




一年一度 NLP (自然语言处理)顶会 ACL (国际计算语言学协会)揭晓了最终获奖论文。今年,共有 7 篇论文荣获最佳论文,时间检验奖颁给斯坦福 GloVe、康奈尔大学相似性度量。另外,还有最佳主题奖、最佳社会影响力奖、最佳资源奖、领域主席奖,以及杰出论文奖。
ACL 2024 终于颁奖了!
共有 7 篇最佳论文,35 篇杰出论文,还有时间检验奖、SAC 奖、最佳主题论文、最佳资源论文奖等一并公布。
值得一提的是,7 篇最佳论文中,Deciphering Oracle Bone Language with Diffusion Models 由全华人团队完成。


今年是国际计算语言学年会(ACL)第 26 届会议,于 8 月 11-16 日在泰国曼谷开幕。

ACL 2024 的论文总提交量与 2023 年相差无几,大致为 5000 篇,其中 940 篇论文被接收。
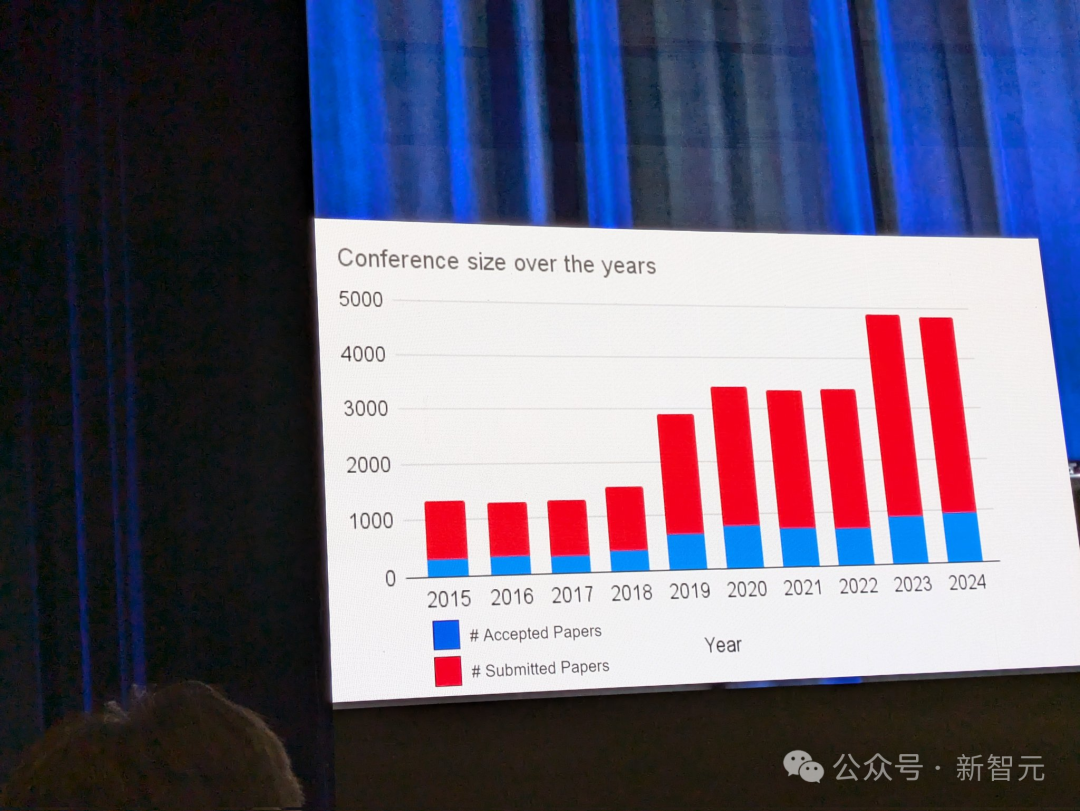
本届 ACL 堪称有史以来,最大的一次,共有 72 名 SAC、716 名 AC、4208 位审稿人。
975 篇 findings 论文,6 篇 JCL、31 篇 TACL,还有 3 个主题演讲,1 个 panel。
整场会议还包含了 18 个 workshop、6 个 tutorial、38 个 demo,60 篇 SRW 论文。

论文作者具体提交论文情况如下:
大多数人提交了 1 篇 / 2 篇论文:有 10333 名学者提交了 1 篇,2130 人提交了 2 篇
少部分人提交了多篇论文:有 3 位作者提交了 18 篇,6 人提交了 19 篇,18 人提交了超 20 篇。

