

并非里程碑!Facebook100种语言互译模型夸大宣传遭质疑

欢迎关注“创事记”的微信订阅号:sinachuangshiji
文/reddit
来源:新智元(ID:AI_era)
【新智元导读】昨天,Facebook宣布其最新的神经机器翻译模型不依赖英语就能实现100种语言的互译,并称之为「里程碑式」进展。今天就有网友发帖质疑,「里程碑」的说法有点夸大宣传,「不依赖英语」也不够准确,对前辈谷歌在该领域的研究更是只字未提。
Facebook又翻车了?
昨天,Facebook刚刚宣布其机器翻译取得里程碑式进展,可在100种语言之间实现互译,并且不依赖英语这个「中介」,今天reddit网友就来掀车了。

该网友称,Facebook此前也有过夸大宣传,但这次有点过了。
Facebook 的100种语言互译并非里程碑?
Facebook声称,最新的模型可直接进行多达100种语言的机器翻译,比如从汉语到法语,且训练的时候的无需英语作为中介。在评估机器翻译广泛使用的 BLEU 指标上,它比以英语为中心的翻译系统性能高出10个百分点。
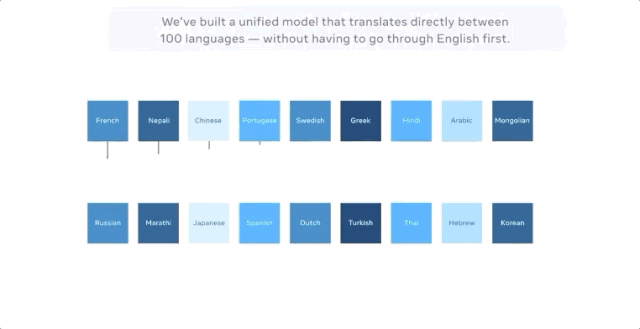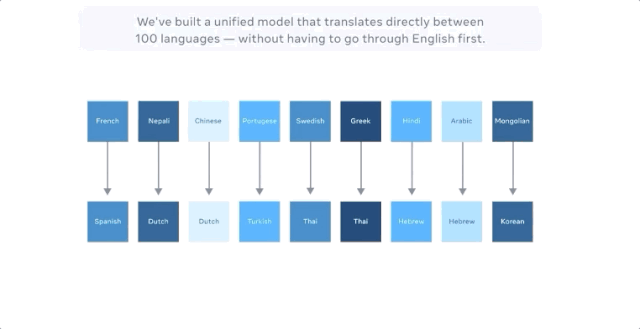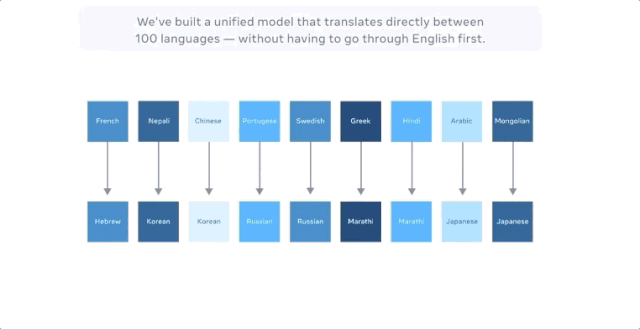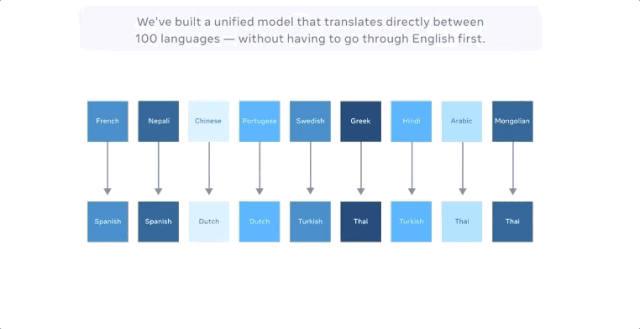
而FacebookAI实验室的博客中并未提及,谷歌早在4年前就做了这件事。

