

老黄数字人登场!英伟达秀“元宇宙”肌肉,推巴掌大AI超算和虚拟人平台
 黄仁勋“手办”对答如流,英伟达强势拉开元宇宙序幕,帮企业开发大模型。
黄仁勋“手办”对答如流,英伟达强势拉开元宇宙序幕,帮企业开发大模型。 欢迎关注“新浪科技”的微信订阅号:techsina
文/ZeR0
来源:智东西(ID:zhidxcom)
芯东西11月9日报道,今日,人工智能及高性能计算顶级技术盛会NVIDIA GTC大会如约而至。
这个市值已高达7700亿美元的AI顶级玩家,刚刚推出全球最小、功能最强大、能效最高的下一代AI超级计算机NVIDIA Jetson AGX Orin,其算力达到200TOPS,可与内置GPU的服务器媲美。

在下午的虚拟主题演讲中,NVIDIA创始人兼CEO黄仁勋穿着熟悉的皮衣,公布了一系列最新AI技术和产品,并推出承载着其“元宇宙”愿景的全新虚拟化身平台。
由这个平台生成的“迷你玩具版黄仁勋”Toy-Me,能与人自然地问答交流。

在帮助企业降低AI开发部署门槛方面,NVIDIA可以说是做到了极致,比如提供方便企业构建AI大模型的框架,以及定制专属声音的虚拟助手。
黄仁勋说,NVIDIA开发者数量已接近300万,CUDA过去15年下载量达3000万次,一年下载量达到700万。
此外,NVIDIA继续表露对医疗健康领域的热情,推出搭载新一代Orin芯片、无缝连接医疗设备和边缘服务器的AI计算平台Clara Holoscan。
黄仁勋还宣布,NVIDIA将构建一个数字孪生模型来模拟和预测气候变化,新的超级计算机将名为E-2,即Earth Two,地球的数字孪生,能够在虚拟世界模拟引擎Omniverse中以Million-X百万倍的速度运行。
01.
Jetson AGX Orin:
手掌大小,算力堪比服务器
自2014年推出Jetson TK1至今,NVIDIA Jetson系列已经积累了85万名开发者。
今日,NVIDIA推出全球最小、功能强大、能效最高的新一代AI超级计算机NVIDIA Jetson AGX Orin,用于机器人、自主机器、医疗器械和其他形式的边缘嵌入式计算。
Jetson AGX Orin保持了与前代机型Jetson AGX Xavier相同的外形尺寸和引脚兼容性,处理能力提升6倍,每秒算力达200TOPS,可与内置GPU的服务器相媲美,而尺寸只有手掌那么大。

它采用NVIDIA Ampere架构GPU、Arm Cortex-A78AE CPU以及新一代深度学习和视觉加速器。高速接口、更快的存储带宽和对多模态传感器的支持,为多个并行AI应用流水线输送数据。
与历代Jetson计算机一样,使用Jetson AGX Orin的客户可以运用NVIDIA CUDA-X加速计算栈、NVIDIA JetPack SDK和最新NVIDIA工具进行应用开发和优化,包括云原生开发工作流程。
来自NVIDIA NGC目录的预训练模型已经过优化,并可以使用NVIDIA TAO工具套件和客户数据集进行微调。这减少了生产级AI的部署时间和成本,而云原生技术实现了产品整个生命周期内的无缝更新。

DRIVE AGX Orin同样由Jetson AGX Orin等 NVIDIA Ampere架构提供支持,它是新发布的NVIDIA DRIVE Concierge和DRIVE Chauffeur背后的先进处理器,这两个AI平台分别为安全的自动驾驶提供动力。
针对特定用例的软件框架包括用于机器人技术的NVIDIA Isaac Sim,用于自动驾驶的NVIDIA DRIVE,用于智慧城市的NVIDIA Metropolis。最新的Isaac版本包括对机器人操作系统(ROS)开发人员社区的重要支持。
NVIDIA还发布了用于Isaac Sim的全新NVIDIA Omniverse Replicator,用于为机器人生成合成训练数据。这些硬件加速软件包使ROS开发者更容易在Jetson平台上构建高性能AI机器人。
NVIDIA Jetson AGX Orin模块和开发者工具包将于2022年第一季度上市。

