首次将DeepSeek同款RLVR应用于全模态LLM,含视频的那种!
眼睛一闭一睁,阿里通义实验室薄列峰团队又开卷了,哦是开源,R1-Omni来了。
同样在杭州,这是在搞什么「开源双feng」(狗头保命)?
他们都做了啥?
DeepSeek-R1带火了RLVR(可验证奖励强化学习),之前已有团队将RLVR应用于图像-文本多模态LLM,证明其在几何推理和视觉计数等任务上表现优异。
然鹅,尚未探索将其与包含音频、动态视觉内容的全模态LLM结合。
薄列峰团队首次将RLVR与全模态LLM结合,聚焦的是视觉和音频模态都提供关键作用的情感识别任务
团队实验发现,模型在三个关键方面有显著提升:
RLVR的引入不仅提高了模型在分布内数据上的整体性能,而且在分布外数据集上也展现出了更强的鲁棒性。
更重要的是,提升后的推理能力使得能够清晰分析在情感识别过程中不同模态所起的作用。

R1-Omni在X上也吸引了不少网友关注:

还有网友表示可解释性+多模态学习就是下一代AI的方向。
一起具体来看R1-Omni。

在研究方法上,论文首先介绍了DeepSeek同款RLVR和GRPO。
RLVR是一种新的训练范式,其核心思想是利用验证函数直接评估输出,无需像传统的人类反馈强化学习(RLHF)那样依赖根据人类偏好训练的单独奖励模型。
给定输入问题q,策略模型πθ生成响应o,接着使用可验证奖励函数R(q,o)对其进行评估,其优化目标为最大化验证奖励减去基于KL散度正则化项的结果。

RLVR在简化了奖励机制的同时,确保了其与任务内在的正确性标准保持一致。
GRPO是一种全新的强化学习方法,它与PPO等传统方法有所不同,PPO依赖于一个评论家模型来评估候选策略的性能,而GRPO直接比较生成的响应组,避免了使用额外的评论家模型,简化了训练过程。
利用归一化评分机制,GRPO鼓励模型在组内优先选择奖励值更高的响应,增强了模型有效区分高质量和低质量输出的能力。

遵循DeepSeek-R1中提出的方法,团队将GRPO与RLVR相结合
R1-Omni模型构建方面,团队采用了一种受DeepSeek-R1训练方法启发的冷启动策略
在包含232个可解释多模态(视觉和音频)情感推理数据集(EMER)样本和348个手动标注的HumanOmni数据集样本的组合数据集上对HumanOmni-0.5B(一个专为人为场景理解设计的开源全模态模型)进行微调,使模型具备初步推理能力,了解视觉和音频线索是如何对情感识别产生作用的。
之后,通过RLVR训练优化模型,奖励函数由准确率奖励和格式奖励组成,准确性奖励评估预测情感与真实情感的匹配度,格式奖励确保模型输出符合指定的HTML标签格式。
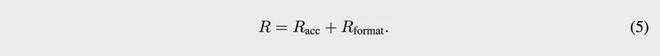

模型输出预期包含两部分:一个推理过程,封装在""标签内,解释模型如何整合视觉和音频线索得出预测;一个最终情感标签,封装在""标签内,表示预测的情感。
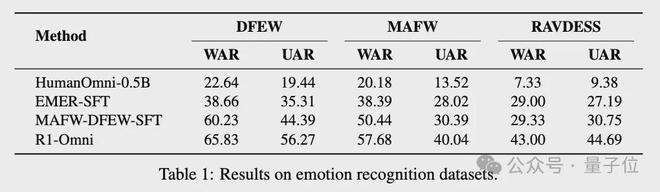
实验评估中,研究者将R1-Omni与三个基线模型进行比较:原始的HumanOmni-0.5B、在EMER数据集上进行监督微调的模型EMER-SFT、直接在MAFW和DFEW训练集上基于HumanOmni-0.5B进行监督微调的模型MAFW-DFEW-SFT
评估指标包括无加权平均召回率(UAR)和加权平均召回率(WAR),这些指标衡量模型在不同情感类别中准确分类情感的能力。
重要的是,所有评估都在开放词汇情感测试(OV-emotion)协议下进行。在这种设置中,模型不提供预定义的情感类别,而是直接从输入数据中生成情感标签,这增加了评估的挑战性和实际应用价值。
实验结果表明,R1-Omni在三个关键方面优于三个对比模型:推理能力增强、理解能力提高、泛化能力更强
研究者展示了一系列可视化示例,比较R1-Omni与其它三个模型的输出,R1-Omni提供了更连贯、准确和可解释的推理过程。
相比之下原始HumanOmni-0.5B和MAFW-DFEW-SFT模型表现出有限的推理能力,而EMER-SFT虽具备一定推理能力但推理过程连贯性较差且容易产生幻觉。

