




新智元报道
编辑:Mindy 润
[新智元导读]圣达菲研究所的科研人员用非常严谨的定量研究方法,测试出了 GPT-4 在推理和抽象方面与人类水平还有较大差距。要想从 GPT-4 的水平发展出 AGI,还任重道远!
GPT-4,可能是目前最强大的通用语言大模型。一经发布,除了感叹它在各种任务上的出色表现之外,大家也纷纷提出疑问:GPT-4 是 AGI 吗?他真的预示了 AI 取代人类那一天的到来吗?
推特上也有一众网友发起了投票:
其中,反对的观点主要在于:
- 有限的推理能力:GPT-4 被诟病最多的就是不能执行‘反向推理’,而且难以形成对世界的抽象模型进行估计。
- 任务特定的泛化: 虽然 GPT-4 可以在形式上进行泛化,但在跨任务的目标方面可能会遇到困难。
那到底 GPT-4 的推理能力和抽象能力和人类相比,有多大的差距,大家的这种感性似乎一直没有定量的研究作为支撑。
而最近圣达菲研究所的科研人员,系统性地对比了人类和 GPT-4 在推理和抽象泛化方面的差距。

论文链接:https://arxiv.org/ abs / 2311.09247
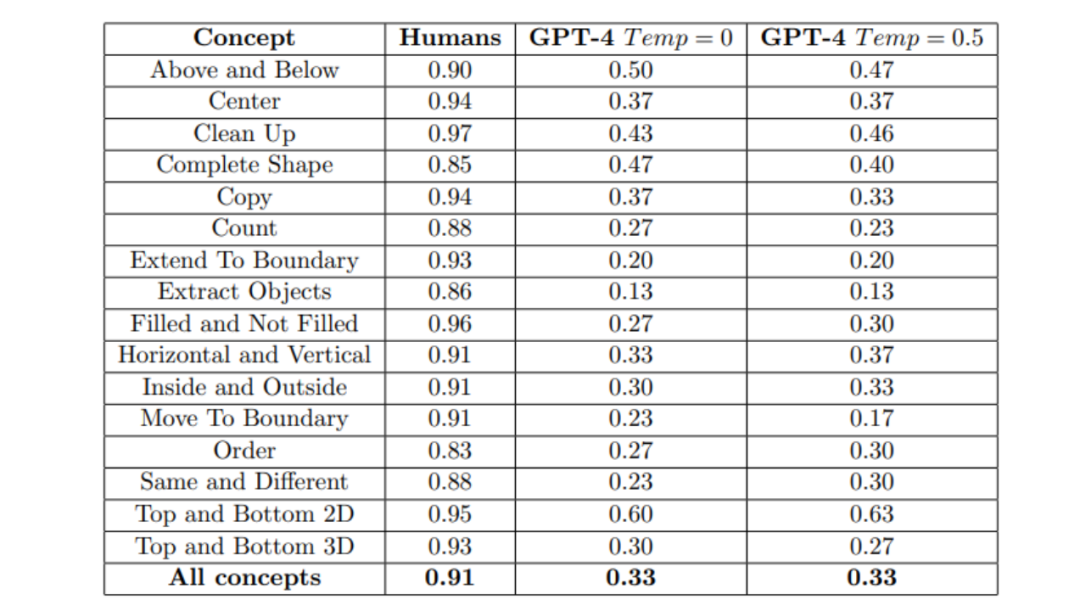
研究人员在 GPT-4 的抽象推理能力方面,通过 ConceptARC 基准测试评估了 GPT-4 文本版和多模态版的表现。结果说明,GPT-4 仍与人类有较大差距。
ConceptARC 基于 ARC 之上,ARC 是一组 1000 个手动创建的类比谜题(任务),每个谜题包含一小部分(通常是 2-4 个)在网格上进行变换的演示,以及一个‘测试输入’网格。
挑战者的任务是归纳出演示的基础抽象规则,并将该规则应用于测试输入,生成一个经过变换的网格。
如下图,通过观察演示的规则,挑战者需要生成一个新的网格。

