

谷歌发布最新元学习框架「DVRL」,用强化学习量化模型中每个数据点的价值
你是否还在使用大规模数据集进行无脑训练呢?
实际上,如果数据集包含低质量或标签不正确的数据,通常可以通过删除大量的训练样本来提高性能。
此外,如果训练集与测试集不匹配(例如,由于训练和测试位置或时间的差异) ,人们还可以通过将训练集中的样本限制为与测试场景最相关的样本,从而获得更高的性能。
由于这些场景的普遍存在,准确量化训练样本的值对于提高真实数据集上的模型性能具有很大的潜力。
除了提高模型性能之外,为单个数据分配质量值(quality value)也可以启用新的用例,也可以用来提出更好的数据收集方法。
例如,什么类型的附加数据最有利,并可用于更有效地构建大规模的训练数据集,或者使用标签作为关键字进行网络搜索,过滤掉不太有价值的数据。
量化数据的价值
对于给定的机器学习模型,并不是所有的数据都是相等的。一些数据与手头的任务有更大的相关性,或者相比其他数据有更丰富的信息内容。
那么,到底该如何评估单一数据的价值呢?在完整数据集的粒度上,人们可以简单地在整个数据集上训练一个模型,并将其在测试集上的性能作为数据的价值。
然而估计单一数据的价值要困难得多,特别是对于依赖于大规模数据集的复杂模型,因为在计算复杂度上来说,不可能对一个模型的所有可能的子集进行重新训练和评估。
为了解决这个问题,研究人员探索了基于排列的方法(例如:influence functions)和基于博弈论的方法(例如:data Shapley)。

然而,即使是当前最好的方法也远不能适用于大型数据集和复杂模型,而且它们的数据评估性能也是有限的。
同时,基于元学习(meta learning)的自适应权重分配方法已经被开发出来,用来使用元目标(meta-objective)估计权重值。
但是他们并没有优先考虑从高价值的数据样本中学习,而通常是基于梯度下降法学习或者其他启发式方法得到数据价值的映射。这些方法改变了传统的预测模型的动态训练,会导致与单个数据点的价值无关的性能变化。
使用强化学习评估数据(DVRL)
为了推断数据值,我们提出了一种数据值估计器(DVE) ,该估计器用来估计数据值,并选择最有价值的样本来训练预测器模型。
这种操作基本上是不可微的,因此不能使用传统的基于梯度下降的方法。
相反,Google的研究员们建议使用强化学习(RL) ,这样 DVE 的监督是基于一个奖励Reward,而这个Reward能用来量化预测器在一个很小但干净的验证集上面的性能。
DVRL:Data Valuation Using Reinforcement Learning
在给定状态和输入样本的情况下,Reward指导Policy进行最优化选择,向着最优的数据价值方向进行。