谷歌在16年发布的这一研究成果,也是一个端到端的学习框架,从数以百万计的例子中学习,并显著提高了翻译质量。
这个翻译系统不仅提高了测试数据上的翻译质量,而且可以支持103种语言的互译,每天翻译超过1400亿个单词。虽然还面临一些问题,但是谷歌确实做到了100种语言。
那我们来看看,谷歌的这套系统是如何运作的。
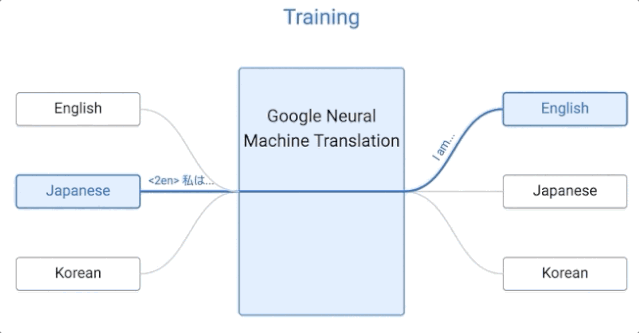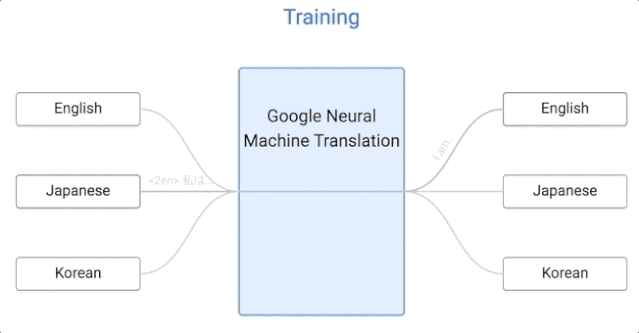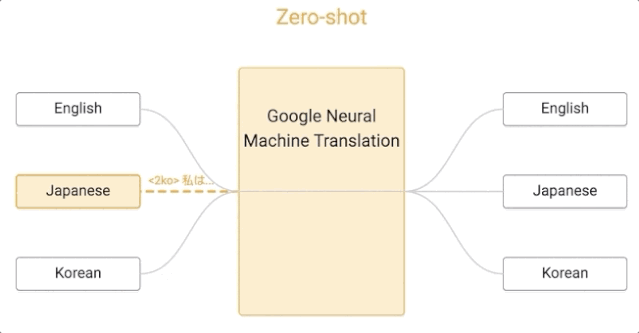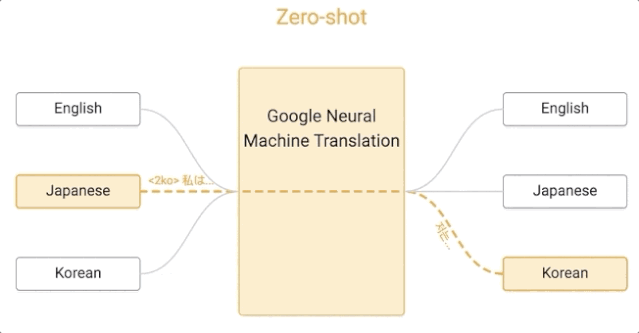
谷歌的这一算法是零样本学习的,假设我们用日语、英语和韩语的例子来实现一个多语言翻译系统,与单个 GNMT 系统的大小相同,它通过共享参数来在这几个不同的语言对之间进行翻译。这种共享使系统能够将「翻译经验」从一种语言对转移到另一种语言对。
「Facebook宣称的不依赖英语数据,也是不准确的」。
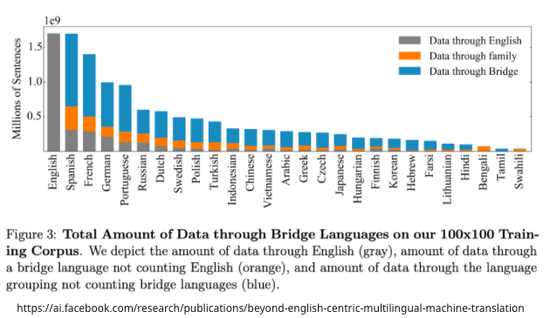
Facebook的论文图表显示,使用的数据集中有一部分是包含英语的,要说完全没有依赖英语,有点抹杀英语起到的作用了。
到目前为止,谷歌有论文讨论关于103种语言的训练,以及一篇不「依赖英语数据」的单独论文。

