




代码知识原来这么重要。
如今说起大语言模型(LLM),写代码能力恐怕是「君子六艺」必不可少的一项。
在预训练数据集中包含代码,即使对于并非专门为代码设计的大模型来说,也已是必不可少的事。虽然从业者们普遍认为代码数据在通用 LLM 的性能中起着至关重要的作用,但分析代码对非代码任务的精确影响的工作却非常有限。
在最近由 Cohere 等机构提交的一项工作中,研究者系统地研究了代码数据对通用大模型性能的影响。

论文链接:https://arxiv.org/abs/2408.10914
设问「预训练中使用的代码数据对代码生成以外的各种下游任务有何影响」。作者对范围广泛的自然语言推理任务、世界知识任务、代码基准和 LLM-as-a-judge 胜率进行了广泛的消融和评估,模型的参数大小从 4.7 亿到 2.8 亿个参数不等。
在各种配置中,我们可以看到存在一致的结果:代码是泛化的关键模块,远远超出了编码任务的范围,并且代码质量的改进对所有任务都有巨大影响。预训练期间投资代码质量和保留代码数据,可以产生积极影响。
这里有几个因素很重要,包括确保代码比例正确、通过包含合成代码和代码相邻数据(例如 commits)来提高代码质量,以及在冷却期间等多个训练阶段利用代码。该研究结果表明,代码是泛化的关键构建块,远远超出了编码任务的范围,代码质量的提高对性能有巨大的影响。
再进一步,作者对广泛的基准进行了广泛的评估,涵盖世界知识任务、自然语言推理和代码生成,以及 LLM 作为评判者的胜率。在对 4.7 亿到 28 亿参数模型进行实验后,以下是详细结果:
1. 代码为非代码任务的性能提供了重大改进。使用代码预训练模型进行初始化可提高自然语言任务的性能。特别是,与纯文本预训练相比,添加代码可使自然语言推理能力相对增加 8.2%,世界知识增加 4.2%,生成胜率提高 6.6%,代码性能提高 12 倍。
2. 代码质量和属性很重要。使用标记样式的编程语言、代码相邻数据集(例如 GitHub commits)和合成生成的代码可提高预训练的性能。特别是,与预训练中的基于 Web 的代码数据相比,在更高质量的合成生成的代码数据集上进行训练可使自然语言推理和代码性能分别提高 9% 和 44%。此外,与不包含代码数据的代码模型初始化相比,包含合成数据的代码模型持续预训练分别使自然语言推理和代码性能相对提高 1.9% 和 41%。
3. 冷却中的代码可进一步改善所有任务。在预训练冷却中包含代码数据,其中高质量数据集被加权,与冷却前的模型相比,自然语言推理性能增加 3.6%,世界知识增加 10.1%,代码性能增加 20%。更重要的是,包含代码的冷却比基线(无冷却的模型)的胜率高出 52.3%,其中胜率比无代码的冷却高出 4.1%。
方法概览
在方法部分,研究者从预训练数据、评估、训练与模型细节三个部分着手进行介绍。下图 1 为高级实验框架。
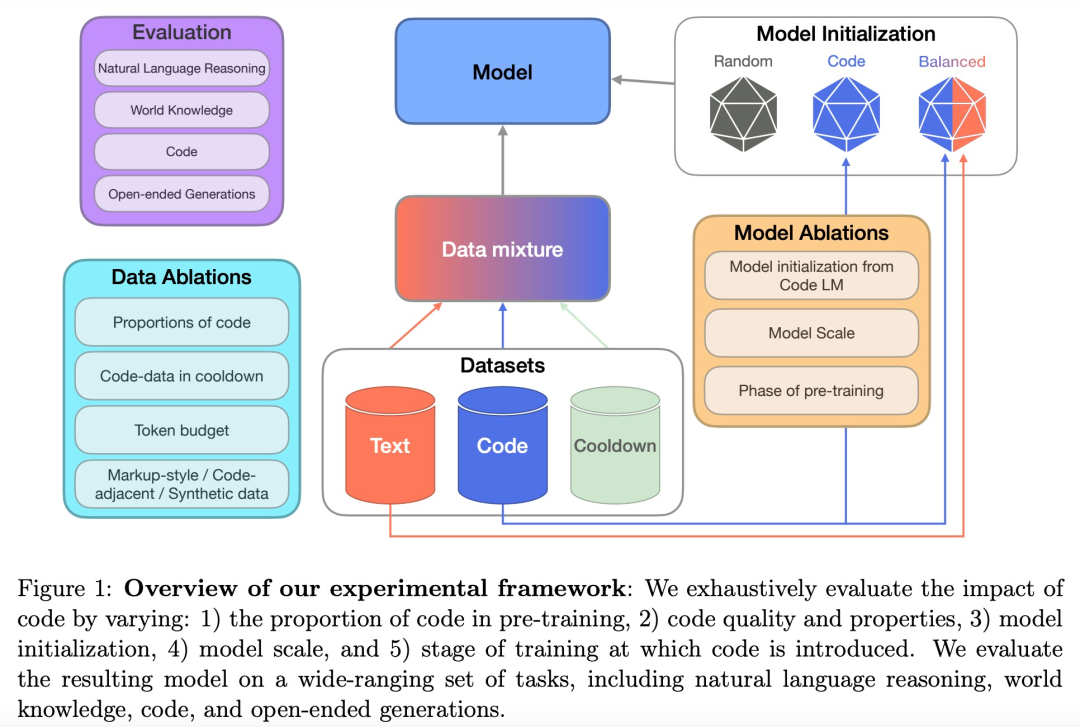
预训练数据
研究者描述了预训练和冷却(cooldown)数据集的细节。目标是在当前 SOTA 实践的标准下,评估代码在预训练中的作用。因此,他们考虑了由以下两个阶段组成的预训练运行,即持续预训练和冷却。
