




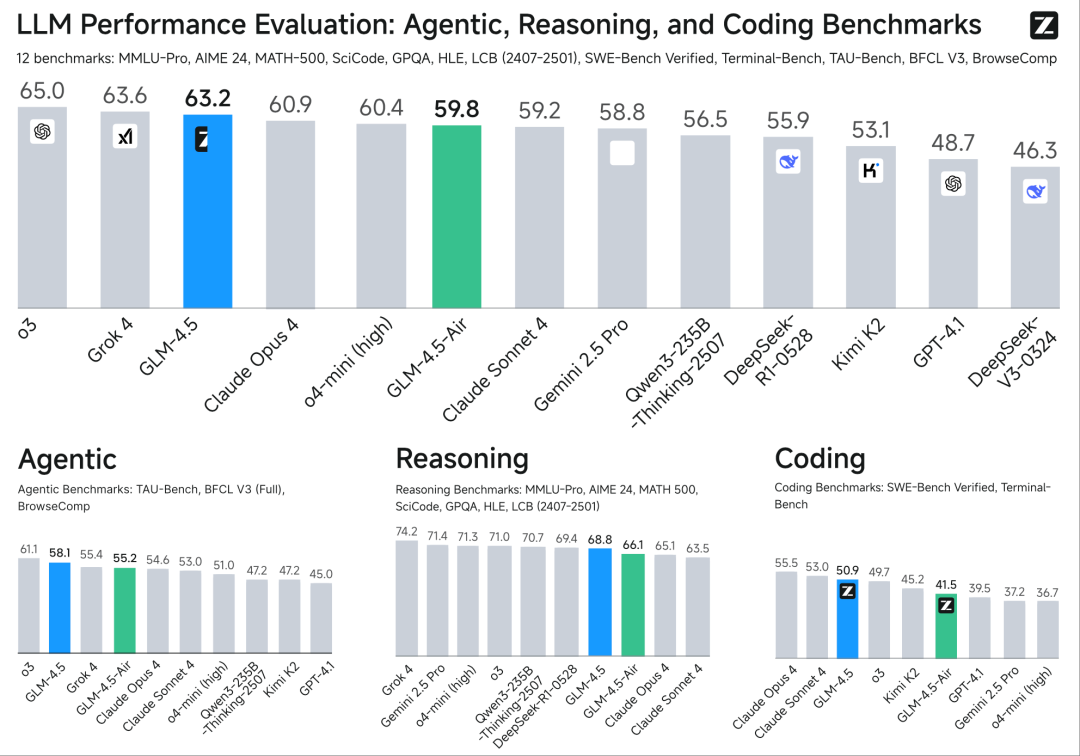
就在上个月底,智谱放出重磅炸弹 —— 开源新一代旗舰模型 GLM-4.5 以及轻量版 GLM-4.5-Air。其不仅首次突破性地在单个模型中实现了推理、编码和智能体能力的原生融合,还在 12 项全球公认的硬核测试中取得了全球第三的综合成绩。这个成绩在所有国产模型和开源模型中均排名第一!
消息一出,瞬间刷屏社交网络:官方推文的浏览量突破 120 万, GLM-4.5 模型更是连续 7 天登顶 Hugging Face 趋势榜单,引发海内外 AI 圈热议。
社交平台上,研究者与开发者纷纷点赞,不断分享 GLM-4.5 系列在各类基准上的最新测试成绩。
就在热度持续升温之际,OpenAI 也开源了备受期待的 gpt-oss 系列模型。网友第一时间将它与 GLM-4.5 放到一起比拼,而后者的整体表现依旧锋芒毕露。
这时,爱学习的读者自然会问:GLM-4.5 是怎么炼成的?虽然智谱此前在技术博客里披露过部分细节,但大家一直期待的完整技术报告迟迟未见。
今天,这一悬念终于揭晓 ——GLM-4.5 的技术报告已正式发布。报告不仅详述了 GLM-4.5 的预训练与后训练细节,还介绍了为其打造的开源强化学习(RL)框架 slime,它兼具灵活性、效率与可扩展性,可为模型高效 RL 训练保驾护航。

报告标题:GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
报告链接:https://arxiv.org/abs/2508.06471
GitHub:https://github.com/zai-org/GLM-4.5
Hugging Face:https://huggingface.co/zai-org/GLM-4.5
GLM-4.5 技术报告也被 Hugging Face 用户投票为今天的「#1 Paper of the day」。
下面我们就来看一看这个国产第一大模型究竟是如何炼成的,但在此之前,我们需要了解智谱为什么做出了这样一个决定:将智能体、推理、代码能力统一到一个单一模型中。
为何「大一统」智能体、推理、代码?
