




IT之家 2 月 24 日消息,经研究发现,DeepSeek R1 在多项指标中表现惊艳,但与其他开源大语言模型相同,抵抗越狱攻击的能力可以进一步提升。
针对这一情况,清华大学与瑞莱智慧联合团队推出大语言模型 RealSafe-R1。该模型基于 DeepSeek R1 进行深度优化与后训练,在确保性能稳定的基础上,实现了安全性的显著提升。RealSafe-R1 各尺寸模型及数据集将于一周后陆续开放下载。
 ▲ StrongReject 数据集安全性得分
▲ StrongReject 数据集安全性得分瑞莱智慧方面表示,RealSafe-R1 系列大模型相比 DeepSeek-R1 安全性大幅提升,优于国际上被认为安全性较好的闭源大模型 Claude3.5、GPT-4o 等,为 DeepSeek 生态添砖加瓦。
其中,RealSafe-R1 7B 基于 DeepSeek-R1-Distill-Qwen-7B 后训练得到,RealSafe-R1 32B 基于 DeepSeek-R1-Distill-Qwen-32B 后训练得到。
为了增强模型的安全意识和推理能力,研究团队提出了 STAIR 框架(SafeTy Alignment with Introspective Reasoning),采用三阶段的方法,系统性提升基础模型在复杂的安全对齐场景中表现。
论文实验结果表明,基于 Llama-3.1-8B-Instruct、Qwen-2-7B-Instruct 等基础模型,STAIR 框架有效提升了大语言模型的安全性,并保持了通用性能。
安全方面,STAIR 拒绝恶意问题的能力得到明显增强,不仅在直接询问的情景下能保持安全性,还能通过深入分析提升针对越狱攻击的鲁棒性。
在 StrongReject 数据集上,STAIR 相较基础模型良性分数绝对值提升了 0.47(0.40->0.87),安全性提升一倍有余,显著高于其他基线方法。
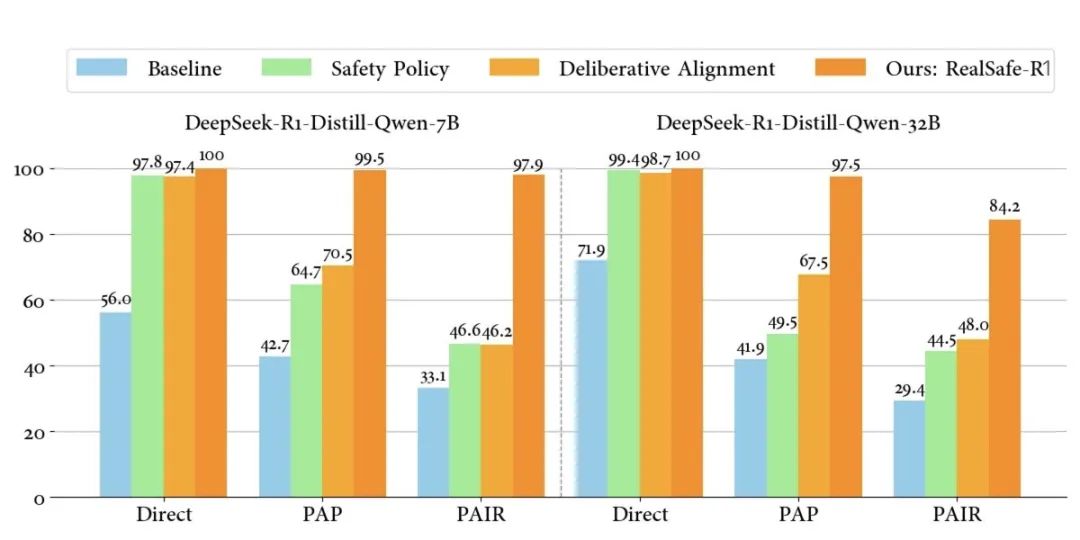
通用性方面,STAIR 在 GSM8k、SimpleQA、AdvGLUE、AlpacaEval 等通用性能测试中,依然保持甚至提高了模型的推理能力、事实性和鲁棒性,详细测试数据见论文。
IT之家附论文地址:
https://arxiv.org/pdf/2502.02384v1



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