一起看看,今年都有哪些团队荣获大奖?
7 篇最佳论文
论文 1:Deciphering Oracle Bone Language with Diffusion Models
作者:Haisu Guan, Huanxin Yang, Xinyu Wang, Shengwei Han, Yongge Liu, Lianwen Jin, Xiang Bai, Yuliang Liu
机构:华中科技大学、阿德莱德大学、安阳师范学院、华南理工大学

论文地址:https://arxiv.org/pdf/2406.00684
如题所示,华人团队用 AI 做了一件非常有趣且有价值的事 —— 借助扩散模型破译甲骨文(OBS)。
甲骨文起源于大约 3000 年前的中国商朝,是语言史上的一块基石。
尽管人们已经发现了数以千计的碑文,但甲骨文的大量内容仍未被破译,为这一古老的语言蒙上了一层神秘的面纱。
论文中,作者介绍了一种采用图像生成 AI 的新方法,特别是研发出「Oracle Bone Script Decipher」(OBSD)。
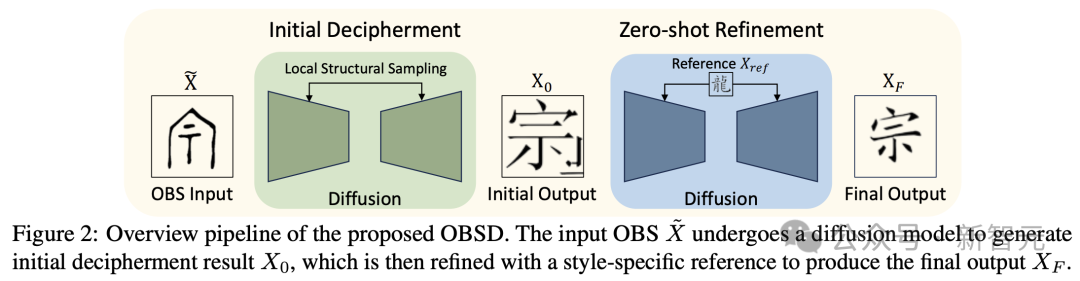
利用基于条件扩散的策略,OBSD 生成了重要的破译线索,为 AI 辅助分析古代语言开辟了一条新路。
为了验证其有效性,研究人员在甲骨文数据集上进行了大量实验,量化结果证明了 OBSD 的有效性。
论文 2:Natural Language Satisfiability: Exploring the Problem Distribution and Evaluating Transformer-based Language Models
(暂未提交预印本)
论文 3:Causal Estimation of Memorisation Profiles
作者:Pietro Lesci, Clara Meister, Thomas Hofmann, Andreas Vlachos, Tiago Pimentel
机构:剑桥大学、苏黎世联邦理工学院

论文地址:https://arxiv.org/pdf/2406.04327
理解 LLM 的记忆,对实践和社会有着重要的影响,比如研究模型训练动态或防止版权侵权。
先前的研究,将记忆定义为通过实例训练,对模型预测该实例的能力,产生的因果响应。
这个定义依赖于一个反事实:能够观察到模型没有看到该实例时会发生什么。
然而,现有的方法通常针对模型架构,而非特定模型实例估算记忆,很难提供计算效率高,且准确的反事实估计。
这项研究填补了一个重要空白,作者基于计量经济学中的差分设计,提出了一种原则性且高效的新方法来估计记忆化。
利用这种方法,只需在整个训练过程中,观察一小部分实例的行为,就能描述出模型的记忆概况,即模型在整个训练过程中的记忆趋势。
在 Pythia 模型套件的实验中,研究人员发现:
(1)大型模型的记忆性更强、更持久;
(2)由数据顺序和学习率决定;
(3)在不同规模的模型中具有稳定的趋势,因此大型模型的记忆与小型模型的记忆具有可预测性。

论文 4:Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model
作者:Ahmet Üstün, Viraat Aryabumi, Zheng-Xin Yong, Wei-Yin Ko, Daniel D'souza, Gbemileke Onilude, Neel Bhandari, Shivalika Singh, Hui-Lee Ooi, Amr Kayid, Freddie Vargus, Phil Blunsom, Shayne Longpre, Niklas Muennighoff, Marzieh Fadaee, Julia Kreutzer, Sara Hooker
机构:Cohere For AI、布朗大学、Cohere、Cohere For AI Community、卡内基梅隆大学、麻省理工学院

