 MiPS 提供了过程监督的自动化标注,但它们需要大量的策略调用,计算成本较高。OmegaPRM 改进了这个过程,通过迭代地划分解决方案、回溯分析并找出模型推理中的第一个错误步骤来提高效率。
PRM 的监督训练。在过程奖励模型 (PRM) 中,主要目的是判断解决方案的步骤是否在正确的轨道上。因此,PRM 会输出一个 0 到 1 之间的分数,作为当前解决过程的正确性指标。具体来说,给定一个问题及其解决步骤序列,PRM 会为每一步计算出一个分数,这可以视为一个二元分类任务:是否正确。我们通过在大型语言模型 (LLM) 上的监督微调来训练 PRM,将正确或错误的判定作为分类标签,并进一步使用 LLM 来预测每一步的后续标记。
Math-psa PRM 通过在 LLM 上的监督微调来训练,正确 / 错误的区分作为分类标签。我们使用数据集如 PRM800K,Math-Shepherd 以及我们自己的 MATH-APS 数据集来训练一个名为 Math-psa 的 PRM。这些数据集由三个部分组成:问题、过程 和 标签。输入由 问题 和 过程 的拼接组成。在 过程 中,解决方案被分为多个步骤,每个步骤用一个特殊的步骤标记分隔,以标记每个步骤结束的位置,PRM 可以在此处进行预测。标签对整个过程进行分类,根据解决方案的正确性将每个步骤标记为 + 或 -。
在训练过程中,模型会在每个步骤标记之后预测正或负标签。输入的拼接格式包含了 问题 和各个步骤之间的标记符。标签仅分配在步骤标记符的位置,并在计算损失时忽略其他位置。这种方式确保模型训练时主要关注输入序列,而不会被步骤标记符干扰,从而更好地识别和分类正确性。
LLM 的策略学习。我们将数学问题转换为一个语言增强的决策过程,用来逐步解决问题。这个过程叫做马尔可夫决策过程 (MDP),它由状态、动作和奖励组成。在这个框架中,每一个数学问题就是初始状态,模型生成推理步骤作为动作,然后根据当前状态和动作来决定下一个状态。
模型每完成一个步骤,就会得到一个奖励或反馈,用来评估该步骤是否正确。这个奖励帮助模型判断是否朝着正确方向前进。整个过程重复进行,模型会不断调整其推理路径,目标是获得尽可能多的正面反馈或奖励。
我们将这种 MDP 实现为一个强化学习环境,类似 OpenAI 的 Gym 环境。在这里,每个数学问题都被看作一个任务,模型通过一系列连续的推理步骤来解决这些问题。正确的步骤获得奖励,错误的步骤则受到惩罚。通过这种方式,模型可以在不断试错中优化其策略,从而逐渐提高其解决数学问题的能力。
在线强化学习训练。在使用强化学习训练大型语言模型 (LLM) 时,通常使用近端策略优化 (PPO) 来使生成的语言输出与预期的动作对齐。PPO 可以帮助模型生成既符合语境又达到目标的响应,填补了语言理解和操作输出之间的空隙。我们提供了传统的 PPO 和一种更高效的变体,即群体相对策略优化 (GRPO)。这两者主要在优势值的计算方法上不同:PPO 使用一个网络来估算状态值,并通过广义优势估算 (GAE) 技术来计算优势值;而 GRPO 则简化了这个过程,直接使用标准化的奖励信号来估算动作的优势,从而减少了训练资源的消耗,同时更加注重奖励模型的稳定性。