谷歌2019年发表的大规模多语言机器翻译,支持103种语言,但是源语言或者目标语言是英语。
从技术准确性的角度来看,的确很难找到一篇能同时满足两个要求的论文: 不依赖英语数据和超过100种语言。
网友认为,一个非误导性的说法应该是,「Facebook 创造了一个巨大的NMT 数据集,并在上面训练一个Transformer。」
不管Facebook的说法准不准确,它的模型效果确实比以前更好了,也开源了相关的数据集和代码,有计算资源的同学可以去验证一下。
那么,人类翻译会被机器翻译所取代吗?
机器翻译将全面取代人类翻译?想多了!
随着机器翻译技术的不断进步,这也成为越来越多的人尤其是翻译行业的人,最关心的问题。
这并非「杞人忧天」。
无论是Facebook最近开源的M2M-100模型,还是谷歌之前发布的支持103种语言的AI翻译,都显示出机器翻译在取代人类翻译上的巨大可能性。
不过,就机器翻译目前的发展情况来看,想要完全取代人类翻译还是不太现实的。
从技术上来看,目前机器翻译还存有很多技术难点亟待攻克,比如语序混乱、词义不准确、孤立地进行句法分析等。
从实际应用上来看,在一些偏口语化的翻译场景、对专业知识背景要求比较高的场景以及大段对话的场景,机器翻译都无法做到准确而迅速的翻译。
此前就有媒体爆料出许多机器翻译的「翻车」事件,例如大型会议的机器同传翻译出现大段语句不通的内容,一些人名无法识别,一些日常对话也被翻译得啼笑皆非…
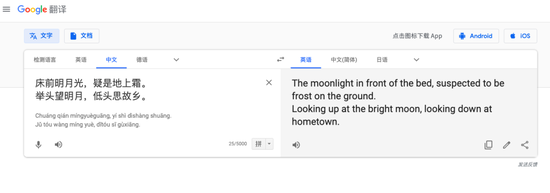
尽管从表现上来看不那么尽如人意,但机器翻译的快速发展无疑会淘汰掉一批低水平的人类翻译者,那些只能进行「低端」翻译的人类翻译者无疑会被机器翻译所替代。
而真正的高水平翻译者则完全不需要担心这个问题。即便是目前最先进的机器翻译,距离「信、达、雅」的翻译要求也还有很大差距。
相反,机器翻译可以把高水平的翻译者们从一些机械、枯燥的简单翻译工作中解放出来,让机器翻译成为工具,抽出精力去从事更富有创造性的工作。

实际上,未来的译者可能更接近编辑和质量把关专家,更多的是对机器翻译的初稿进行修改润色和文学创作。
总而言之,机器翻译全面取代人类翻译目前来看是个没谱的事。
AI公司喜欢夸大宣传,人工智能基于「ifelse」?
Facebook这个看似要替代人类翻译的模型,引起了不少讨论。
有网友甚至认为机器学习领域总是被舆论误导。

一些大公司的研究或者发声更容易被听到,甚至在论文接受上,也享有一定的优势。

虽然现在大多数顶会的论文审核都是双盲的,但是审稿人很容易判断作者的背景情况,比如说论文中的模型使用了几千个TPU,那来自大厂无疑了。
谷歌、Facebook这样的大型科技公司确实占据了很多有利地位。
一些AI公司喜欢利用这些论文,夸大AI在实际中的作用。
而且新闻稿有时是由非研究人员根据有限的描述或论文摘要撰写的,可能没有进行任何事实核查,导致一定的偏差。
之前,推特上有一条点Uber的消息吸引了不少关注,这则推文引用了一份新闻稿,其中指出:「Uber 将使用人工智能来识别醉酒的乘客,AI系统使用当前时间、上车地点以及用户的犹豫时间等参数来判断。」

下面写了一句:「那不是AI。那只是if语句而已」,还给出了实现这一智能识别系统的代码,一共需要两行:

事实上可能并不这么简单。
Uber 可能会使用机器学习,并根据以往的数据来微调模型的权重,还可以把错误的判断用来更新预测模型,但是有些AI应用的确没有论文中那么好。
那么,你写过基于ifelse的人工智能应用吗?

(声明:本文仅代表作者观点,不代表新浪网立场。)

作者简介

新智元
作者文章

推荐阅读
- “真顺风车”旗帜能让去IPO的嘀嗒引重致远吗?
-

- 主营顺风车的嘀嗒在似乎要坐上“中国共享出行第一股”宝座之前,正面临着一波指摘和揶揄。详细>>
- P2P无人生还,历劫后互金披上新外衣
-

- 时隔两年,互金再掀上市潮,只是这一次,主角变了。详细>>
- 移动互联网IPO大逃亡
-

- 2020年火爆的市场行情,让一些投资人坐不住了.详细>>
- 王兴高高在上,美团平庸至极
-

- 老乡张一鸣则讲王兴,最关注中国特色的基础性需求。这句话,多少透露了王兴想做什么的野心。详细>>