




随着大模型技术的发展与落地,「模型治理」已经成为了目前受到重点关注的命题。只不过,在实践中,研究者往往感受到多重挑战。
一方面,为了高其在目标任务的性能表现,研究者会收集和构建目标任务数据集并对大语言模型(LLM)进行微调,但这种方式通常会导致除目标任务以外的一般任务的性能明显下降,损害 LLM 原本具备的通用能力。
另一方面,开源社区的模型逐渐增多,大模型开发者也可能在多次训练中累计了越来越多的模型,每个模型都具有各自的优势,如何选择合适的模型执行任务或进一步微调反而成为一个问题。
近日,智源研究院信息检索与知识计算组发布 LM-Cocktail 模型治理策略,旨在为大模型开发者提供一个低成本持续提升模型性能的方式:通过少量样例计算融合权重,借助模型融合技术融合微调模型和原模型的优势,实现「模型资源」的高效利用。

技术报告:https://arxiv.org/abs/2311.13534
代码:https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail
模型融合技术可以通过融合多个模型提高单模型的性能。受此启发,LM-Cocktail 策略进一步通过对目标任务计算不同模型的重要性,赋予不同模型不同的权重,在此基础上进行模型融合,在提升目标任务上性能的同时,保持在通用任务上的强大能力。
LM-Cocktail 策略可以帮助汇总各模型的优势能力,就像制作鸡尾酒那样,通过加入不同的模型进行调制,得到一个具备多种特长的「多才」模型。
方法创新
具体而言,LM-Cocktail 可以通过手动选择模型配比,或者输入少量样例自动计算加权权重,来融合现有模型生成一个新模型,该过程不需要对模型进行重新训练并且具备适配多种结构的模型,如大语言模型 Llama,语义向量模型 BGE 等。
此外,如果开发者缺乏某些目标任务的标签数据,或者缺少计算资源进行模型微调,那么采用 LM-Cocktail 策略可以省去模型微调步骤,通过构造非常少量的数据样例,融合开源社区中已有的大语言模型来调制自己的「LM 鸡尾酒」。
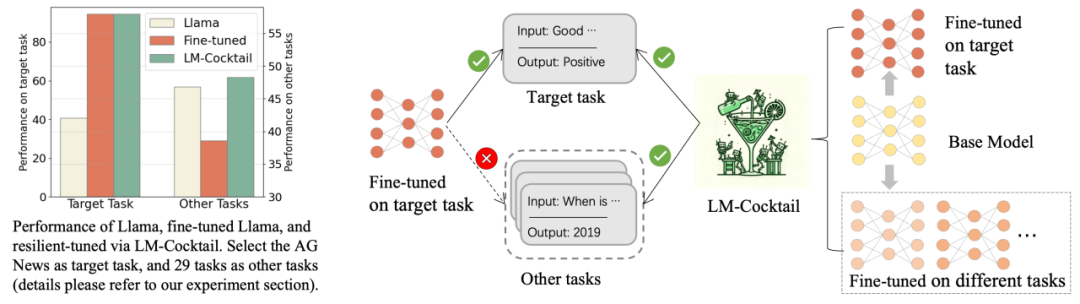
如上图所示,在特定目标任务上微调 Llama,可以显著提高目标任务上的准确度,但损害了在其他任务上的通用能力。采用 LM-Cocktail 可以解决这个问题。
LM-Cocktail 的核心是将微调后的模型与多个其他模型的参数进行融合,整合多个模型的优点,在提高目标任务上准确度的同时,保持在其他任务上的通用能力。具体形式为,给定目标任务、基础模型,以及一个在该任务上微调基础模型后得到的模型,同时收集开源社区或以往训练过的模型组成集合。通过目标任务上少量的样例计算每个模型的融合加权权重,对这些模型的参数进行加权求和,得到新的模型(具体的过程请参考论文或开源代码)。如果开源社区不存在其他模型,也可以直接融合基础模型和微调模型,在不降低通用能力的基础上提升下游任务表现。