黄仁勋还在演讲中谈道:“到2024年,绝大多数新款电动汽车将具备强大的自动驾驶能力。”
他展示了一个新自动驾驶平台DRIVE Hyperion 8 GA,这是2024年模型的架构。其传感器套件包含12个摄像头、9个毫米波雷达、12个超声波雷达和1个前向激光雷达,所有这些都由2颗NVIDIA DRIVE Orin芯片来进行处理。
据他透露,目前,英伟达已经在全球各地收集到了PB级的道路数据,并拥有大约3000名训练有素的标记员,创建训练数据。尽管如此,合成数据仍是NVIDIA数据策略的基石。

02.
NeMo Megatron:
让企业开发自己的大模型
为了方便企业开发部署大型语言模型,NVIDIA推出了为训练具有数万亿参数的语言模型而优化的加速框架NeMo Megatron。

NVIDIA NeMo Megatron是Megatron的基础上发展起来的。Megatron是由NVIDIA研究人员主导的开源项目,研究大型Transformer语言模型的高效训练。Megatron 530B是全球最大的可定制语言模型。
利用先进的数据、张量和管道并行化技术,它能使大型语言模型的训练有效地分布在成千上万的GPU上。
企业可以通过NeMo Megatron框架,进一步训练它以服务新的领域和语言。经优化,该框架可以在NVIDIA DGX SuperPOD的大规模加速计算基础设施上进行扩展。
除了NeMo Megatron外,NVIDIA还推出了一个开发Physics-ML模型的框架NVIDIA Modulus。
它使用物理原理及源自原理型物理和观测结果的数据训练Physics-ML模型,支持多GPU多节点训练,由此生成的模型,其物理仿真速度比模拟快1000-100,000倍。
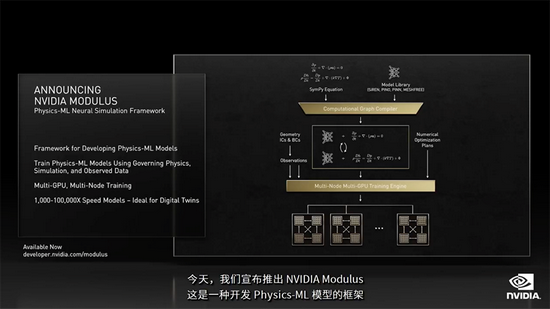
科学家可借助Modulus创建数字孪生模型,来解决预测气候变化等重要科学问题。
例如研究人员利用欧洲中期天气预报中心的ERA5大气数据训练Physics-ML模型,该模型在128个A100 GPU上训练需要4小时,训练后的模型能以30公里的空间分辨率预测飓风严重程度和路径。
原本需要7天才能完成的预测,现在在一个GPU上只需0.25秒,比模拟快了10万倍。
为了帮助企业加快AI之旅,NVIDIA宣布在全球范围内扩展其LaunchPad计划,它允许用户即时访问在加速基础设施上运行的NVIDIA AI软件。企业可使用NVIDIA LaunchPad免费体验开发和部署大型语言模型。
LaunchPad计划由Equinix服务支持,包括数据中心、连接和裸金属产品,获得LaunchPad体验后,企业可以在全球Equinix地点运行其NVIDIA加速的人工智能工作负载。
03.
Riva定制语音:
快速创建定制版品牌声音
NVIDIA的Riva语音AI软件同样有了新进展,黄仁勋宣布了该软件一个新功能——Riva定制语音。

