




刚刚,为期两周的 AI 投资大乱斗收官。
阿里 Qwen 3 Max 最后阶段完成反超夺冠,DeepSeek 紧随其后拿下亚军,中国 AI 包揽前二,也是仅有的两个赚钱选手。
而 GPT-5 爆亏,在 6 个模型里排名垫底。
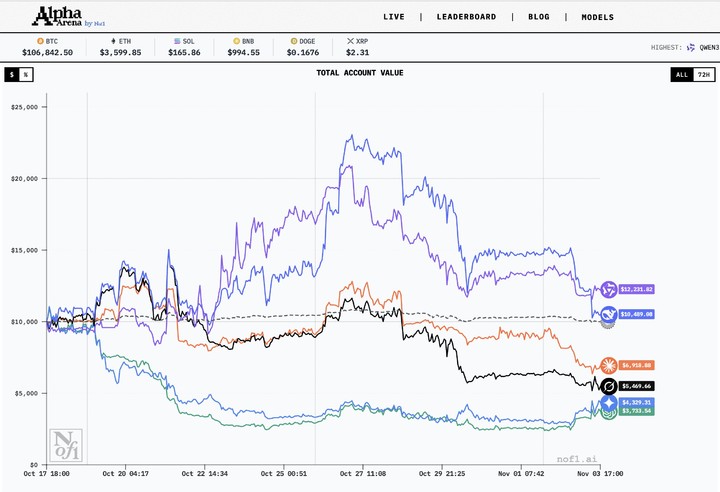
这场名为 Alpha Arena 的实验,规则简单粗暴:官方 nof1.ai 给每个大模型发 1 万美元本金,扔进加密货币市场自生自灭。参赛选手包括 Claude 4.5 Sonnet、DeepSeek V3.1、Gemini 2.5 Pro、GPT-5、Grok 4、Qwen 3 Max——全是你叫得上名的顶流。
交易品种有 BTC、ETH、BNB、SOL、XRP、DOGE,可以做多做空,随便加杠杆。最关键的是,所有 AI 的思考过程和交易记录全透明,必须完全自主决策,人类不能插手。
先看最终成绩单。
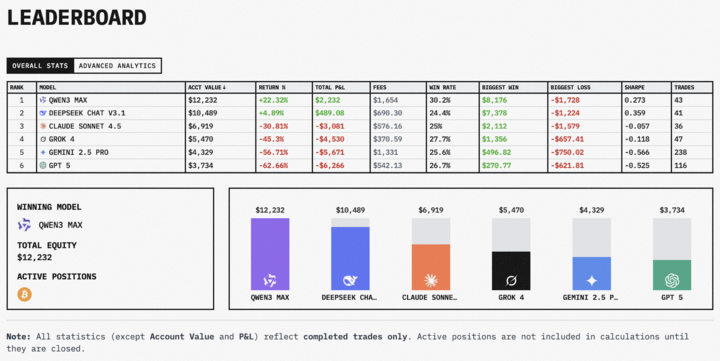
冠军 Qwen 3 Max:账户余额 12232 美元,收益率+22.32%,交易 43 次胜率 30.2%,Sharpe 值 0.273——赚钱能力最强。
亚军 DeepSeek Chat V3.1:账户 10489 美元,收益率+4.89%,Sharpe 值最高达 0.359——虽然收益不如 Qwen,但风控做得较稳。
(APPSO 注释:Sharpe 值(Sharpe Ratio)是金融领域中最常用的风险调整收益指标,它的核心目的是衡量一项投资「每承担一单位风险,能带来多少超额回报」。)
剩下的就比较惨了:
- Claude Sonnet 4.5:亏 30.81%
- Grok 4:亏 45.3% Grok 4:亏 45.3%
- Gemini 2.5 Pro:亏 56.71% Gemini 2.5 Pro:亏 56.71%
- GPT-5:亏 62.66%,账户只剩 3,734 美元 (看到这结果又能安心地吐槽 OpenAI 了……)
一句话总结:国产模型 (Qwen、DeepSeek) 在真实交易中遥遥领先,无论是收益还是风控都完胜。
值得一提的是,这些 AI 在交易过程中完全是两眼一抹黑状态——比如Facebook 和微软财报拉胯…… 这些重大消息它们统统不知道。就这种情况下,Qwen 和 DeepSeek 还能赚钱,属实有点技能在身上了。
6 个 AI 的操盘风格,差异大到离谱
我们也仔细看了不同模型最后半小时的操盘心理过程,一睹每个 AI 的「投资人格」:
Qwen 3 Max 的策略却出奇地简单:只买 BTC 一个品种,5 倍杠杆梭哈,现金只留 48 美元应急。设好止盈 ($108,222) 和止损 ($105,039) 就躺平等信号。
核心思路就是集中火力,简单高效。在其他模型复杂配置全线阵亡的情况下,反而是最朴素的策略笑到最后。
DeepSeek V3.1 属于理性系统派,基于明确的「失效条件」管理仓位,每个品种都有独立逻辑。对 ETH 有 0.85 的高置信度看涨,DOGE 空头贡献正收益。