论文地址:https://arxiv.org/pdf/2402.07827
今年 2 月,初创公司 Cohere 发布了一款名为 Aya 全新开源的大规模语言生成式大模型,覆盖了超 101 种语言。
值得一提的是,Aya 模型语言模型覆盖范围,是现有开源模型两倍多,超越了 mT0 和 BLOOMZ。
人类评估得分达到 75%,在各项模拟胜率测试中得分为 80-90%。
这一项目得以启动,汇集了来自 119 个国家的超 3000 名独立研究人员的力量。
此外,研究人员还公开了迄今为止最大的多语言指导微调数据集,包含 513 百万条数据,涵盖 114 种语言。
论文 5:Mission: Impossible Language Models
作者:Julie Kallini, Isabel Papadimitriou, Richard Futrell, Kyle Mahowald, Christopher Potts
机构:斯坦福大学、加州大学尔湾分校、得克萨斯大学奥斯汀分校

论文地址:https://arxiv.org/pdf/2401.06416
乔姆斯基等人曾直言道,LLM 在学习人类可能和不可能学习的语言方面具有同等能力。
然而,很少有公开发表的实验证据,支撑这种说法。
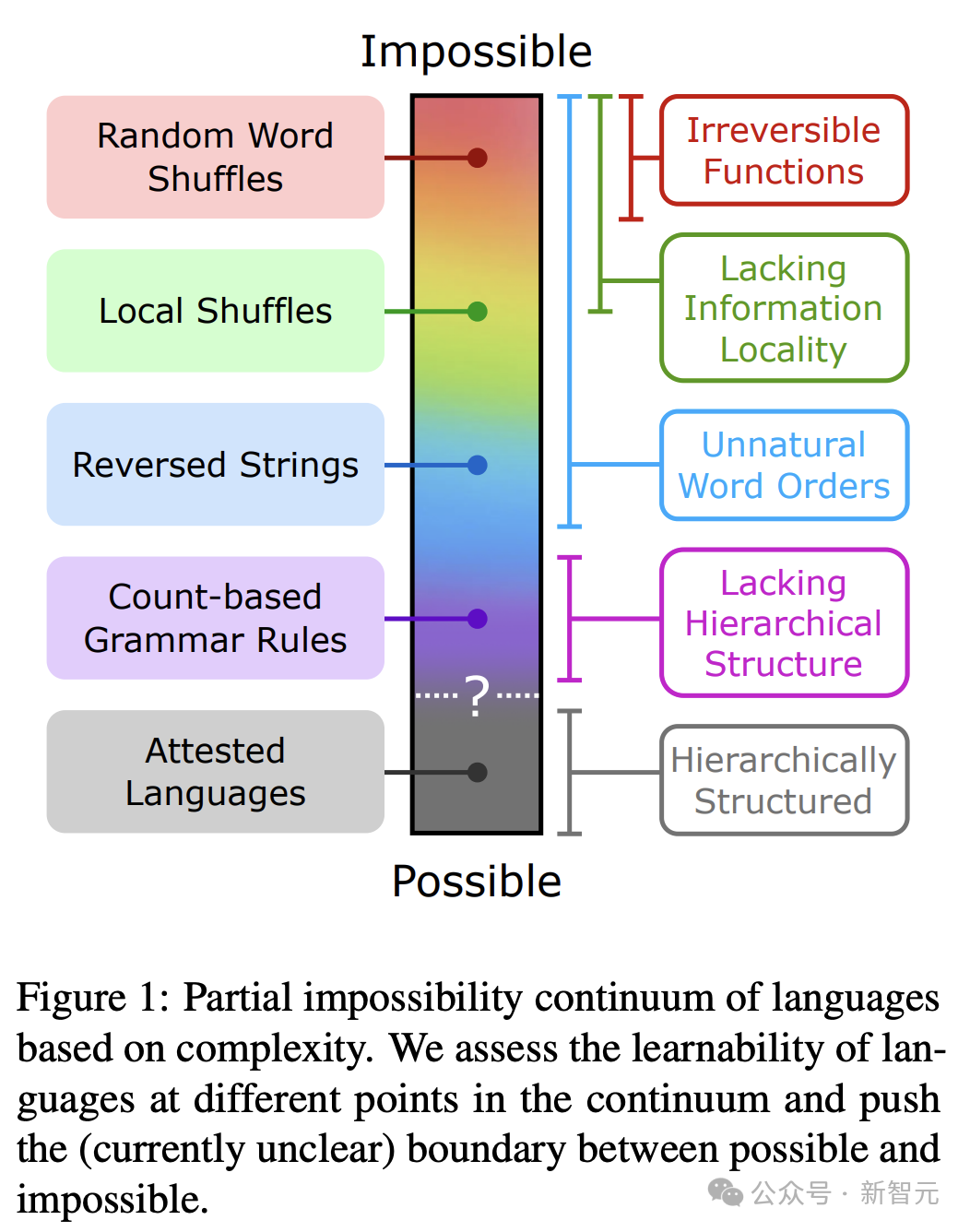
为此,研究人员开发了一组复杂程度不同的合成「不可能语言」,每种语言都是通过系统地改变英语数据,并用非自然词序和语法规则设计而成。
这些语言处在不可能语言的连续体上:一端是完全不可能语言,比如随机重排的英语;另一端是在语言学上被认为是不可能语言,比如基于词位置计数规则。
经过一系列评估,GPT-2 在学习不可能语言方面,非常吃力,这对核心观点提出了挑战。
更为重要的是,研究者希望这种方法能够引发,更多关于 LLM 在学习不同类型语言方面能力的研究,以便更好地理解 LLM 在认知和语言类型学研究中的潜在应用。
论文 6:Semisupervised Neural Proto-Language Reconstruction
作者:Liang Lu, Peirong Xie, David R. Mortensen
机构:卡内基梅隆大学、南加州大学