大语言模型(LLM)正在迅速进化 —— 从通用知识库迈向通用问题求解器,其最终目标是在广泛领域内达到人类级认知水平,这不仅仅需要特定任务中达到专家水平,更需要在复杂问题求解、泛化能力和自我改进等方面实现统一突破。
随着 LLM 越来越深入地融入现实世界场景,提升实际生产力和解决复杂专业任务的关键在于发展出更多核心能力。智谱研究团队认为,衡量 AGI 的第一性原理,是在不损失原有能力的前提下融合更多通用智能能力。
衡量真正通才模型的标准应包括以下三项相互关联的关键能力:
与外部工具和现实世界互动的智能体(Agentic)能力;
在数学和科学等领域解决多步骤问题的复杂推理(Reasoning)能力;
应对现实世界软件工程任务的高级代码(Coding)能力。
这三项能力可合称为 ARC 能力。
然而,现有模型仍然算不上真正的通才模型。尽管 OpenAI 的 o1/o3 和 Anthropic 的 Claude Sonnet 4 等 SOTA 专有模型在数学推理或代码修复等特定 ARC 领域展现了突破性性能,但仍未有一个同时在上述所有三个领域均表现卓越的强大开源模型。
GLM-4.5 正在为此努力,力求在一个模型中集成所有这些不同的能力。GLM-4.5 采用了混合推理模式:复杂推理和智能体任务采用思考模式,即时响应采用非思考模式。
GLM-4.5 是如何「练」成的?
模型架构
GLM-4.5 采用了 MoE(混合专家)架构,这种架构能够显著提升训练和推理时的计算效率。
更具体而言,智谱在 MoE 层采用了 loss-free balance 路由和 sigmoid gate 机制。与 DeepSeek-V3 和 Kimi K2 的设计思路不同,他们选择了「瘦高」的模型结构 —— 减少模型的宽度(包括隐藏维度和路由专家的数量),同时增加模型的深度(层数)。他们发现:更深的模型在推理能力上表现更加出色。
在自注意力机制方面,他们采用了 partal RoPE 的分组查询注意力(Grouped-Query Attention)。另外,他们将注意力头的数量增加到了一般模型的 2.5 倍(在 5120 的隐藏维度下使用 96 个注意力头)。有意思的是,虽然增加注意力头的数量并没有让训练 loss 更低,但在 MMLU 和 BBH 等推理基准测试中,GLM-4.5 的表现却得到了稳定提升。
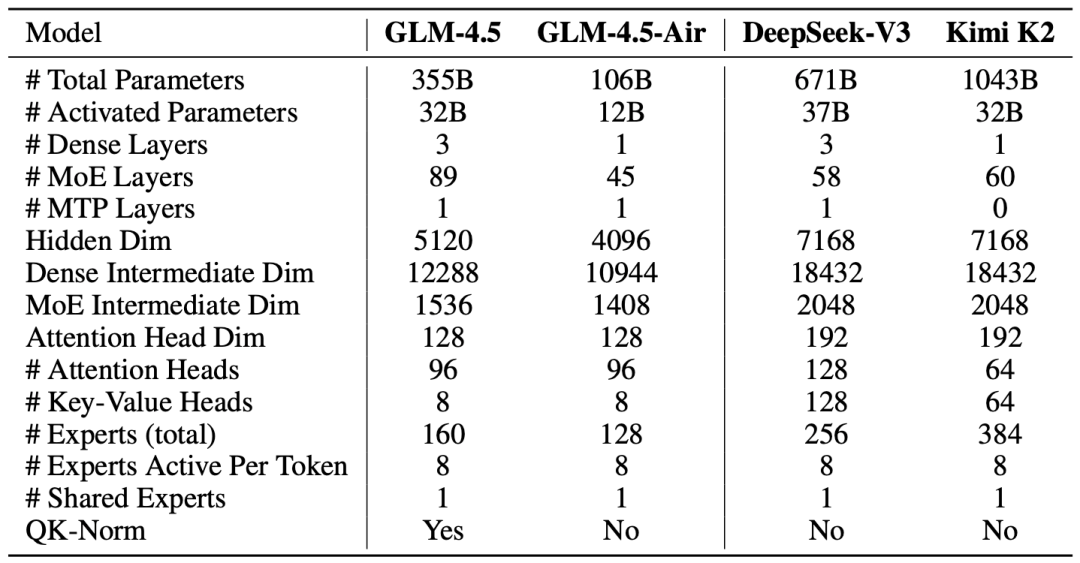
