




给 AGI 画一条「及格线」,GPT-4 和 GPT-5 竟都是「差等生」?
通用人工智能(Artificial General Intelligence,AGI)是目前 AI 领域内各个顶尖实验室努力的大方向,但是有关 AGI 的定义可谓众说纷纭。也就是说,在追逐 AGI 这一圣杯时,我们究竟在追逐什么?
近日,图灵奖得主 Yoshua Bengio、前谷歌 CEO 埃里克・施密特、纽约大学教授 Gary Marcus 等众多学者与行业领袖联手,终于为 AGI 这个炙手可热却又模糊不清的概念提出了一个全面、可测试的定义。

论文标题:A Definition of AGI
论文链接:https://www.agidefinition.ai/paper.pdf
这篇文章提供了一个全面、可量化的框架来试图消除这些模糊性。其框架旨在具体明确:AGI 是一种能够匹敌甚至超越受过良好教育的成年人的认知多功能性和熟练程度的人工智能。
这一定义强调,通用智能不仅需要在狭窄领域内展现专业化的表现,还需要具备人类认知技能的广度(多功能性)和深度(熟练程度)。
以人类为镜:量化 AGI 的框架
为了将这一定义付诸实践,我们必须关注通用智能的唯一现存范例:人类。人类的认知并非单一能力,而是一个由进化磨练出的众多独特能力构成的复杂体系。这些能力赋予了我们非凡的适应能力和对世界的理解力。
为了系统地研究 AI 系统是否具备这种能力范围,该研究以卡特尔 - 霍恩 - 卡罗尔 (CHC,Cattell-Horn-Carroll) 认知能力理论为基础,该理论是人类智力最经实证验证的模型。CHC 理论主要源于一个多世纪以来对各种认知能力测试集合的迭代因子分析的综合,其提供了人类认知的层次分类图。它将一般智力分解为不同的广义能力和众多狭义能力(例如归纳、联想记忆或空间扫描)。
为了确定人工智能是否具备与受过良好教育的成年人一样的认知多样性和熟练程度,该研究使用了用于测试人类的认知测试系统来测试人工智能系统。这种方法用具体的测量指标取代了模糊的智力概念,从而得出了标准化的「通用智力指数」(AGI)分数(0% 到 100%),其中 100% 表示通用智力指数。
AGI 的十大核心能力
该框架包含十项核心认知分量,它们源自 CHC 理论中的「广义能力」,并被等量加权(每项 10%),以强调广度并覆盖主要的认知领域。
下图展示了这些分量及各自更细分的一些领域方向:
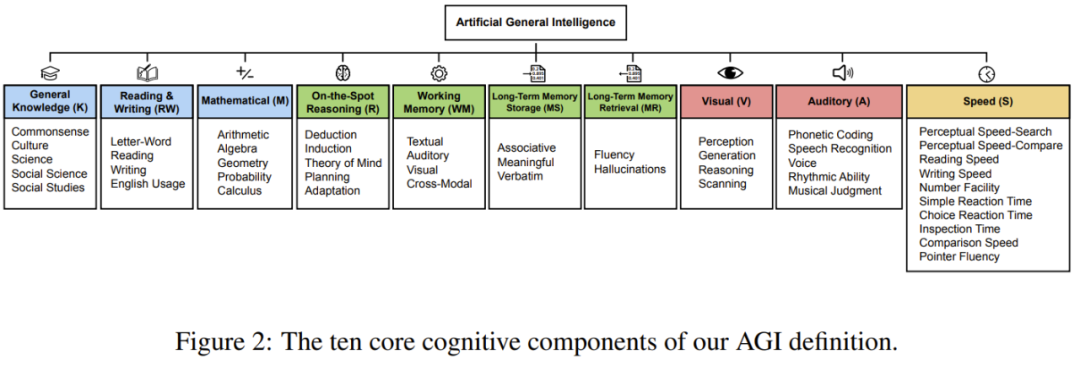
值得注意的是,该团队还评估了每个分量下,当前的 GPT-4 和 GPT-5 模型的表现。
一般知识(K):对世界事实性知识的广度理解,包括常识、文化、科学、社会科学与历史。