其中持续预训练是指训练一个从预训练模型初始化而来并在固定 token 预算下训练的模型。冷却是指在训练的最后阶段,提高高质量数据集的权重并对相对较少数量的 token 进行学习率的退火。
关于文本数据集,研究者使用 SlimPajama 预训练语料库作为他们的自然语言文本数据源。
关于代码数据集,为了探索不同属性的代码数据的影响,研究者使用了不同类型的代码源,包括如下:
基于 web 的代码数据,这是主要的代码数据源,包括用于训练 StarCoder 的 Stack 数据集。该数据集包含了爬取自 GitHub 的自由授权的代码数据。研究者使用了质量过滤器,并选定了基于文档数(document count)的前 25 种编程语言。在走完所有过滤步骤后,仅代码和 markup 子集的规模为 139B tokens。
Markdown 数据。研究者单独处理了 mark-up 风格的语言,比如 Markdown、CSS 和 HTML。走完所有过滤步骤后,markup 子集的规模为 180B tokens。
合成代码数据。为了对代码数据集进行消融测试,研究者使用了专门的合成生成代码数据集, 包含已经正式验证过的 Python 编程问题。他们将该数据集作为高质量代码数据源,最终的合成数据集规模为 3.2B tokens。
相邻代码数据。为了探索不同属性的代码数据,研究者还使用了包含 GitHub 提交、jupyter notebooks、StackExchange threads 等辅助数据的代码数据。这类数据的规模为 21.4B tokens。
