




当地时间4月12日,微软宣布开源DeepSpeed-Chat,帮助用户轻松训练类ChatGPT等大语言模型,人人都有望拥有专属ChatGPT。
开源地址:https://github.com/microsoft/DeepSpeed
OpenAI之前明确表示拒绝开源GPT-4,也收获了无数“OpenAI并不open”的吐槽。而AI开源社区已推出LLaMa、Vicuna、Alpaca等多个模型,帮助开发者开发类ChatGPT模型。
即便如此,现有解决方案下训练数千亿参数的最先进类ChatGPT模型依旧困难,主要瓶颈便在于缺乏RLHF训练普及——而微软本次开源的DeepSpeed-Chat,便补齐了最后这一块“短板”,帮助在模型训练中加入完整RLHF流程的系统框架。
仅需一个脚本,便可以完成RLHF训练的全部三个阶段,类ChatGPT大语言模型生成唾手可得,堪称“傻瓜式操作”。
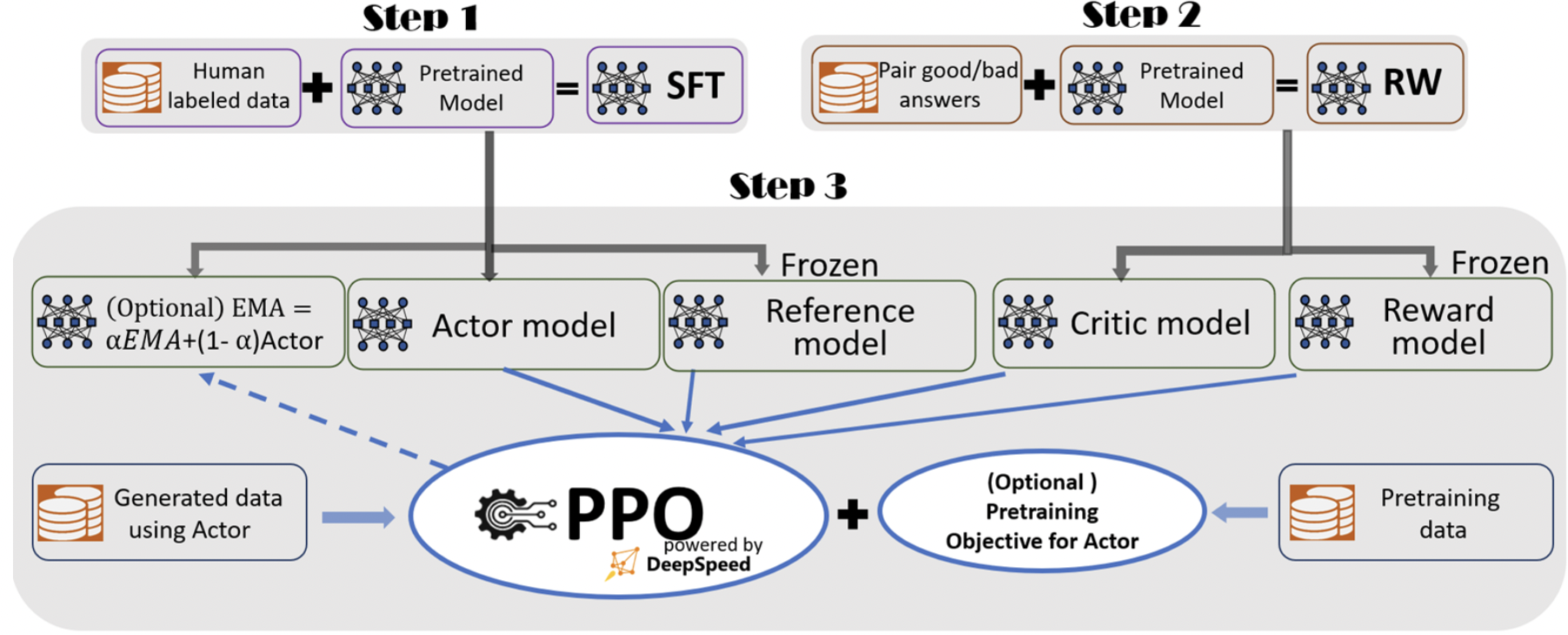 图|DeepSpeed-Chat的RLHF 训练流程图示,包含了一些可选择功能(来源:微软)
图|DeepSpeed-Chat的RLHF 训练流程图示,包含了一些可选择功能(来源:微软)这还不是DeepSpeed-Chat唯一的优势,微软提供了中、英、日三语文档,作出了详细介绍。总体来说,其核心功能与性能包括:
1. 简化类ChatGPT模型训练、强化推理体验。
2. DeepSpeed-RLHF模块复刻了InstructGPT论文中的训练模式。同时,DeepSpeed将训练引擎与推理引擎共同整合到了一个统一混合引擎用于RLHF训练。
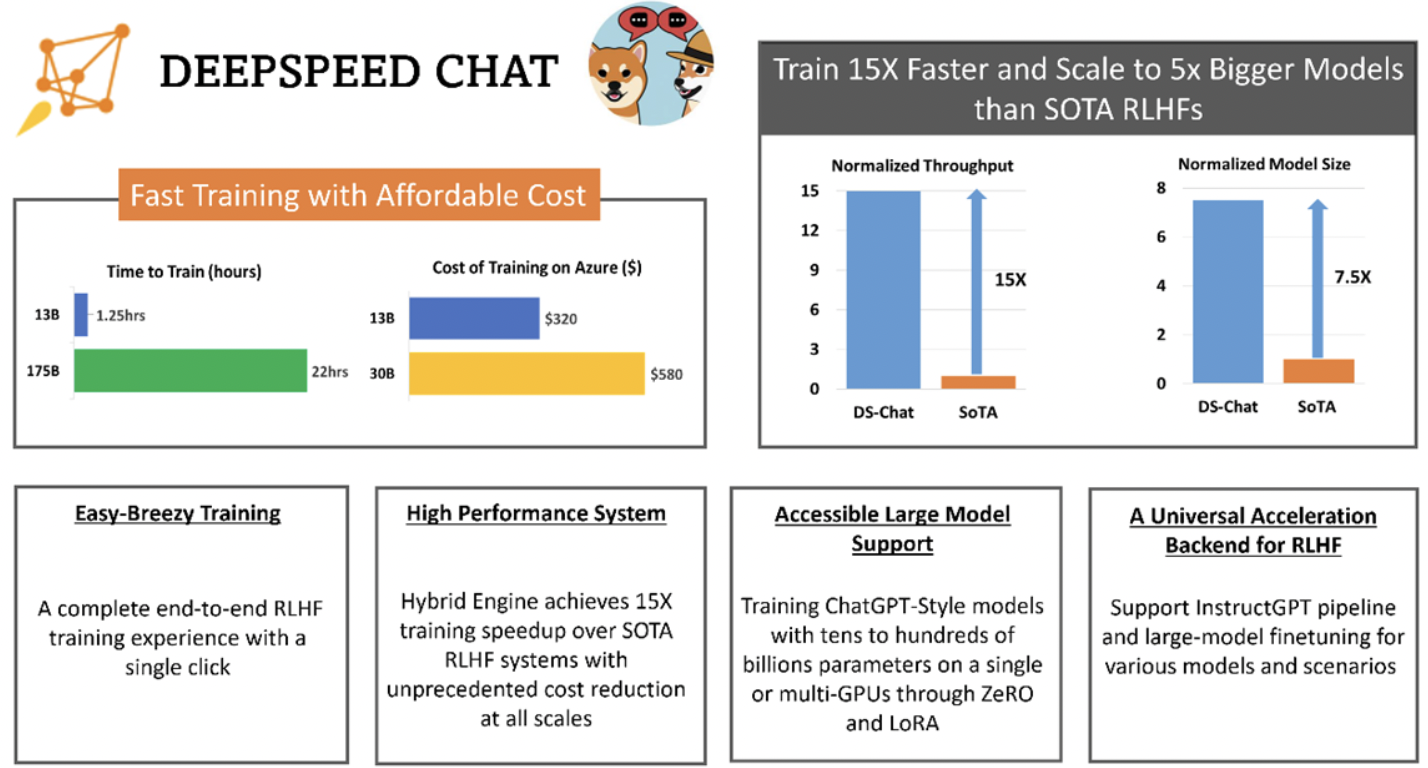