论文地址:https://arxiv.org/pdf/2406.05930
现有的原生语言比较重建工作,通常需要全程监督。
然而,历史重建模型只有在使用有限的标注数据进行训练时,才具有实用价值。
对此,研究人员提出了一种半监督历史重建任务。
在这种任务中,模型只需在少量标注数据(有原形的同源集)和大量无标注数据(无原形的同源集)的基础上进行训练。
作者研发出一种用于比较重建的神经架构 ——DPD-BiReconstructor,其中包含了语言学家比较方法中的一个重要观点:重建词不仅可以从其子词中重建出来,还可以确定性地转换回其子词中。
研究表明,这种架构能够利用未标记的同源词集,在这项新任务中的表现优于现有的半监督学习基线。
论文 7:Why are Sensitive Functions Hard for Transformers?
作者:Michael Hahn, Mark Rofin
机构:萨尔大学

论文地址:https://arxiv.org/pdf/2402.09963
实证研究已经发现了 Transformer 模型一系列可学习性偏差和局限性,比如在学习计算简单形式语言(如 PARITY)时始终存在困难,而且倾向与低阶函数。
然而,理论上的理解仍然有限,现有的表达能力理论要么过度预测,要么低估了实际的学习能力。
研究人员证明,在 Transformer 架构下,损失景观(loss landscape)受到输入空间敏感性的约束:
那些输出对输入字符串的多个部分敏感的 Transformer 模型,在参数空间中占据孤立点,导致在泛化中出现低敏感度偏差。
研究从理论和实证角度证明,最新理论统一了关于 Transformer 学习能力和偏差的惯犯经验观察,比如它们在饭还中,对地敏感度和低阶函数的偏好,以及在奇偶性问题上难以进行长度泛化。
这表明,理解 transformer 的归纳偏差不仅需要研究其原则上的表达能力,还需要研究其损失景观。
2 篇时间检验奖
论文 1:GloVe:Global Vectors for Word Representation(2014)
作者:Jeffrey Pennington, Richard Socher, Christopher Manning
机构:斯坦福大学

论文地址:https://nlp.stanford.edu/pubs/glove.pdf
词嵌入(word embedding)是 2013 年至 2018 年间 NLP 深度学习方法的基石,并且继续产生重大影响。它们不仅提高了 NLP 任务的性能,还在计算语义方面具有显著影响,如词相似性和类推。
最具影响力的两种词嵌入方法可能是 skip-gram / CBOW 和 GloVe。与 skip-gram 相比,GloVe 提出得更晚,其相对优势在于其概念上的简单性 —— 直接基于单词的分布特征优化它们在向量空间中的相似性,而不是从简化语言建模的角度,将其作为一组参数进行间接优化。
论文 2:Measures of Distibutional Similarity(1999)
作者:Lillian Lee
机构:康奈尔大学

论文地址:https://aclanthology.org/P99-1004.pdf
研究分布相似性度量,目的是改进对未见的共现(concurrence)事件的概率估计,相当于另一种方式表征单词间的相似性。
论文的贡献有三方面:对各种度量方式的广泛实证比较;基于相似度函数所包含的信息进行分类;引入了一种新函数,在评估潜在代理分布方面表现出色。


1 篇最佳主题论文
论文:OLMo: Accelerating the Science of Language Models
作者:Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi
机构:艾伦人工智能研究所、华盛顿大学、耶鲁大学、纽约大学、卡内基梅隆大学