预训练冷却数据集。冷却包含在预训练最后阶段提高更高质量数据集的权重。对此,研究者选择了包含高质量文本、数学、代码和指令型文本数据集的预训练冷却混合。
评估
本文的目标是系统地理解代码对通用任务性能的影响,因此使用了一个广泛的评估组件,涵盖了包含代码生成在内的多样下游任务。
为此,研究者在包含 1)世界知识、2)自然语言推理和 3)代码性能的基准上对模型进行了评估。此外,他们还报告了通过 LLM-as-a-judge 评估的胜率(win-rates)。
下表 1 展示了完整的评估组件以及相应的任务、数据集、指标。

研究者对不同规模的模型(从 470M 到 2.8B 参数)展开了性能评估。由于最小规模的模型能力有限,因此为了保证公平比较,他们只比较了所有模型均能达到随机以上性能的基准。
除了特定于任务的判别式性能,研究者评估了使用 LLM-as-a-judge 胜率的生成式性能。
训练与模型细节
如上文所说,对于预训练模型,研究者使用了 470M 到 2.8B 参数的 decoder-only 自回归 Transformer 模型,它们按照标准语言建模目标来训练。
具体来讲,研究者使用了并行注意力层、SwiGLU 激活、没有偏差的密集层和包含 256000 个词汇的字节对编码(BPE)tokenizer。所有模型使用 AdamW 优化器进行预训练,批大小为 512,余弦学习率调度器的预热步为 1325,最大序列长度为 8192。