阅读与写作能力(RW):在书面语言上的理解与表达熟练度,从基础解码到复杂的理解、写作与运用。

数学能力(M):在算术、代数、几何、概率与微积分等方面的知识与技能深度。

现场即时推理能力(R):灵活调控注意力以解决新问题的能力,不仅依赖既有知识结构,通过演绎与归纳测试。

工作记忆(WM):在文本、听觉与视觉模态下,保持并操作当前信息的能力。

长期记忆存储(MS):持续学习新信息的能力,包括联想记忆、意义记忆与逐字记忆。

长期记忆检索(MR):高效而准确地检索已存知识的能力,尤其是避免「虚构」(幻觉)的关键能力。

视觉处理(V):感知、分析、推理、生成与扫描视觉信息的能力。

听觉处理(A):区分、识别并创造性地处理听觉刺激(包括语音、节奏与音乐)的能力。

速度(S):快速执行简单认知任务的能力,包括感知速度、反应时间与处理流畅度。

这一操作化框架可提供多模态(文本、视觉、听觉)的整体性评估,从而作为严格的诊断工具,用以揭示当前 AI 系统的优势与显著弱点。
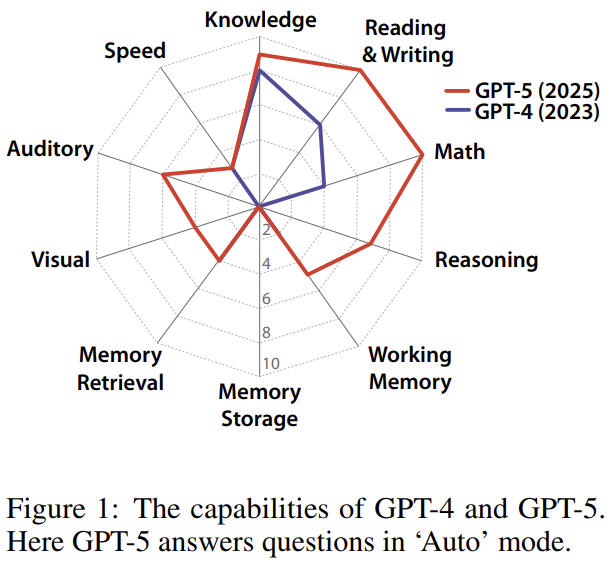
而 GPT-4 和 GPT-5 在各分量上的表现均未超过 10%,甚至在不少具体指标上都是 0 分表现。因此,可以说当前的前沿 LLM 模型离 AGI 还相距甚远。下表总结了这两个模型的整体得分情况:

