




自从 Transformer 模型问世以来,试图挑战其在自然语言处理地位的挑战者层出不穷。
这次登场的选手,不仅要挑战 Transformer 的地位,还致敬了经典论文的名字。
再看这篇论文的作者列表,图灵奖得主、深度学习三巨头之一的 Yoshua Bengio 赫然在列。

论文标题:Were RNNs All We Needed?
论文地址:https://arxiv.org/pdf/2410.01201v1
最近,大家重新对用循环序列模型来解决 Transformer 长上下文的问题产生了兴趣,出现了一大批有关成果,其中 Mamba 的成功引爆了 AI 圈,更是点燃了大家的研究热情。
Bengio 和他的研究团队发现,这些新的序列模型有很多共同点,于是他们重新审视了 LSTM 和 GRU 这两种经典 RNN 模型。
结果发现,精简掉其中的隐藏状态依赖之后,不再需要基于时间反向传播的 LSTM 和 GRU 的表现就能和 Transformer 打个平手。
LSTM 和 GRU 仅能顺序处理信息,并且在训练时依赖反向传播,这使得它们在处理大量数据时速度缓慢,最终被淘汰。
基于以上发现,他们进一步简化了 LSTM 和 GRU,去掉了它们对输出范围的限制,并确保它们的输出在时间上是独立的,进而得到了 minLSTM 和 minGRU。
相比传统 RNN,它们不仅训练时所需的参数显著减少,还可以并行训练,比如上下文长度为 512 时,速度能提升 175 倍。
这其实也是 Bengio 长期关注 RNN 的系列研究成果。在今年五月,Bengio 及其研究团队和加拿大皇家银行 AI 研究所 Borealis AI 合作发布了一篇名为《Attention as an RNN》的论文。
正如论文名字所示,他们将注意力机制重新诠释为一种 RNN,引入了一种基于并行前缀扫描(prefix scan)算法的新的注意力公式,该公式能够高效地计算注意力的多对多(many-to-many)RNN 输出。基于新公式的模块 Aaren,不仅可以像 Transformer 一样并行训练,还可以像 RNN 一样高效更新。
简化 LSTM 和 GRU
在这一部分,研究者通过简化和移除各种门中的若干隐藏状态依赖关系,证明 GRU 和 LSTM 可通过并行扫描进行训练。
在此基础上,研究者进一步简化了这些 RNN,消除了它们对输出范围的限制(即 tanh),并确保输出在规模上与时间无关。
综合上述步骤,研究者提出了 GRUs 和 LSTMs 的最小版本(minGRUs 和 minLSTMs),它们可通过并行扫描进行训练,且性能可与 Transformers 和最近提出的序列方法相媲美。
minGRU
研究者结合了两个简化步骤,得到了一个极简版的 GRU(minGRU)。

由此产生的模型比原始 GRU 效率大大提高,只需要

个参数,而不是 GRU 的

个参数(其中 d_x 和 d_h 分别对应于 x_t 和 h_t 的大小)。在训练方面,minGRU 可以使用并行扫描算法进行并行训练,从而大大加快训练速度。
在实验部分,研究者展示了在 T4 GPU 上,当序列长度为 512 时,训练步骤的速度提高了 175 倍。参数效率的提高也非常显著。通常,在 RNN 中会进行状态扩展(即
,其中 α ≥ 1),使模型更容易从输入中学习特征。
minLSTM
研究者结合了三个简化步骤,得到 LSTM 的最小版本(minLSTM):

与 LSTM 的

相比,最小版本(minLSTM)的效率明显更高,只需要

个参数。此外,minLSTM 可以使用并行扫描算法进行并行训练,大大加快了训练速度。例如,在 T4 GPU 上,对于长度为 512 的序列,minLSTM 比 LSTM 加快了 235 倍。在参数效率方面,当 α = 1、2、3 或 4(其中
)时,与 LSTM 相比,minLSTM 仅使用了 38%、25%、19% 或 15% 的参数。
Were RNNs All We Needed?
在本节中,研究者将对最小版本(minLSTMs 和 minGRUs)与传统版本(LSTMs 和 GRUs)以及现代序列模型进行了比较。
Minimal LSTMs 和 GRU 非常高效
在测试时,循环序列模型会按顺序推出,从而使其推理更为高效。相反,传统 RNN 的瓶颈在于其训练,需要线性训练时间(通过时间反向传播),这导致其最终被淘汰。人们对循环序列模型重新产生兴趣,是因为许多新的架构可以高效地进行并行训练。
研究者对比了训练传统 RNN(LSTM 和 GRU)、它们的最小版本(minLSTM 和 minGRU)以及一种最新的序列模型所需的资源,还特别将重点放在与最近大受欢迎的 Mamba 的比较上。实验考虑了 64 的批大小,并改变了序列长度。研究者测量了通过模型执行前向传递、计算损失和通过后向传递计算梯度的总运行时间和内存复杂度。
运行时间。在运行时间方面(见图 1(左)),简化版 LSTM 和 GRU(minLSTM 和 minGRU)Mamba 的运行时间相近。对 100 次运行进行平均,序列长度为 512 的 minLSTM、minGRU 和 Mamba 的运行时间分别为 2.97、2.72 和 2.71 毫秒。
对于长度为 4096 的序列,运行时间分别为 3.41、3.25 和 3.15 毫秒。相比之下,传统的 RNN 对应程序(LSTM 和 GRU)所需的运行时间与序列长度成线性关系。对于 512 的序列长度,在 T4 GPU 上,minGRUs 和 minLSTMs 每个训练步骤的速度分别比 GRUs 和 LSTMs 快 175 倍和 235 倍(见图 1(中))。随着序列长度的增加,minGRUs 和 minLSTMs 的改进更为显著,在序列长度为 4096 时,minGRUs 和 minLSTMs 的速度分别提高了 1324 倍和 1361 倍。因此,在 minGRU 需要一天才能完成固定数量的 epoch 训练的情况下,其传统对应的 GRU 可能需要 3 年多的时间。