用户在实际应用场景中,由于数据和资源的限制,可能无法进行下游任务的微调,即没有在目标任务微调过后的模型。这种情况下,用户可以通过构造非常少量的数据样例融合社区中已有的大语言模型,生成一个面向新任务的模型,提高目标任务的准确度,而无需对模型进行训练。
实验结果
1. 弹性微调保持通用能力
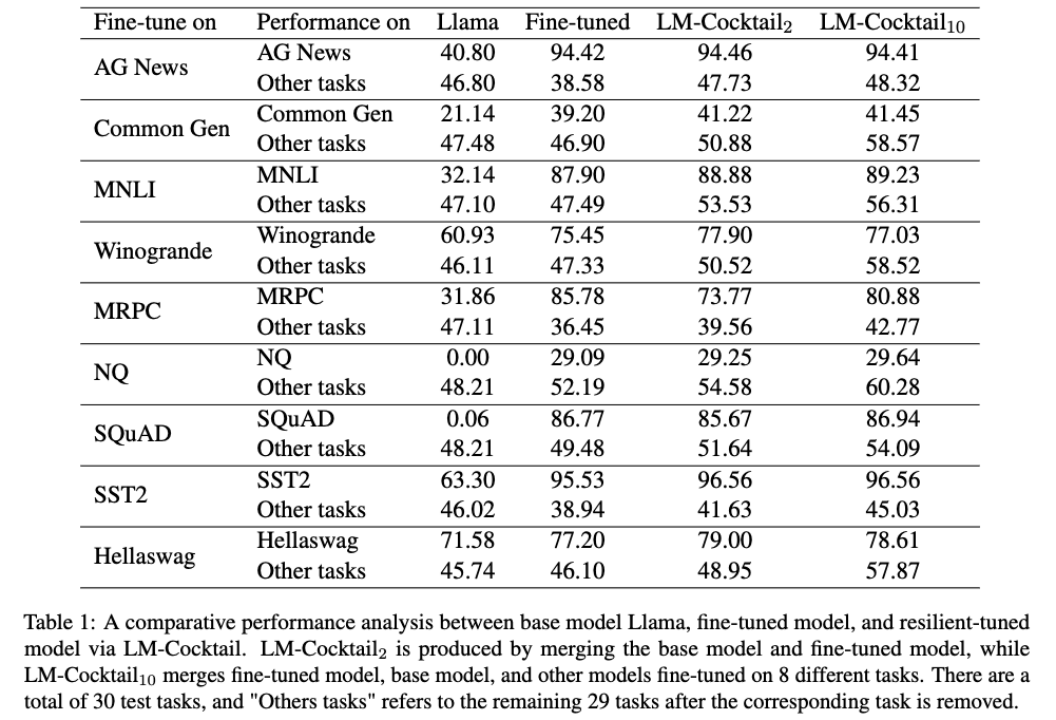
从上图中可以看到,在某个目标任务上进行微调之后,微调后的模型大幅提高了在该任务上的准确度,但其他通用任务上的准确度都有所下降。例如,在 AG News 到训练集上进行微调,Llama 在 AG News 测试集上准确度从 40.80% 涨到 94.42%,但在其他任务上准确度从 46.80% 下降到了 38.58%。
然而,通过简单的融合微调后模型和原模型的参数,在目标任务上实现了具有竞争力的性能 94.46%,与微调模型相当,同时在其他任务上准确度为 47.73%, 甚至稍强于原模型的性能。在某些任务下,如 Helleswag, 融合后的模型甚至可以在该微调任务上超过微调后的模型,并在其他任务上超过原通用模型,即在继承微调模型和原模型的优点的同时,超过了他们。可以看出,通过 LM-Cocktail 计算融合比例,进一步融合其他微调模型,可以在保证目标任务准确度的同时,进一步提升在其他任务上的通用性能。
2. 混合已有模型处理新任务
 图:语言模型目标任务 MMLU
图:语言模型目标任务 MMLU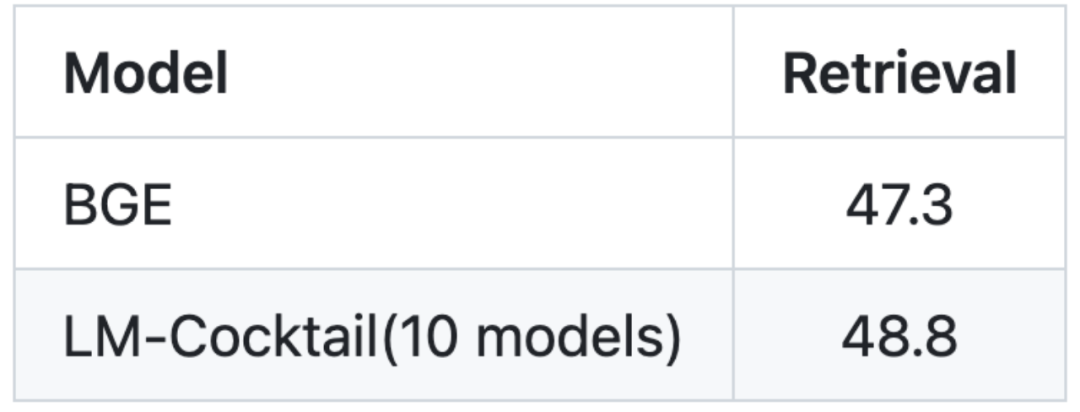 图:向量模型目标任务 Rerival(信息检索)
图:向量模型目标任务 Rerival(信息检索)微调模型需要大量的数据,同时需要大量的计算资源,尤其是微调大语言模型,这些在实际情况中不一定可以实现。在无法对目标任务进行微调的情况下,LM- Cocktail 可以通过混合已有的模型(来自开源社区或者自己历史训练积累)来实现新的能力。
通过只给定 5 条样例数据,LM-Cocktail 自动计算融合加权权重,从已有的模型进行筛选然后融合得到新的模型,而无需使用大量数据进行训练。实验发现,生成的新模型可以在新的任务上得到更高的准确度。例如,对于 Llama,通过 LM- Cocktail 融合现有 10 个模型(其训练任务都与 MMLU 榜单无关),可以取得明显的提升,并且要高于使用 5 条样例数据进行上下文学习的 Llama 模型。
欢迎大家体验 LM-Cocktail,并通过 GitHub issue 反馈建议:https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