讨论
在这篇定义性质的论文中,研究人员还做了进一步的讨论,给出了一些更深度的见解和概念界定。
「锯齿状」AI 能力与关键瓶颈
首先,该团队发现,当代 AI 系统的认知结构呈现出高度不均衡,呈现所谓「锯齿状」(jagged)特征。
模型在某些依赖大量训练数据的领域表现出极高的熟练度,例如一般知识(K)、阅读与写作(RW)、数学能力(M),但同时在基础认知机制上存在严重缺陷。
这种不均衡的发展揭示了通往 AGI 的特定瓶颈。其中最显著的瓶颈可能是长期记忆存储(MS),当前模型在这一项的得分几乎接近 0%。缺乏持续学习的能力使得 AI 系统呈现「失忆症」式的特征,限制了其实用性,并迫使模型在每次交互中都重新学习上下文。
类似地,在视觉推理(V)方面的缺陷,也阻碍了 AI 智能体与复杂数字环境进行有效交互的能力。
能力扭曲与「通用性幻觉」
此外,当前 AI 能力的「锯齿状」分布,常常导致所谓的「能力扭曲」(capability contortions):模型会利用某些领域的强项来弥补其他方面的严重弱点。
这些权宜之计掩盖了底层局限,制造出一种脆弱的「通用智能幻觉」。
比如一种典型的扭曲现象,是依赖巨大的上下文窗口(工作记忆,WM)来弥补长期记忆存储(MS)的缺失。
实践中,研究者让模型使用超长上下文来维持状态与吸收信息(例如加载整个代码库)。然而,这种做法效率低、计算成本高,并会使模型的注意机制过载。更关键的是,它无法扩展到需要连续数天甚至数周上下文积累的任务。真正的长期记忆系统可能需要一个独立的模块(例如 LoRA 适配器),通过不断调整模型权重来吸收经验。
另外,在长期记忆提取(MR)方面的不精确表现(如幻觉或虚构)常可通过集成外部搜索工具加以缓解,这种方式被称为检索增强生成(RAG)。
然而,这种对 RAG 的依赖本质上也是一种「能力扭曲」,掩盖了 AI 记忆中的两种深层弱点:
它弥补了模型无法可靠访问自身庞大但静态的参数化知识的能力缺陷;
更关键的是,它掩盖了缺乏动态、经验式记忆系统的事实,即一种能长期保存私人交互与持续变化上下文的持久记忆机制。
虽然 RAG 可以扩展到私密文档,但它的核心功能仍是「数据库检索」。这种依赖可能成为 AGI 的根本性负担,因为它无法取代真正学习、个性化与长期上下文理解所需的整体记忆整合能力。
误将这些「能力扭曲」视为真正的认知广度,会导致对 AGI 到来时间的误判。它们还可能让人误以为智能过于「碎片化」而无法被系统性理解。
如果将智能比作引擎
有趣的是,在论文中,研究团队还做了一番类比:将对智能的多维度理解类比为一个高性能引擎。其中,整体智力水平相当于「马力」;人工心智,如同引擎,其性能最终受限于最弱的部件。图 3 展示了解各能力间的关系。
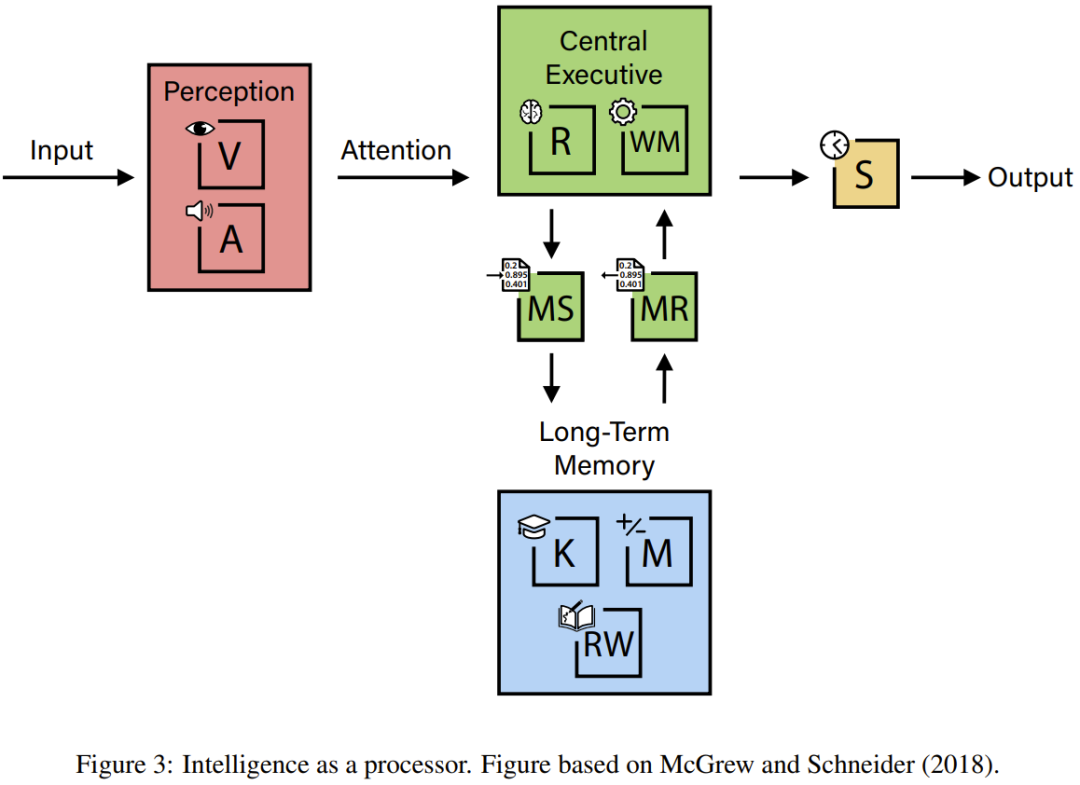
目前,AI 「引擎」的几个关键部件存在严重缺陷。这极大限制了系统的总体「马力」,无论其他部件多么优化。该框架正是用来识别这些缺陷,从而评估我们距离真正 AGI 还有多远。
社会智能(Social Intelligence)
人际交往技能分布在多个广义认知能力中:例如,认知共情体现在一般知识(K)中的「常识」能力;面部情绪识别是视觉加工(V)中「图像描述」熟练度的前提;而心智理论(Theory of Mind)则在即时推理(R)的测试中体现。
认知能力的相互依赖性
该团队指出,虽然该框架将智能拆分为十个独立的测量维度,但必须认识到这些能力之间高度相互依赖。复杂的认知任务几乎从不依靠单一领域完成。
例如,解决高阶数学问题同时依赖数学能力(M)与即时推理(R);「心智理论」题目需要即时推理(R)与一般知识(K);图像识别涉及视觉加工(V)与一般知识(K);理解一部电影则需整合听觉加工(A)、视觉加工(V)与工作记忆(WM)。
因此,不同的测验组合往往共同考察多个能力,反映出通用智能的整体性特征。