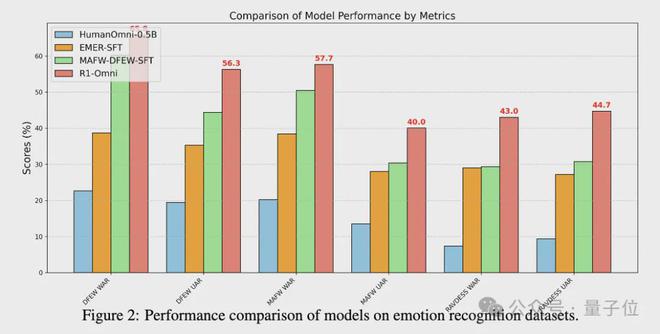
在MAFW和DFEW数据集上,R1-Omni在UAR和WAR指标上均优于其它模型。
例如在DFEW数据集上,R1-Omni实现了65.83%的UAR和56.27%的WAR,明显优于MAFW-DFEW-SFT的60.23%UAR和44.39%WAR。
为了评估模型的泛化能力,研究者在RAVDESS数据集上进行了实验,该数据集作为分布外(OOD)测试集。
与主要由电影片段组成的MAFW和DFEW数据集不同,RAVDESS数据集特点是专业演员以中性北美口音发表词汇匹配的陈述,这种数据分布的显著差异使RAVDESS成为评估模型泛化到未见场景能力的理想基准。
R1-Omni在RAVDESS数据集上相较于MAFW-DFEW-SFT模型有显著提升,实现了43.00%的UAR和44.69%的 WAR。
目前,基础模型HumanOmni-0.5B、冷启动模型EMER-SFT,还有MAFW-DFEW-SFT以及最终模型R1-Omni已全部开源。

[1]https://arxiv.org/abs/2503.05379
[2]https://github.com/HumanMLLM/R1-Omni
















热门推荐
51岁男子找17岁女孩代孕前已离异 收起51岁男子找17岁女孩代孕前已离异
- 2025年03月27日
- 00:31
- APP专享
- 扒圈小记
 34,385
34,385
华为智驾大师赛冠军开智驾出车祸?官方回应:协助进行事故处理和医疗安置,提醒用户规范使用智驾功能
- 2025年03月27日
- 02:19
- APP专享
- 扒圈小记
- 11,932
央行副行长宣昌能:将根据国内外经济金融形势择机降准降息
- 2025年03月27日
- 06:58
- APP专享
- 北京时间
- 4,534

24小时滚动播报最新的财经资讯和视频,更多粉丝福利扫描二维码关注(sinafinance)
投资研报 扫码订阅
股市直播
-

趋势领涨今天 14:39:21
=加入潜伏擒牛VIP,享四大顶级服务=【1】购买VIP自动加入私密小直播间!【2】每周3-5只超短金股调入调出服务,适合实时看盘的投资者!【3】每周一份高端内部绝密文章:包含近期布局、热点版块、指数预判!【4】每月2~3只高端中线金股服务!(VIP超短、中线个股均有涉足,让上班族也能跟上VIP节奏!)现月课7.5折,1288元!季课6.9折,3558元,续费季度更划算!新朋友可先月课体验!点网址,直接买,订购地址:【更多独家重磅股市观点请点击】【更多独家重磅股市观点请点击】 -

数字江恩今天 10:23:30
【3月限时vip活动】3月板块轮动加快,哪些赛道机会更好?数字江恩《股知道VIP》48小时VIP课程2元(原价8元),月课限时特价979元(原价1088元)。活动截止3月31日。【更多独家重磅股市观点请点击】 -
趋势领涨今天 10:07:58
【南向资金今日净买入逾41亿港元 泡泡玛特获净买入居前】南向资金今日净买入41.42亿港元,其中,泡泡玛特、阿里巴巴-W分别合计获净买入约7.25亿港元、3.64亿港元;盈富基金遭净卖出约14.42亿港元。 -
数字江恩今天 09:33:02
明日看3366-3386之间的选择,若先站上3386,那么2-b还可以延伸一点空间;反之,若先跌破3366,则立即确认2-c回踩开始。这里也不用过于担心,2-c确立后,能否跌破3340还两说了,而且哪怕跌破也空间非常有限。第二浪回踩有望在未来三个交易日内结束。 -
数字江恩今天 09:32:57
看5分钟图,今日的脉冲受阻与图上的3297-3341红色轮谷线。截止今日,3340的2-b结构反弹了54个点,和本人预期的50-60个点相吻合,时间也算合适。正常来说,2-b可以结束了。【更多独家重磅股市观点请点击】 -
数字江恩今天 09:32:44
板块上,今日化工板块继续炒作涨价概念,活跃度第一。光刻机、芯片、新能源、医药医疗也算是局部炒作,总的来说,都是局部炒作,市场没有明显热点。 -
数字江恩今天 09:32:38
A股两市今日成交4965 + 6942 = 11907 亿人民币,相对昨日成交金额略微提升,但成交量下跌。大盘今日低开后脉冲拉起新高,然后全天缓缓回调了约一半拉升幅度。个股方面,红盘个股略微超过了1/3,大幅下跌个股家数86家,和大幅上涨个股家数91家相当。 -
数字江恩今天 09:32:30
2-c回踩呼之欲出 -
趋势领涨今天 09:32:07
沪深北三大交易所年内的发行上市审核全线启动。3月26日,北交所召开年内首场上市委会议,四川西南交大铁路发展股份有限公司过会。有业内人士称,目前IPO申报不需要预沟通,发行人和中介机构可视情况进行申报。另有投行人士表示:“IPO申报数量后续将增加,但市场是否回暖还要再观察。”他认为,判断IPO是否常态化,应综合申报受理、发行上市等整体情况考量。这个是下午大盘回落的原因吗?这叫带病工作! -

北京红竹今天 07:59:00
3、短线有增仓2个组合,基本上长线组合没变化,好几天没有交易了,静等大级别调整之后的布局。短线组合昨天是55%的仓位,酱油股大跌没给机会出来,还在持有,早上跌停又买了一只算力10%的仓位,下午差点干到涨停吃个地天板,仓位就上到了65%。大级别末端只能发挥短线的作用,因为不格局,随时可以撤,这里长线和ETF没办法布局,长线需要格局的。