在基础设施方面,研究者使用 TPU v5e 芯片进行训练和评估。所有模型在训练中使用了 FAX 框架。为了严格进行消融评估,研究者总共预训练了 64 个模型。每次预训练运行使用 200B tokens,470M 参数模型用了 4736 TPU 芯片时,2.8B 参数模型用了 13824 TPU 芯片时。每次冷却运行使用了 40B tokens,470M 参数模型用了 1024 TPU 芯片时。
实验结果
该研究展开了系统的实验,探究了以下几方面的影响:
使用代码预训练模型初始化 LLM
模型规模
预训练数据中代码的不同比例
代码数据的质量和属性
预训练冷却中的代码数据
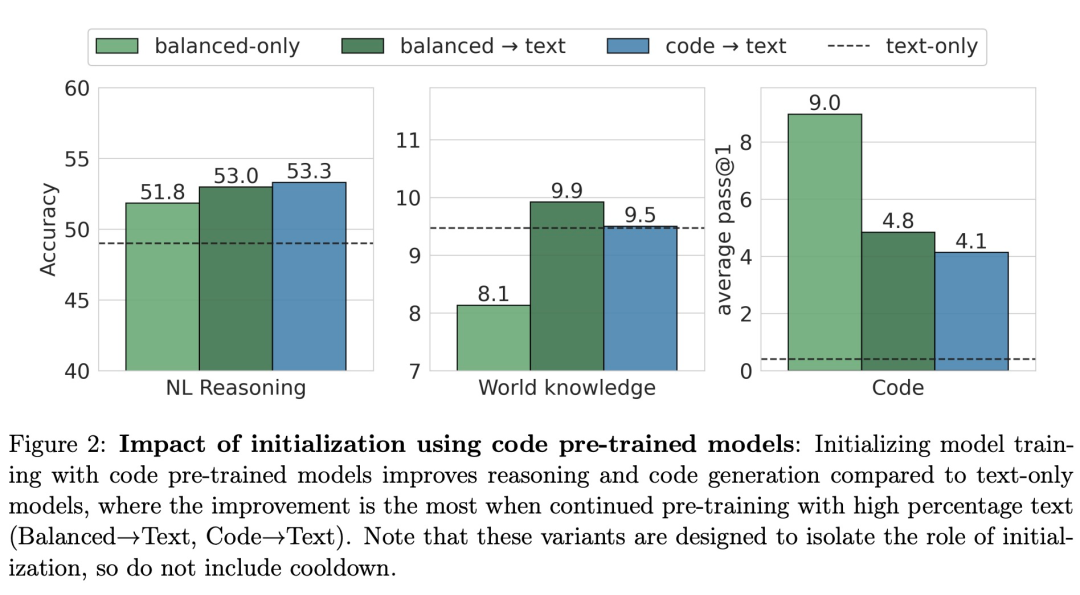
为了探究使用具有大量代码数据的 LM 作为初始化是否可以提高模型性能,该研究针对不同的预训练模型初始化进行了实验。如图 2 所示,使用 100% 代码预训练模型(code→text)进行初始化能让模型在自然语言 (NL) 推理基准上获得最佳性能,紧随其后的是 balanced→text 模型。
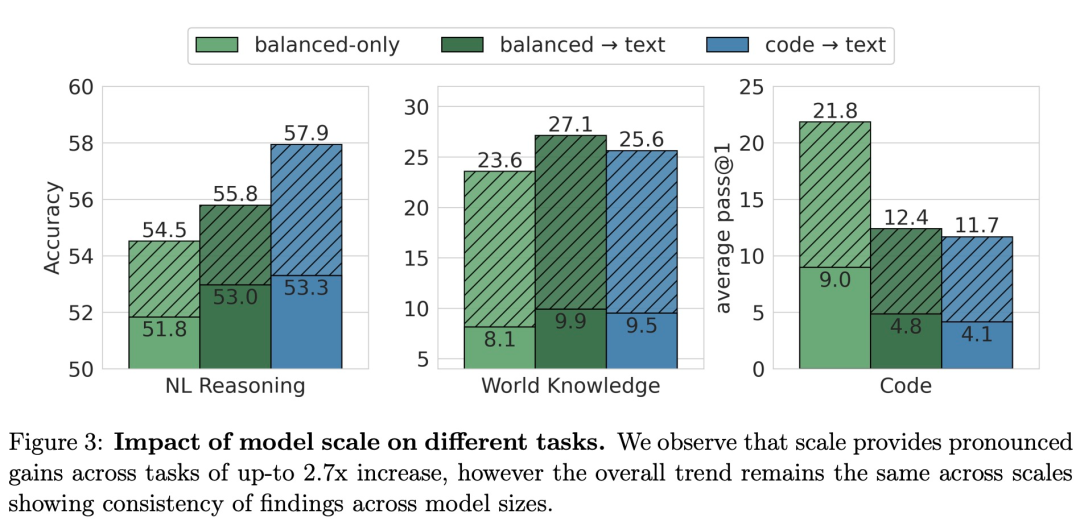
为了了解上述结果是否可以迁移到更大的模型,该研究以 470M 模型相同的 token 预算,训练了 2.8B 参数模型。下图显示了 2.8B 模型与 470M 模型的比较结果。
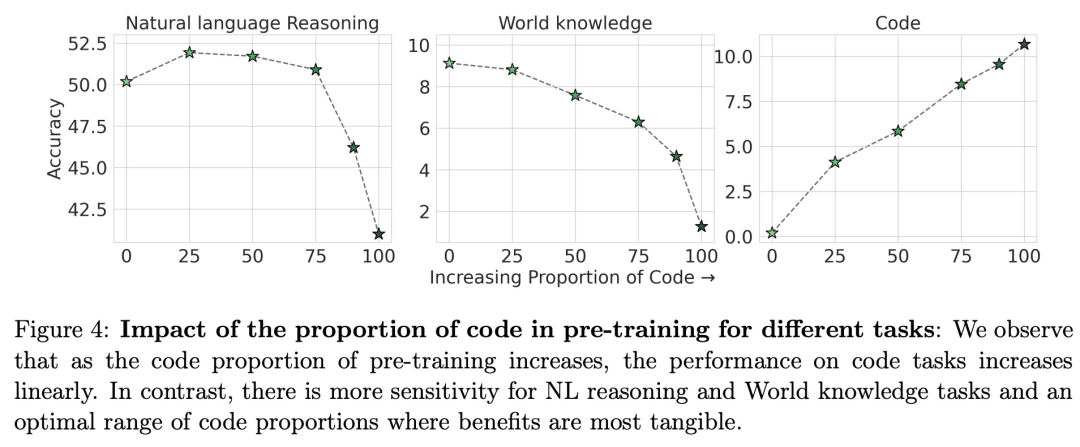
该研究探究了预训练中代码数据比例对不同任务模型性能的影响,观察到随着预训练代码数据比例的增加,代码任务的性能呈线性提高,而对于 NL 推理任务和世界知识任务则存在效益最明显的最佳代码数据比例范围。
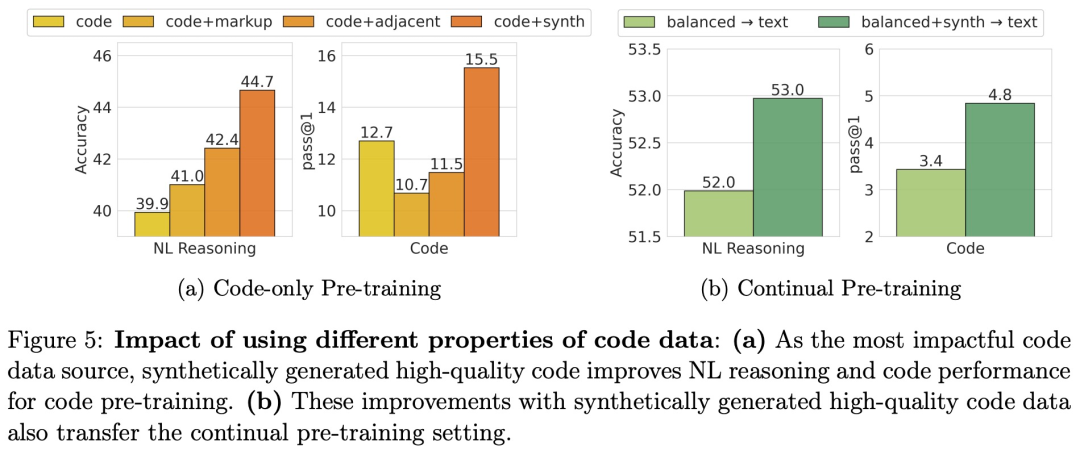