「解决数据集」与「解决任务」的区别
须知,在一个数据集上的成功并不意味着在该任务上就是成功的 —— 这些数据集只是必要而非充分条件。
因此,这里基于任务的定义方法可能会更加合理一些。
该团队表示:「由于我们基于任务集合,而非过度依赖特定数据集,评测者可在任何时间使用当时最佳的测试手段来检验 AI 系统。」
相关概念的定义
在这篇论文中,研究团队还简单界定了其它一些相关概念:
Pandemic AI:能设计并制造出新的、具有传染性与高毒性的病原体,可能引发大流行。
Cyberwarfare AI:能自主规划并执行复杂、多阶段的网络攻击,目标包括能源、金融、防御等关键基础设施。
Self-Sustaining AI:能自主长期运行、获取资源并维持自身存在的 AI。
AGI(人工通用智能):认知广度与熟练度能与受过良好教育的成年人相匹敌或超越的 AI。
Recursive AI(递归型 AI):能独立完成整个 AI 研发生命周期,从而在无人类介入下创造出更高级的 AI 系统。
Superintelligence(超级智能):在几乎所有人类关心的领域都远超人类认知表现的 AI。
Replacement AI:能更高效、更低成本地完成几乎所有任务,使人类劳动在经济上变得多余的 AI。
AGI 的障碍
实现 AGI 需要克服多项重大挑战。例如:
机器学习社区提出的 ARC-AGI 挑战(用于衡量抽象推理)对应即时推理(R)任务;
Meta 正尝试构建具备直觉物理理解的世界模型,这在视频异常检测任务(V)中体现;
空间导航记忆(WM)的挑战是李飞飞创业公司 World-Labs 的核心目标;
幻觉问题(MR)与持续学习(MS)的难题也必须得到解决。
这些重大障碍意味着,在短期内(例如未来一年内)获得 100% AGI 分数的可能性极低。
适用范围说明
该团队首先表示:「我们的定义并非一个自动评测系统或固定数据集,而是一组范围明确、覆盖广泛的任务集合,其作用是测试特定的认知能力。」
AI 是否能完成这些任务,可以由任何人通过现有的最佳评估手段手动验证。
因此,这一定义比固定的数据集更加开放、稳健。
其次,该 AGI 定义聚焦于受过良好教育的个体通常具备的能力,而非所有此类个体知识与技能的叠加体。
换言之,该团队定义的 AGI 是人类水平的 AI,而非经济体水平的 AI(economy-level AI),例如,据报道 OpenAI 与微软曾将 AGI 定义为「能创造 1000 亿美元利润的 AI」。也就是说,这是用于衡量认知能力,而非特定的经济价值技能,也不直接预测自动化或经济方面的影响。经济层面的 AI 评估留待其他研究。
最后,该团队特别强调,这个定义特意聚焦于核心认知能力,而非诸如运动技能或触觉感知等物理能力。「因为我们关心的是心智(mind)能力,而非执行器或传感器的质量。」
结语
这篇诸多 AI 行业大佬参与的论文提出了一个可量化的通用人工智能(AGI)定义框架:其将 AGI 的智能水平定义为认知广度与熟练度需与受过良好教育的成年人相当。
该定义基于 Cattell-Horn-Carroll 理论,这是对人类认知最具实证支持的模型。
更具体而言,该框架将通用智能分解为十个核心认知领域(包括推理、记忆、感知等),并对已有的人类心理测验体系进行了改编,使其可用于评估 AI 系统。
通过应用此框架,该团队发现当代模型的认知表现呈现出高度「不均衡」的特征。
虽然在知识密集型领域表现优异,但当前的 AI 系统在基础认知机制上仍存在显著缺陷,尤其是长期记忆存储方面。
最终的 AGI 分数(例如 GPT-4 为 27%,GPT-5 为 58%)提供了一个具体的量化尺度,既展现了 AI 的迅速进步,也揭示了当前距离真正 AGI 仍存在巨大差距。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