论文地址:https://arxiv.org/abs/2402.00838
这项工作是提高大语言模型训练透明性和可重复性的重大进展,这是社区为了取得进展(或者至少是为了让除了行业巨头之外的其他贡献者也能为进展做出贡献)而迫切需要的。
3 篇最佳社会影响力奖
论文 1:How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs
作者:Yi Zeng, Hongpeng Lin, Jingwen Zhang, Diyi Yang, Ruoxi Jia, Weiyan Shi
机构:弗吉尼亚理工大学、中国人民大学、加州大学戴维斯分校、斯坦福大学

论文地址:https://arxiv.org/abs/2401.06373
这篇论文探讨了绕过限制这一人工智能安全主题。它研究了一种在社会科学研究领域开发的方法。该研究极具吸引力,并有可能对社区产生重大影响。
论文 2:DIALECTBENCH: An NLP Benchmark for Dialects, Varieties, and Closely-Related Languages
作者:Fahim Faisal, Orevaoghene Ahia, Aarohi Srivastava, Kabir Ahuja, David Chiang, Yulia Tsvetkov, Antonios Anastasopoulos
机构:乔治梅森大学、华盛顿大学、圣母大学、RC Athena

论文地址:https://arxiv.org/abs/2403.11009
方言变异是自然语言处理和人工智能中一个研究不足的现象。然而,对它的研究具有极高的价值,不仅在语言学和社会角度上,而且对应用也有重要影响。这篇论文提出了一个创新的基准,用于在大语言模型时代研究这一问题。
论文 3:Having Beer after Prayer? Measuring Cultural Bias in Large Language Models
作者:Tarek Naous, Michael J. Ryan, Alan Ritter, Wei Xu
机构:佐治亚理工学院

论文地址:https://arxiv.org/abs/2305.14456
这篇论文揭示了大语言模型时代的一个重要问题:文化偏见。虽然研究的背景是阿拉伯文化和语言,但结果表明,在设计大语言模型时,我们需要考虑文化的细微差别。因此,可以对其他文化进行类似研究,以推广并评估其他文化是否也受到这一问题的影响。
3 篇最佳资源论文
论文 1:Latxa: An Open Language Model and Evaluation Suite for Basque
作者:Julen Etxaniz, Oscar Sainz, Naiara Perez, Itziar Aldabe, German Rigau, Eneko Agirre, Aitor Ormazabal, Mikel Artetxe, Aitor Soroa
机构:巴斯克大学

论文地址:https://arxiv.org/abs/2403.20266
这篇论文详细地描述了语料库收集和评估数据集的所有细节。尽管他们研究的是巴斯克语言,但这种方法可以扩展用于构建低资源语言的大语言模型。
论文 2:Dolma: an Open Corpus of Three Trillion Tokens for Language Model Pretraining Research
作者:Luca Soldaini, Rodney Kinney, Akshita Bhagia, Dustin Schwenk, David Atkinson, Russell Authur, Ben Bogin, Khyathi Chandu, Jennifer Dumas, Yanai Elazar, Valentin Hofmann, Ananya Harsh Jha, Sachin Kumar, Li Lucy, Xinxi Lyu, Nathan Lambert, Ian Magnusson, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Abhilasha Ravichander, Kyle Richardson, Zejiang Shen, Emma Strubell, Nishant Subramani, Oyvind Tafjord, Pete Walsh, Luke Zettlemoyer, Noah A. Smith, Hannaneh Hajishirzi, Iz Beltagy, Dirk Groeneveld, Jesse Dodge, Kyle Lo
机构:艾伦人工智能研究所,加州大学伯克利分校,卡内基梅隆大学、Spiffy AI、麻省理工学院、华盛顿大学

论文地址:https://arxiv.org/abs/2402.00159
这篇论文阐述了在为大语言模型准备数据集时,数据策展的重要性。它提供了有价值的见解,可以惠及社区内的广泛受众。
论文 3:AppWorld: A Controllable World of Apps and People for Benchmarking Interactive Coding Agents
作者:Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, Niranjan Balasubramanian
机构:纽约州立大学石溪分校、艾伦人工智能研究所、萨尔大学

论文地址:https://arxiv.org/abs/2407.18901
这是一个非常令人印象深刻且重要的尝试 —— 构建一个用于人机交互的模拟器和评估环境。这将鼓励为社区制作具有挑战性的动态基准。
21 篇领域主席奖




35 篇杰出论文

(此图不完整)





参考资料:
https://x.com/aclmeeting/status/1823664612677705762
本文来自微信公众号:微信公众号(ID:null),作者:新智元
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