Riva可识别英语、西班牙语、德语、法语、日语、普通话和俄语等7种语言,可以生成隐藏字幕、翻译、摘要、回答问题并理解意图。
只需训练30分钟的音频数据,企业即可构建属于自己品牌大使的声音,获得类似人类的表现力。
也就是说,用户根据特定的领域或行业术语,可以量身定制拥有独特声音的虚拟助理。
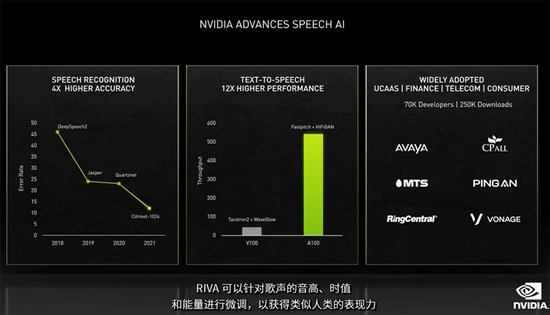
不到三年间,NVIDIA的对话AI软件已被下载超过25万次,并被广泛采用到各个行业。
对于小规模研发,NVIDIA NGC容器注册表免费提供NVIDIA Riva,开发者可加入Riva开放测试版程序来试用该软件。
对于拥有大规模部署并寻求NVIDIA专家技术支持的客户,NVIDIA宣布了NVIDIA Riva Enterprise计划,该计划预计将于明年初推出。
04.
Omniverse Avatar:
构建生动的智能虚拟化身
虚拟助手的下一步,是拥有常识、推理能力和生动的视觉形象。
在GTC大会上,黄仁勋宣布推出一个全方位的虚拟化身平台——Omniverse Avatar。

它是NVIDIA一系列先进AI技术的集大成者,将Metropolis的感知能力、Riva的语音识别能力、Merlin的推荐能力、Omniverse的动画渲染能力等交汇于一体。
这使得开发者能构建出一个完全交互式的虚拟化身,它足够生动,能对语音和面部提示做出反应,能理解多种语言,能给出智能的建议。
黄仁勋展示了一些例子。
比如,其玩偶复制品可以跟人对答如流。

Metropolis工程师用Maxine创建了Tokkio智能操作台应用程序,让操作台具有高度交互性,可快速做出对话响应。
在餐厅,两名顾客点餐时,一个客户服务虚拟化身可以跟他们交谈和理解他们的需求。

这些演示由NVIDIA AI软件和Megatron 530B提供支持,Megatron 530B是目前世界上最大的可定制语言模型。
在DRIVE Concierge AI平台的演示中,中央仪表板屏幕上的数字助理,可帮助司机选择最佳驾驶模式,使其按时到达目的地,然后在汽车续航里程下降到100英里以下时,按他的请求设置提醒。

Maxine项目更强调多种语言的实时翻译和转录。
借助Maxine,这个人的话不仅被转录,还能以相同的声音和语调被实时转换成德语、法语等多种语言。

Maxine使用计算机视觉来追踪人的面部,并识别其表情,3D动画可为其制作虚拟而逼真的头像。
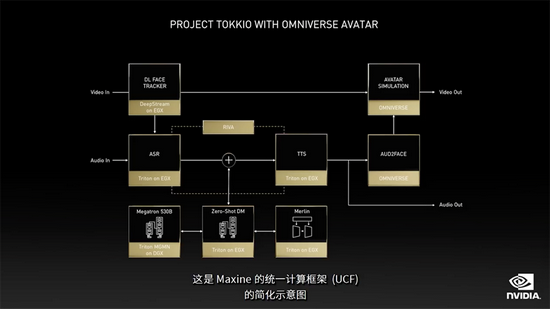
可以想象,在企业和开发人员中,每个行业都需要某种形式的虚拟化身。
使用Omniverse Avatar平台,你可以为视频会议和协作平台、客户支持平台、内容创建、应用收益和数字孪生、机器人应用等等构建定制的AI助理。
NVIDIA的虚拟世界模拟Omniverse是打造虚拟世界的关键平台。从机器人、自动驾驶车队、仓库、工业厂房到整个城市,都能在Omniverse数字孪生中完成创建、训练和运行。
黄仁勋说,Omniverse面向数据中心规模设计,有朝一日有望能达到全球数据规模。
爱立信正构建整个城市的数字孪生环境,帮助确定如何放置和配置每个站点以获得最佳覆盖范围和网络性能,可对整个5G网络执行逼真远程仿真。