3. 高效性和经济性:可将训练速度提升15倍以上,并大幅度降低成本。例如,DeepSpeed-HE若在Azure云上训练一个OPT-30B模型,仅需18小时、花费不到300美元。
4. 卓越的扩展性:可支持训练数千亿参数模型,并在多节点多GPU系统上扩展性突出,只需1.25小时就可完成训练一个130亿参数模型。
5. 实现RLHF训练普及化:仅凭单个GPU,DeepSpeed-HE就能支持训练超过130亿参数的模型。因此无法使用多GPU系统的数据科学家和研究者,不仅能创建轻量级RLHF模型,还能创建大型且功能强大的模型。
此外,与Colossal-AI、HuggingFace等其他RLHF系统相比,DeepSpeed-RLHF在系统性能和模型可扩展性方面表现出色:
就吞吐量而言,DeepSpeed在单个GPU上的RLHF训练中实现10倍以上改进;多GPU设置中,则比Colossal-AI快6-19倍,比HuggingFace DDP快1.4-10.5倍。
就模型可扩展性而言,Colossal-AI可在单个GPU上运行最大1.3B的模型,在单个A100 40G 节点上运行6.7B的模型,而在相同的硬件上,DeepSpeed-HE可分别运行6.5B和50B模型,实现高达7.5倍提升。
因此,凭借超过一个数量级的更高吞吐量,DeepSpeed-RLHF比Colossal-AI、HuggingFace,可在相同时间预算下训练更大的actor模型,或以1/10的成本训练类似大小的模型



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











