




近日,来自香港中文大学 - 商汤科技联合实验室等机构的研究者们提出了FouriScale,该方法在利用预训练扩散模型生成高分辨率图像方面取得了显著提升。
近期,扩散模型凭借其出色的性能已超越 GAN 和自回归模型,成为生成式模型的主流选择。基于扩散模型的文本到图像生成模型(如 SD、SDXL、Midjourney 和 Imagen)展现了生成高质量图像的惊人能力。通常,这些模型在特定分辨率下进行训练,以确保在现有硬件上实现高效处理和稳定的模型训练。
 图 1 : 采用不同方法在 SDXL 1.0 下生成 2048×2048 图像的对比
图 1 : 采用不同方法在 SDXL 1.0 下生成 2048×2048 图像的对比。[1]
然而,当这些预训练的扩散模型在超出训练分辨率时生成图像,通常会出现模式重复和严重的人工伪影(artifacts)问题,如图 1 最左侧所示。
为了解决这一问题,来自香港中文大学 - 商汤科技联合实验室等机构的研究者们在一篇论文中深入研究了扩散模型中常用的 UNet 结构的卷积层,并从频域分析的角度提出了 FouriScale, 如图 2 所示。
 图 2 FouriScale 的流程(橙色线)示意图,目的是保证跨分辨率的一致性。
图 2 FouriScale 的流程(橙色线)示意图,目的是保证跨分辨率的一致性。FouriScale 通过引入空洞卷积操作和低通滤波操作来替换预训练扩散模型中的原始卷积层,旨在实现不同分辨率下的结构和尺度一致性。配合「填充然后裁剪」策略,该方法能够灵活生成不同尺寸和长宽比的图像。此外,借助 FouriScale 作为指导,该方法在生成任意尺寸的高分辨率图像时,能够保证完整的图像结构和卓越的图像质量。FouriScale 无需任何离线预计算,具有良好的兼容性和可扩展性。
定量和定性实验结果表明,FouriScale 在利用预训练扩散模型生成高分辨率图像方面取得了显著提升。

论文地址:https://arxiv.org/abs/2403.12963
开源代码:https://github.com/LeonHLJ/FouriScale
论文标题:FouriScale: A Frequency Perspective on Training-Free High-Resolution Image Synthesis
方法介绍
1、空洞卷积保证跨分辨率下的结构一致性
扩散模型的去噪网络通常是在特定分辨率的图像或潜在空间上训练的,这个网络通常采用 U-Net 结构。作者的目标是在推理阶段使用去噪网络的参数生成分辨率更高的图像,而无需重新训练。为了避免推理分辨率下的结构失真,作者尝试在默认分辨率和高分辨率之间建立结构一致性。对于 U-Net 中的卷积层,结构一致性可表述为:

其中 k 是原本的卷积核,k' 是为更大分辨率定制的新卷积核。根据空间下采样的频域表示,如下:

可以将公式(3)写为:

这个公式表明了理想卷积核 k' 的傅里叶频谱应该是由 s×s 个卷积核 k 的傅里叶频谱拼接而成的。换句话说,k' 的傅里叶频谱应该有周期性重复,这个重复模式是 k 的傅里叶频谱。
广泛使用的空洞卷积正好满足这个要求。空洞卷积的频域周期性可以通过下式表示:

当利用预训练扩散模型(训练分辨率为(h,w))生成 (H,W) 的高分辨率图像时,空洞卷积的参数使用原始卷积核,扩张因子为 (H/h, W/w),是理想的卷积核 k'。
2、低通滤波保证跨分辨率下的尺度一致性
然而,只利用空洞卷积无法完美地解决问题,如图 3 左上角所示,只使用空洞卷积仍然在细节上存在模式重复的现象。作者认为这是因为空间下采样的频率混叠现象改变了频域分量,导致了不同分辨率下频域分布的差异。为了保证跨分辨率下的尺度一致性,他们引入了低通滤波来过滤掉高频分量,以去除空间下采样后的频率混叠问题。从图 3 右侧对比曲线可以看到,在使用低通滤波后,高低分辨率下的频率分布更加接近,从而保证了尺度一致。从图 3 左下角图看到,在使用低通滤波后,细节的模式重复现象有明显地改善。