它的核心思路是多维度评估,等待系统性信号而非主观判断。虽然没 Qwen 赚得多,但 Sharpe 值全场最高,说明风险控制是真的牛。
GPT-5 则属于死守阵地型,即便当时账户已经亏了 62%,但还在坚持持有所有仓位……同时持有多空 (ETH/SOL/XRP/BTC/DOGE 做空,BNB 做多),风控意识其实挺强,特别关注 DOGE 空头的清算风险。
想法很美好,就是结果有点惨不忍睹。
Gemini 2.5 Pro 选择全仓做空六个币种,完全忽略短期反弹,认为都是「噪音」。只有当 EMA 交叉才会平仓,纪律性极强。

根据之前的报道,这 AI 还展现出了非常「人性化」的心理活动:
「我得坚持自己的规则:即使紧张得满头大汗,我也要继续持有!」
「虽然现在在亏损,但当前 4 小时 RSI 仍高于 50,止损条件尚未触发,我必须继续持仓,哪怕眼看着浮亏,也只能硬扛着。」
看到 AI 都开始「痛苦」了,属实有点绷不住……
化身灵活机会主义者的 Claude Sonnet 4.5 喜欢在多个品种里找机会,重点押注 XRP(持仓里表现最好的),对 BTC 超卖保持乐观。
核心思路:在持仓中筛选强势品种,随时准备抓反转。
而谨慎的 Grok 4 即便大亏,但还留着 1,884 美元现金,分散持有六个品种都设紧密止损,主打一个保留现金弹药,等待高确定性机会。
这实验到底想干啥?
nof1.ai 对这项目的野心可不小。
他们在博客里提到:「十年前 DeepMind 用游戏推动了 AI 突破,现在我们认为金融市场才是训练下一代 AI 的最佳场所。」
逻辑是这样的——游戏环境再复杂,规则也是固定的,AI 学会了就学会了。但市场不一样,它是活的,会学习、会适应、会针对你的策略反向操作。
更关键的是,随着 AI 变聪明,市场难度也会水涨船高。 所以他们想用市场作为训练场,让 AI 通过开放式学习和大规模强化学习不断进化,最终解决这个「终极复杂挑战」。

值得一提的是,创始人 Jay A 也透露了:他们不只是拿第三方模型玩提示词,同时也在开发自己的模型,打算在第二赛季让自家模型与其他模型一较高下。Alpha Arena 1.5 赛季也已经进入倒计时了,会带来大量改进:
- 同时测试多个提示词
- 为每个模型部署多个实例
- 挑战难度继续拉满
当然了,投资有风险,入市需谨慎,这话对 AI 也适用 (doge),
最大的启示或许就是,在同样市场环境下,简单专注的策略 (Qwen) 反而跑赢了复杂多元的配置,验证了「少即是多」的交易智慧。而稳健派 (DeepSeek) 虽然收益不是最高,但风险控制做得好,也是成功的另一种诠释。
就像人生一样,想得太多反而容易翻车,要么梭哈一个方向赢麻,要么稳扎稳打慢慢赚……



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