如图 5 (a) 所示,在评估代码质量和代码构成的影响方面,该研究观察到,包含不同的代码源和合成代码,都会导致自然语言性能的提高,但是,只有合成生成的代码才能提高代码性能。
如图 5 (b) 所示,在 NL 推理任务和代码任务中,balanced+synth→text 比 balanced→text 分别实现了 2% 和 35% 的相对改进。这进一步证实,即使是一小部分的高质量代码数据,也可以提高代码和非代码任务的性能。
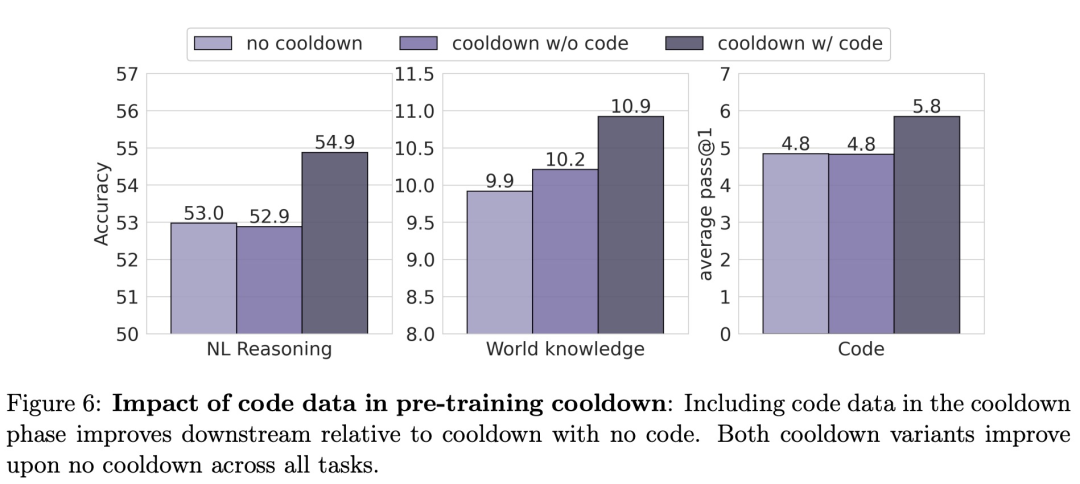
如图 6 所示,该研究发现:在预训练冷却中包含代码数据,模型的NL推理性能增加 3.6%,世界知识性能增加 10.1%,代码性能增加 20%。
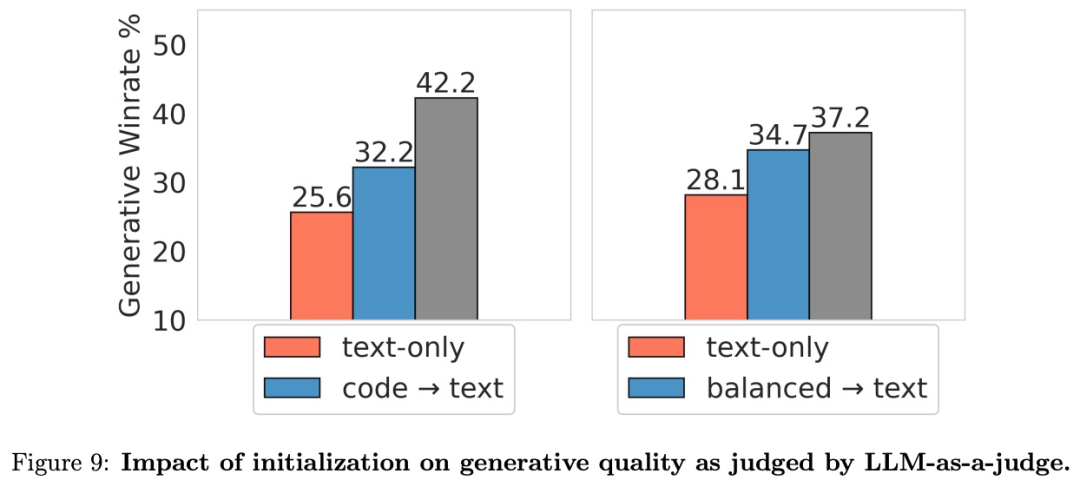
 如图 7 所示,正如预期的那样,冷却对以胜率衡量的生成性能有重大影响。
如图 7 所示,正如预期的那样,冷却对以胜率衡量的生成性能有重大影响。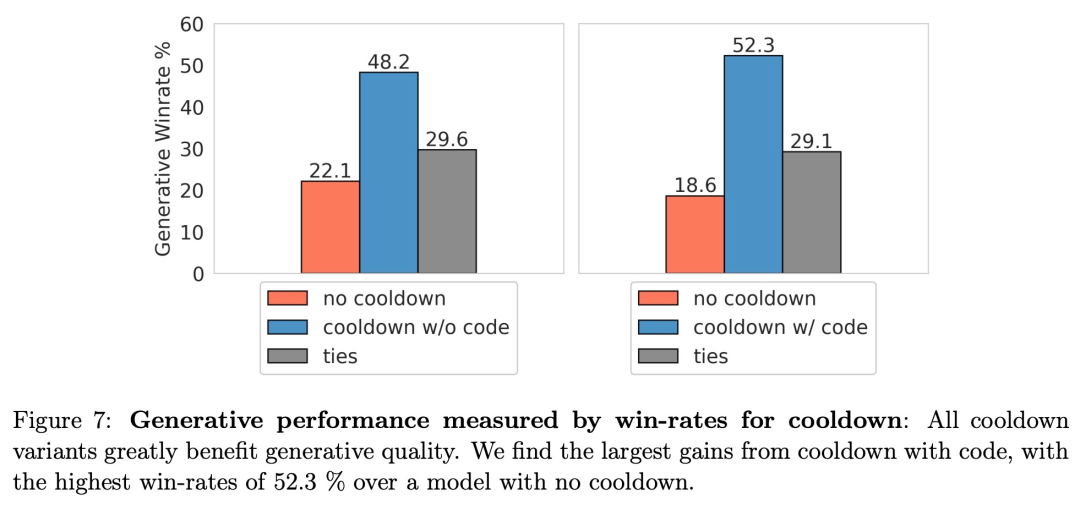
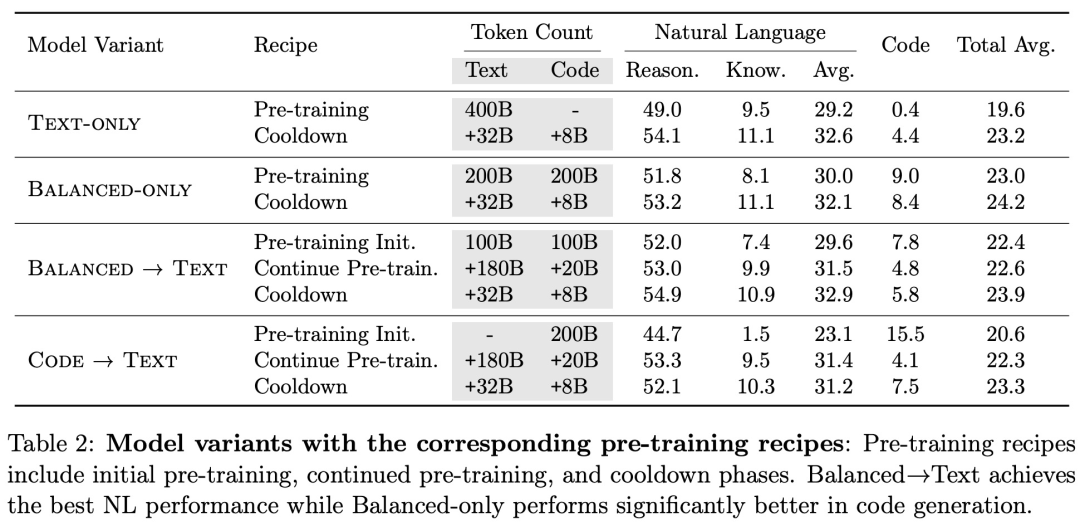
采用不同预训练方案的模型的性能比较结果如表 2 所示,Balanced→Text 实现了最佳的 NL 性能,而 Balanced-only 在代码生成方面明显表现更好。




“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