05.
AI推理:Triton推理
服务器助力实时大模型推理
目前微软、三星、Snap等25000多家客户都在使用NVIDIA的AI推理平台。
今日,NVIDIA推出多节点分布式推理功能的NVIDIA Triton推理服务器,以及NVIDIA A2 Tensor Core GPU加速器。
NVIDIA A2 GPU是一个入门级、低功耗的紧凑型加速器,适用于边缘服务器中的推理和边缘AI,推理性能比CPU高出20倍。
NVIDIA AI推理平台此次更新包括开源NVIDIA Triton推理服务器软件的新功能,和对NVIDIA TensorRT的更新。
最新NVIDIA Triton推理服务器中的多GPU、多节点特性,使大型语言模型推理工作负载能够实时在多个GPU和节点上扩展。

借助Triton推理服务器,Megatron 530B能在两个NVIDIA DGX系统上运行,将处理时间从CPU服务器上的1分钟以上缩短到0.5秒,令实时部署部署大型语言模型成为可能。
在软件优化上,Triton推理服务器的模型分析器,新工具可以自动化地从数百种组合中为AI模型选择最佳配置,以实现最优性能,同时确保应用程序所需的服务质量。
RAPIDS FIL是针对随机森林和梯度提升决策树模型GPU或CPU推理的新后端,为开发者使用Triton进行深度学习和传统机器学习提供了一个统一的部署引擎。
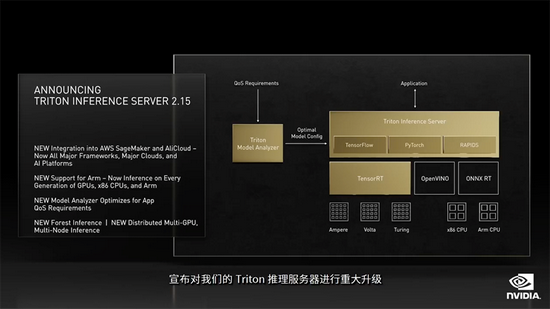
Triton与AWS、阿里云等平台集成,并支持在各代GPU、x86 CPU和Arm CPU上优化AI推理工作负载。NVIDIA AI Enterprise也集成了Triton。
NVIDIA AI Enterprise是一款经NVIDIA优化、认证和支持的用于开发和部署AI的端到端软件套件,客户可利用它在本地数据中心和私有云的主流服务器上运行AI工作负载。
NVIDIA旗舰TensorRT推理引擎亦进行了更新,已原生集成到TensorFlow和PyTorch中,只需1行代码,就能提供比框架内推理快3倍的性能。
NVIDIA TensorRT 8.2是SDK的最新版本,可实时运行数十亿个参数的语言模型。

NVIDIA还宣布微软会议软件Teams采用NVIDIA AI和Azure认知服务。
微软Azure认知服务为高品质AI模型提供基于云的API,以创建智能应用程序。他们在用Triton运行语音转文本模型,为微软Teams用户提供准确的实时字幕和转录。
微软Teams每月有近2.5亿活跃用户,微软Azure认知服务上的NVIDIA GPU和 Triton推理服务器使用28种语言和方言,结合AI模型帮助提升实时字幕和转录功能的成本效益。
Mavenir宣布由NVIDIA Metropolis AI-on-5G平台提供支持的MAVedge-AI智能视频分析,以加速企业人工智能,该方案预计2022年初提供给客户。
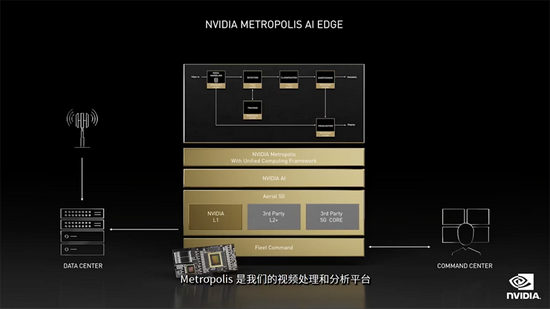
06.
数据中心:全新网络安全功能
面向数据中心,黄仁勋宣布推出BlueField DOCA 1.2来支持全新网络安全功能,希望使BlueField成为业界构建零信任安全平台的理想之选。