Google AI 研究院以预测模型学习和评估框架为环境,提出了一种新的基于实例推理的机器学习应用方案。

实验结果
结果评估了 DVRL 在不同类型数据集和用例上的数据价值估计的质量。
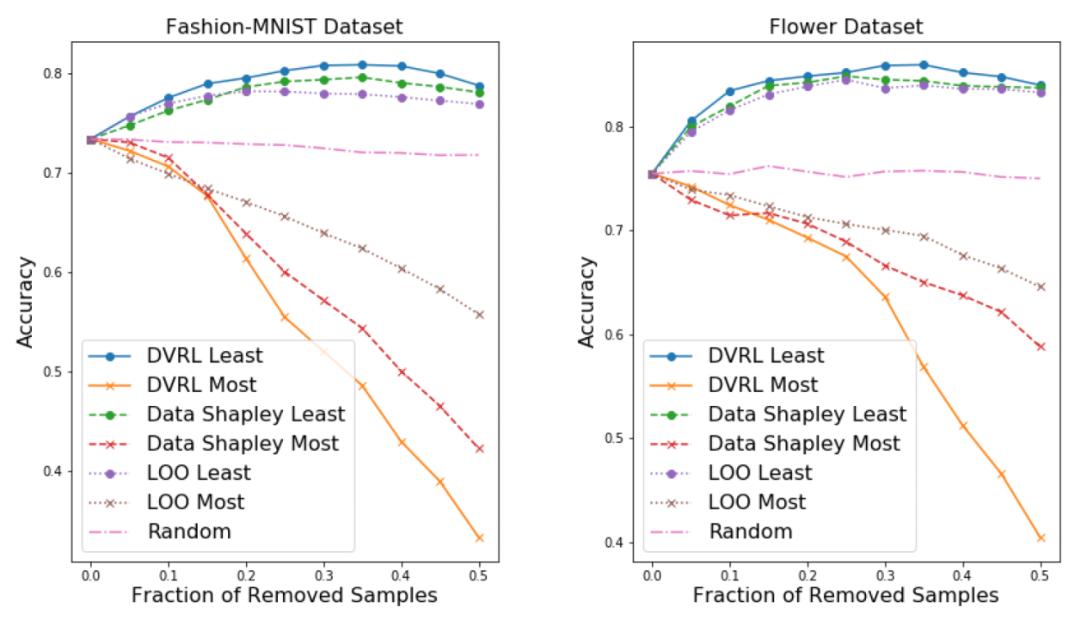
1.去除高/低值样本后的模型性能:
从训练集中剔除低值样本可以提高预测器模型的性能,特别是在训练集中含有损坏样本的情况下。
另一方面,移除高值的样本,特别是当数据集很小时,会显著降低性能。
总体而言,剔除高/低值样本后的表现是数据评估质量的一个强有力的指标
2.带有噪声标签的鲁棒学习:
Google AI的研究人员考虑使 DVRL 在带有噪声标签时可以在端到端的方式中学习,而不必删除低价值的样本。
理想情况下,噪声样本应该得到低数据值,因为 DVRL 会收敛的同时将返回一个高性能模型。
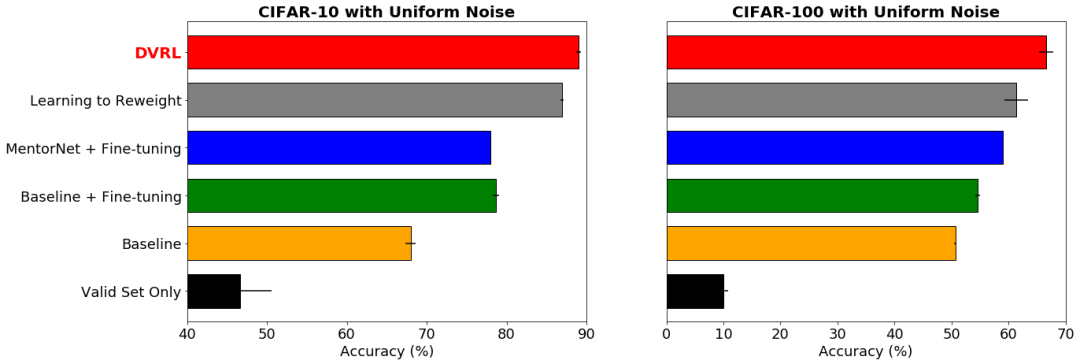
图:数据集的标签上有40% 的均匀随机噪声,DVRL 优于其他流行的基于元学习的方法
结果显示,在最小化噪声标签影响的情况下,DVRL取得了SOTA的结果。这也表明了DVRL可以应用到复杂模型和大规模数据集。
3.领域适应(Domain adaptation):
Google考虑的场景是,训练集来自与验证和测试集完全不同的分布。通过从训练数据集中选择最适合验证数据集分布的样本,数据估值预计将对此任务有所帮助。

DVRL 通过联合优化数据估值器和相应的预测器模型,显著提高了领域的适应性。
结论
Google AI研究院这次提出了一种新的元学习数据评估框架,该框架决定了每个训练样本用在预测模型的训练过程的可能性。
与以往的研究不同的是,该方法将数据评估融入到预测器模型的训练过程中,使得预测器和DVE能够相互提高。
通过使用一个经过 RL 训练的 DNN 对这个数据值估计任务进行建模,并从一个代表目标任务绩效的小验证集中获得奖励。
DVRL 以高效的计算方法提供了高质量的排序后的训练数据,有利于领域自适应、错误样本发现和鲁棒学习,同时还发现了 DVRL 在不同类型的任务和数据集上显著优于其他方法。
参考链接:
https://ai.googleblog.com/2020/10/estimating-impact-of-training-data-with.html

(声明:本文仅代表作者观点,不代表新浪网立场。)

作者简介
作者文章
推荐阅读
- 张康阳接棒王思聪背后,中国电竞的路已越走越宽
-

- 谁也没想到,在今年双十一即将到来之际,率先在社交网络刷足存在感的竟是苏宁。详细>>
- 假如让马云重讲一次蚂蚁
-

- 去年马云也有一个说法产生过类似效应,即“能做996是一种巨大的福报”。详细>>
- 华为过冬的六大启示
-

- 华为历史上经历多次“冬天”,正因为经过了冬天的洗礼,才如历经严寒的牡丹而鲜艳绽放。详细>>
- 凭什么百度就不能收购YY?
-

- 虽然还未正式官宣,但百度收购YY的消息犹如在深水中投下的一颗巨石,引发了互联网圈的关注。详细>>