解码:推理时的引导搜索和规划
我们使用 PRM 来评估每个解决步骤的准确性。一旦训练出高质量的过程奖励模型,我们就可以将其与语言模型结合到解码过程中,从而实现引导搜索和多次生成的评分或投票。
为了将 PRM 用作验证器,我们定义了评估 LLM 生成的解决方案正确性的方法,将每一步的得分转换为最终分数。主要有两种方法:
PRM-Min:选择所有步骤中得分最低的作为最终分数。
PRM-Last:选择最后一步的得分作为最终分数。这种方法已经被证明效果与 PRM-Min 相当。
当通过扩大推理时计算生成多个答案后,我们需要基于分数选择最佳答案。我们采用了三种策略:
1. 多数投票:通过统计出现最多的答案作为最终答案。
2. RM-Max:根据结果奖励模型,选择最终奖励最高的答案。
3. RM-Vote:根据结果奖励模型,选择奖励总和最高的答案。
通过结合这些策略,可以形成多种加权方法,例如 PRM-Last-Max,即使用 PRM-Last 和 RM-Max 组合进行选择。我们的框架允许我们在多种搜索算法中进行选择,例如 Beam Search、Best-of-N, 蒙特卡洛树搜索等。每种算法在 PRM 的质量上有其独特的优势。复杂的搜索算法在处理更难的任务时可能表现更好,而简单的方法如最佳 N 则常能在难度较低的情况下表现良好。
解码阶段的 Scaling Law
我们观察到了和 OpenAI o1 以及 Deepmind 论文《Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters》趋势相近的 Test-time Scaling Law,参见:
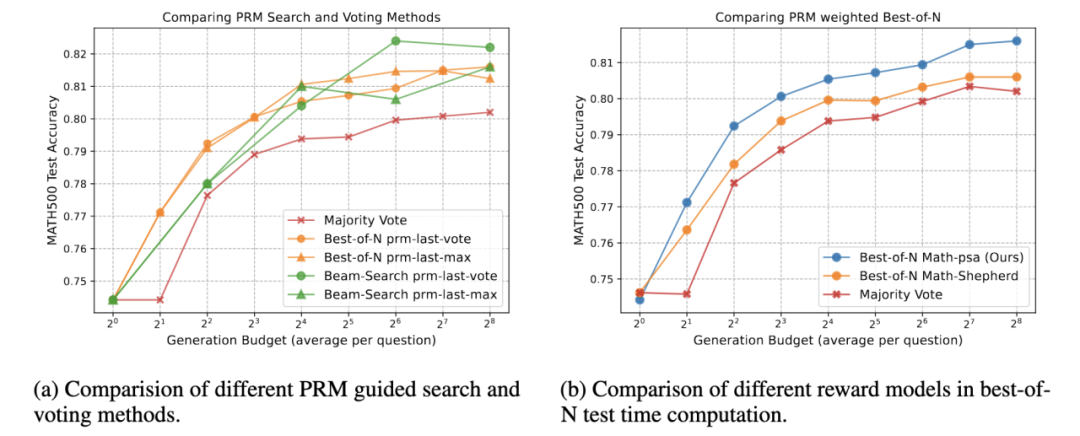 图 3 推断阶段新的缩放率实验效果图
图 3 推断阶段新的缩放率实验效果图图 3 (a) 比较了这些搜索和投票方法在推理过程中的性能。y 轴表示 MATH500 数据集上的测试准确率,而 x 轴显示生成预算(每个问题的平均标记数),反映了每个问题的计算消耗或标记使用情况。该图表明,随着生成预算的增加,最佳 N 选择和束搜索方法的性能显著优于多数投票,与之前的发现表现出相似的模式。在低推理时计算预算下,最佳 N 选择方法表现优于束搜索,而束搜索在较高预算下可以达到相同的性能。另一方面,图 (b) 显示我们的 PRM (Math-aps) 能在所有测试的计算预算下达到最高的测试准确率。这确实验证了我们的 PRM 训练能够有效地学习过程监督。
详细的文档结束。OpenR 支持使用几行代码即可实现 PRM 的训练、强化学习训练,以及不同的解码方法,使用户能够方便地进行实验和测试。我们还提供了详细的代码文档供大家参考,参见: https://openreasoner.github.io/ 。我们所支持的算法如下图所示:
 图 4 开源代码算法实现框图
图 4 开源代码算法实现框图 图 5 OpenR 技术文档图
图 5 OpenR 技术文档图


“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