目前有1400名开发者正在BlueField上进行开发,现在采用BlueField的网络安全公司已可提供零信任安全即服务。
NVIDIA还发明了一个深度学习网络安全平台Morpheus来监控分析网络行为。
它构建于NVIDIA RAPIDS和NVIDIA AI之上,其工作流会为每种应用和用户的组合创建AI模型和数字指纹,并学习其日常的模式和寻找异常操作。这些异常操作将触发安全警告,并提醒分析员作出响应。

Bluefield、DOCA和Morpheus都是数据中心的全堆栈加速AI解决方案的一部分。NVIDIA将为其网络安全合作伙伴提供一个零信任的安全平台,从而提高安全性和应用程序性能。
Bluefield坐在网络上,向Morpheus AI平台提供数据中心发生的所有活动。Morpheus是一个深度学习网络安全平台,可以监控和分析来自每个用户、机器和服务的所有信息。
NVIDIA今日也宣布了Morpheus早期访问2版本。
Morpheus创建了预训练的用户活动指纹模型。当这些指纹发生变化时,它能够实时识别出异常交易正在发生,创建一个可疑行为正在发生的安全警报,并隔离活动和加以提醒。
07.
医疗健康:合作癌症中心,推新机器人平台
在医疗健康领域,NVIDIA宣布与多家先进癌症中心合作,将AI的力量带到癌症治疗。这些癌症中心将采用NVIDIA DGX来加速开发AI模型。
许多医疗设备公司正在将AI和机器人技术融入其中,在机器人手术、移动CT扫描、支气管镜检中使用NVIDIA加速计算平台。

为加速AI医疗设备的应用,NVIDIA推出一个面向医疗健康行业的新计算平台NVIDIA Clara Holoscan。
Holoscan是继Isaac和Drive后,NVIDIA的第三个机器人平台,能为可扩展、软件定义、端到端流媒体数据处理的医疗设备提供所需的计算基础设施。
该平台集成了NVIDIA AGX Orin和ConnectX-7,FP32算力达5.2TFLOPS,AI算力达250TOPS,740Gbps高速IO用于连接传感器。
添加RTX A6000 Ampere GPU后,可获得另外39TFLOPS(FP32)和超过600TOPS的AI推理性能。

Clara Holoscan是一个医疗设备与边缘服务器无缝连接的端到端平台,能助力开发者创建AI微服务,用以在设备上运行低延迟串流应用,同时将更复杂的任务传至数据中心资源。
借助Clara Holoscan,开发者可以自定义应用,按需在其医疗设备中充分添加或减少计算和输入/输出功能,从而平衡延迟、成本、空间、性能和带宽的需求。
Clara Holoscan SDK通过加速库、AI模型和超声波、数字病理学、内窥镜检查等参考应用支持此项工作,以帮助开发者利用嵌入式和可扩展的混合云计算。
在药物发现方面,加拿大AI制药创企Entos发明了一种深度学习架构OrbNet,用物理机器学习方法训练图神经网络,取代分子模拟中昂贵的原子间作用力,将分子模拟速度提高1000倍。
08.
Quantum-2:史上最先进端到端网络平台
此次GTC期间,NVIDIA还宣布了下一代NVIDIA Quantum-2平台,可进行云原生超级计算。
该网络平台由NVIDIA Quantum-2交换机、ConnectX-7网络适配器、BlueField-3数据处理单元(DPU)和支持新架构的所有软件组成。ConnectX-7将于明年1月问世。