内存。通过利用并行扫描算法高效地并行计算输出,minGRU、minLSTM 和 Mamba 创建了一个更大的计算图,因此与传统的 RNN 相比需要更多内存(见图 1(右))。与传统的 RNN 相比,最小变体(minGRU 和 minLSTM)多用了 88% 的内存。与 minGRU 相比,Mamba 多用了 56% 的内存。但实际上,运行时间是训练 RNN 的瓶颈。
删除

的效果。最初的 LSTM 和 GRU 使用输入 x_t 和之前的隐藏状态
计算各种门电路。这些模型利用其与时间依赖的门来学习复杂函数。然而,minLSTM 和 minGRU 的训练效率是通过放弃门对之前隐藏状态
的依赖性来实现的。因此,minLSTM 和 minGRU 的门仅与输入 x_t 依赖,从而产生了更简单的循环模块。因此,由单层 minLSTM 或 minGRU 组成的模型的栅极是与时间无关的,因为其条件是与时间无关的输入

与时间无关,但其输出

与时间有关,并被用作第二层的输入,即
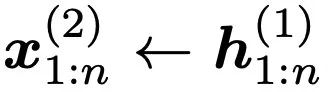
。因此,从第二层开始,minLSTM 和 minGRU 的门也将随时间变化,从而建立更复杂的函数模型。表 1 比较了不同层数的模型在 Mamba 论文中的选择性复制任务上的表现。可以立即看出时间依赖性的影响:将层数增加到 2 层或更多,模型的性能就会大幅提高。

训练稳定性。层数的另一个影响是稳定性增强,随着层数的增加,准确率的差异减小(见表 1)。此外,虽然 minLSTM 和 minGRU 都能解决选择性复制任务,但可以看到 minGRU 是一种经验上比 minLSTM 更稳定的方法,它能以更高的一致性和更低的方差解决该任务。在训练过程中,这两组参数的调整方向不同,使得比率更难控制和优化。相比之下,minGRU 的信息丢弃和添加由单组参数(更新门)控制,因此更容易优化。
Minimal LSTMs 和 GRUs 表现良好
上述内容展示了简化传统 RNN 所带来的显著效率提升。这部分将探讨最小版本的 LSTM 和 GRU 与几种流行的序列模型相比的经验性能。
选择性复制。此处考虑 Mamba 论文中的长序列选择性复制任务。与最初的复制任务不同,选择性复制任务的输入元素相对于输出元素是随机间隔的,这增加了任务的难度。为了解决这个任务,模型需要进行内容感知推理,记忆依赖的 token 并过滤掉不依赖的 token。
表 2 将简化版的 LSTM 和 GRU(minLSTM 和 minGRU)与可以并行训练的著名循环序列模型进行了比较:S4、H3、Hyena 和 Mamba (S6)。这些基线的结果引自 Mamba 论文。在所有这些基线中,只有 Mamba 论文中的 S6 能够解决这一任务。minGRU 和 minLSTM 也能解决选择性复制任务,其性能与 S6 相当,并优于所有其他基线。LSTM 和 GRU 利用内容感知门控机制,使得这些最小版本足以解决许多热门序列模型无法解决的这一任务。

强化学习。接下来,研究者讨论了 D4RL 基准中的 MuJoCo 运动任务。具体来说考虑了三种环境:HalfCheetah、Hopper 和 Walker。对于每种环境,模型都在三种不同数据质量的数据集上进行训练:中等数据集(M)、中等游戏数据集(M-R)和中等专家数据集(M-E)。
表 3 将 minLSTM 和 minGRU 与各种 Decision Transformer 变体进行了比较,包括原始 Decision Transformer (DT)、Decision S4 (DS4)、Decision Mamba 和(Decision)Aaren。minLSTM 和 minGRU 的性能优于 Decision S4,与 Decision Transformer、Aaren 和 Mamba 相比也不遑多让。与其他循环方法不同,Decision S4 是一种循环转换不感知输入的模型,这影响了其性能。从 3 × 3 = 9 个数据集的平均得分来看,minLSTM 和 minGRU 优于所有基线方法,只有 Decision Mamba 的差距很小。

语言建模。研究者使用 nanoGPT 框架对莎士比亚作品进行字符级 GPT 训练。图 2 用交叉熵损失绘制了学习曲线,将所提出的最小 LSTM 和 GRU(minLSTM 和 minGRU)与 Mamba 和 Transformers 进行了比较。结果发现,minGRU、minLSTM、Mamba 和 Transformers 的测试损失相当,分别为 1.548、1.555、1.575 和 1.547。Mamba 的表现略逊于其他模型,但训练速度更快,尤其是在早期阶段,在 400 步时达到最佳表现,而 minGRU 和 minLSTM 则分别持续训练到 575 步和 625 步。相比之下,Transformers 的训练速度明显较慢,需要比 minGRU 多 2000 步(∼ 2.5 倍)的训练步骤才能达到与 minGRU 相当的性能,这使得它的训练速度明显更慢,资源消耗也更大(与 minGRU、minLSTM 和 Mamba 的线性复杂度相比,Transformers 的复杂度为二次方)。

更多研究细节,可参考原论文。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