图 3 (a) 是否采用低通滤波的视觉对比。(b)不采用低通滤波的傅立叶相对对数幅值曲线。(c) 采用低通滤波的傅立叶相对对数幅值曲线。
3、适应于任意尺寸的图像生成
以上的方式只能适应于生成分辨率与默认推理分辨率的长宽比一致时,为了使 FouriScale 适应于任意尺寸的图像生成,作者采用了一种「填充然后裁剪」的方式,方法 1 中展示了结合了该策略的 FouriScale 的伪代码.
4、FouriScale 引导
由于 FouriScale 中的频域操作,不可避免的使生成的图像出现了细节缺失与不期望的伪影问题。为了解决这一问题,如图 4,作者提出了将 FouriScale 作为引导的方式。具体来说,在原本的条件生成估计以及无条件生成估计的基础上,他们引入一个额外的条件生成估计。这个额外的条件生成估计的生成过程同样采用空洞卷积,但是使用更加温和的低通滤波,从而保证细节不丢失。同时他们将利用 FouriScale 输出的条件生成估计中的注意力分数替换掉这一额外的条件生成估计中的注意力分数,由于注意力分数包含着生成图像中的结构信息,这一操作将 FouriScale 中正确的图像结构信息引入,同时保证了图像质量。

图 4 (a) FouriScale 引导示意图。(b)不采用 FouriScale 作为引导的生成图像,有明显的伪影和细节错误。(c) 采用 FouriScale 作为引导的生成图像。
实验
1. 定量试验结果
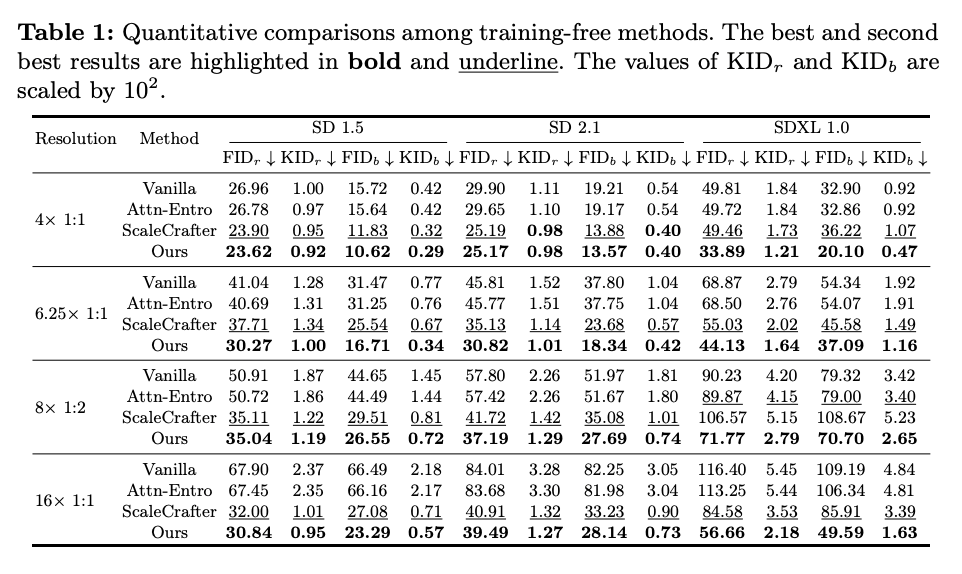
作者遵循 [1] 的方法,测试了三个文生图模型(包括 SD 1.5,SD 2.1 和 SDXL 1.0),生成四种更高分辨率的图像。测试的分辨率是它们各自训练分辨率的 4 倍、6.25 倍、8 倍和 16 倍像素数量。在 Laion-5B 上随机采样 30000/10000 个图文对测试的结果如表 1 所示:

他们的方法在各个预训练模型,不同分辨率下都获得了最优的结果。
2. 定性试验结果
如图 5 所示,他们的方法在各个预训练模型,不同分辨率下都能够保证图像生成质量与一致的结构。

结论
本文提出了 FouriScale 用于增强预训练扩散模型生成高分辨率图像的能力。FouriScale 从频域分析出来,通过空洞卷积和低通滤波操作改善了不同分辨率下的结构和尺度一致性,解决了重复模式和结构失真等关键挑战。采用「填充然后裁剪」策略并利用 FouriScale 作为指导,增强了文本到图像生成的灵活性和生成质量,同时适应了不同的长宽比生成。定量和定性的实验对比表明,FouriScale 能够在不同预训练模型,不同分辨率下都能够保证更高的图像生成质量。
[1] He Y, Yang S, Chen H, et al. Scalecrafter: Tuning-free higher-resolution visual generation with diffusion models[C]//The Twelfth International Conference on Learning Representations. 2023.



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