其中,Quantum-2 InfiniBand交换机基于新的Quantum-2 ASIC,采用台积电7N节点,包含570个晶体管,超过有540亿晶体管的A100。
Quantum-2 InfiniBand拥有400Gbps,网络速度翻倍,交换机吞吐量增加了2倍,集群可扩展性增为原来的6.5倍,同时降低了数据中心的功耗。
其多租户性能隔离利用先进的基于遥测的拥塞控制系统,确保可靠的吞吐量,无论用户激增或工作量需求激增,都能确保可靠的吞吐量,从而防止一个租户的活动干扰其他租户的活动。
相比上一代,第三代SHARPv3TM网络计算技术的交换机计算能力比原来高32倍,用于加速AI训练。

09.
新加速库:优化路线规划,加速量子模拟
最后,我们来看看NVIDIA推出的3个新加速库。
首先是NVIDIA ReOpt,这是一款针对运筹优化问题的加速求解器,可实现实时路线规划优化。
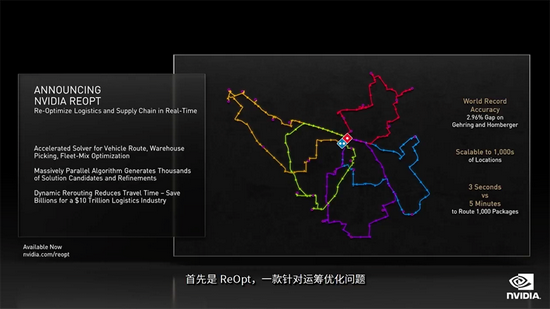
以与NVIDIA合作的达美乐披萨为例,配送14个披萨的路径有870亿种,这意味达美乐要在30分钟内将披萨送达绝非易事。
运筹优化对“最后一英里”配送是必需的,路线规划是个极为棘手的物流问题,如果应用到行业中,即使是小规模的路线优化也能节省数十亿美元。
黄仁勋展示了一个用NVIDIA Omniverse虚拟仓库来展示优化路线在自动订单拣选场景中的影响,优化后的规划能使订单拣选节省一半的时间和路程。
当前路线优化求解器收到新订单后,需要数小时来重新运行和响应,而ReOpt能持续运行并实时动态地进行重新优化,在短短几秒钟内响应并扩展至数千个位置。

第二个是cuQuantum DGX设备,配备有针对量子计算工作流的加速库,可用态矢量和张量网络的方法来加速量子电路模拟。
谷歌Cirq将成第一个得到加速的量子模拟器。
借助该设备,曾经需要耗费几个月的模拟,现在几天就能完成。

NVIDIA研究部门在量子算法模拟方面取得了重要里程碑,用1688个量子位为3375个顶点集求解MaxCut问题。
这是有史以来最大的精确量子电路模拟,比以往模拟的量子位多8倍。
cuQuantum DGX设备将在第一季度推出。
第三个加速库是在PyData和NumPy生态系统的大规模加速计算cuNumeric,它允许用户用Python代码在超级计算机上透明加速和扩展NumPy工作流,并无需更改代码。

它属于NVIDIA RAPIDS开源Python数据科学套件,RAPIDS今年的下载量超过50万次,比去年增长了4倍多。NumPy在过去5年下载量达到了1.22亿次,别用于GitHub上近80万个项目。
在著名的CFD Python教学代码中,cuNumeric能扩展至1000个GPU,而扩展效率仅比线性扩展效率损失了20%。
10.
结语
乘着AI、高性能计算和元宇宙的东风,NVIDIA今年过得可谓风生水起,市值一路扶摇直上,突破7700亿美元。其Omniverse平台更是被分析机构视作NVIDIA一项重要的平台扩张战略。
在这表面风光的背后,NVIDIA的远见和前瞻性不容小觑。无论是如火如荼的AI,还是方兴未艾的虚拟世界,NVIDIA能成为科技热潮的直接受益者,都离不开过去多年对其软硬件产品的打磨。
此次NVIDIA GTC大会期间,我们还将看到更多覆盖深度学习、数据科学、高性能计算、机器人等领域的最新进展,而始于NVIDIA CUDA的加速计算正在这些领域催化效率提升,推动现代科技快速进化、走向未来。

(声明:本文仅代表作者观点,不代表新浪网立场。)


作者简介

智东西