ARC 设计的目的在于,它强调了捕捉抽象推理的核心:从少量示例中归纳出普遍规律或模式,并能够灵活地应用于新的、以前未见过的情况;而弱化了语言或学到的符号知识,以避免依赖于先前训练数据的‘近似检索’和模式匹配,这可能是在基于语言的推理任务上取得表面成功的原因。
而 ConceptARC 在此基础上,改进为 480 个任务,这些任务被组织成特定核心空间和语义概念的系统变化,如 Top 和 Bottom(上和下)、Inside 和 Outside、Center(里面,外面,中间),以及 Same 和 Different(相同,不同)。每个任务以不同的方式实例化该概念,并具有不同程度的抽象性。
在这种改动下,概念更加抽象,也就是说对人类来说更加容易,结果也更能说明 GPT-4 和人类在抽象推理方面的能力对比。
研究人员分别对纯文本的 GPT-4 和多模态的 GPT-4 进行了测试。
对于纯文本的 GPT-4 来说,研究人员使用更加表达丰富的提示对 GPT-4 的纯文本版本进行评估,该提示包括说明和已解决任务的示例,如果 GPT-4 回答错误,会要求它提供不同的答案,最多尝试三次。
但在不同的温度设置下(温度是一个可调节的参数,用于调整生成的文本的多样性和不确定性。温度越高,生成的文本更加随机和多样,可能包含更多的错别字和不确定性。),对于完整的 480 个任务,GPT-4 的准确率表现都远远不如人类,如下图所示。
而在多模态实验中,研究人员对 GPT-4V 进行了评估,在最简单的 ConceptARC 任务的视觉版本上(即仅仅 48 个任务),给予它与第一组实验中类似的提示,但使用图像而不是文本来表示任务。
结果如下图所示,将极简的任务作为图像提供给多模态 GPT-4 的性能甚至明显低于仅文本情况。

这不难得出结论,GPT-4,可能是目前最强大的通用 LLM,仍然无法稳健地形成抽象并推理关于基本核心概念的内容,而这些概念出现在其训练数据中之前未见过的上下文中。
有位大牛网友对于 GPT-4 在 ConceptARC 上的表现,发了足足 5 条评论。其中一条主要原因解释道:
基于 Transformer 的大型语言模型的基准测试犯了一个严重错误,测试通常通过提供简短的描述来引导模型产生答案,但实际上这些模型并非仅仅设计用于生成下一个最可能的标记。
如果在引导模型时没有正确的命题逻辑来引导和锁定相关概念,模型可能会陷入重新生成训练数据或提供与逻辑不完全发展或正确锚定的概念相关的最接近答案的错误模式。
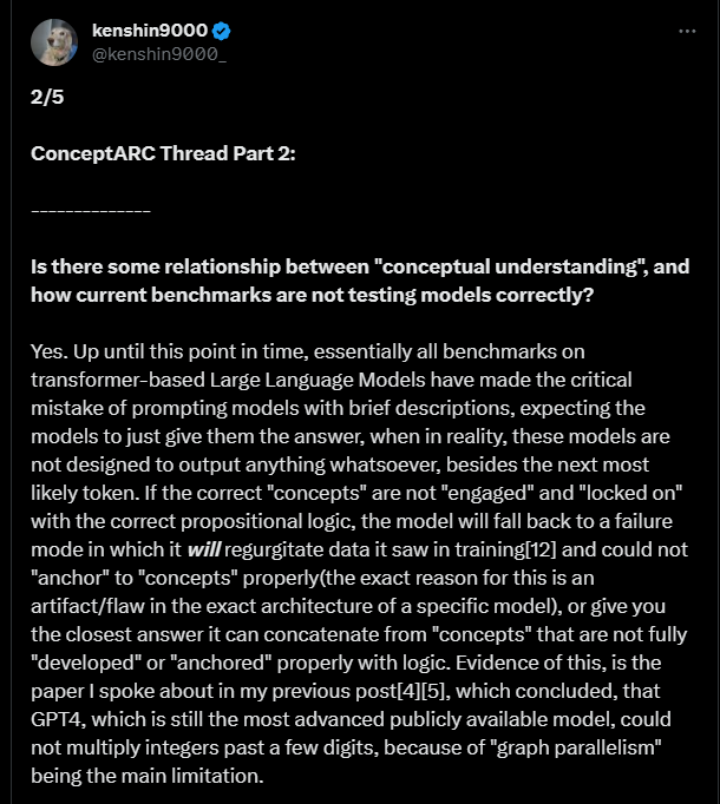
也就是说,如果大模型设计的解决问题的方式是上图的话,那实际需要解决问题可能是下图。


研究人员说,对于提升 GPT-4 和 GPT-4V 在抽象推理能力的下一步,可能尝试通过其他提示或任务表示方法实现。
只能说,对于大模型真的能完全能达到人类水平,还是任重而道远啊。
参考资料:
本文来自微信公众号:新智元 (ID:AI_era)
广告声明:文内含有的对外跳转链接(包括不限于超链接、二维码、口令等形式),用于传递更多信息,节省甄选时间,结果仅供参考,IT之家所有文章均包含本声明。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