GLM-4.5 系列模型架构,参数数量包含 MTP 层的参数,但不包含词嵌入和输出层的参数。
GLM-4.5 使用了 Muon 优化器,这个优化器不仅能加快模型收敛速度,还能在更大的 Batch Size 下相比 AdamW 保持更好的收敛效果,从而提升训练效率。
他们还引入了 QK-Norm 技术来提升注意力 logit 的数值稳定性。GLM-4.5 还加入了 MTP(Multi Token Predition)层,用于在推理阶段实现推测解码,进一步提升推理效率。
预训练和中期训练
GLM-4.5 经历了几个训练阶段。在预训练期间,GLM-4.5 首先在 15T token 的通用预训练语料库上训练,然后在 7T token 的代码和推理语料库上训练。预训练后,他们引入了中期训练来进一步提升 GLM-4.5 在专有领域上的性能。
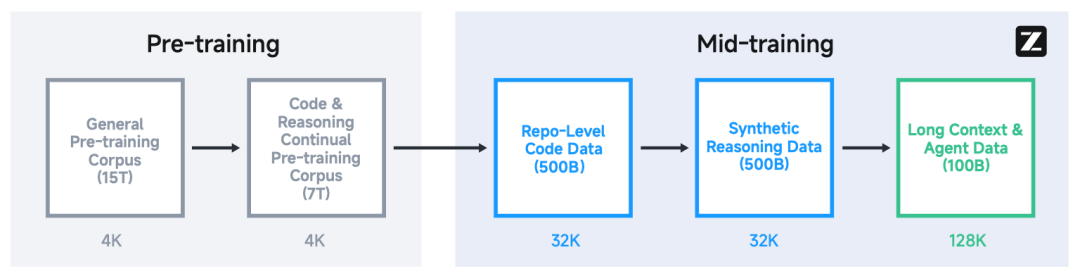
GLM-4.5 的预训练和中期训练,采用多阶段训练方案,并将序列长度从 4K 扩展至 128K。
GLM-4.5 的预训练数据来源于网页、社交媒体、书籍、论文和代码仓库,并针对不同来源设计了优化处理流程。
预训练分为两个阶段,第一阶段主要使用一般网页文档,第二阶段重点上采样编程、数学和科学相关的高质量数据,从而兼顾高频知识、长尾知识覆盖以及推理能力的提升。
中期训练阶段旨在在预训练基础上进一步增强推理能力和智能体能力,采用中等规模的领域特定数据集和指令数据,主要包括以下三个环节:
代码仓库级训练:将同一仓库的代码文件拼接,学习跨文件依赖,并引入经过模型筛选的 GitHub issue、PR 和 commit,以提升软件工程能力。并将序列长度扩展到 32K。
合成推理数据训练:收集来自网页和书籍的数学、科学、编程相关问答数据,并用推理模型生成推理过程,从而强化模型的推理能力。
长上下文与智能体训练:将序列长度从 32K 扩展到 128K,上采样长文档,并加入大规模合成的智能体轨迹数据,以提升长文本处理和多步交互能力。
在预训练阶段,最大序列长度保持为 4096,而在中期训练阶段,最大序列长度从 32768 扩展至 131072。在预训练阶段,研究团队未采用 best-fit packing,因为随机截断可以作为对预训练文档的数据增强策略。在中期训练阶段,他们应用了 best-fit packing,以避免截断推理过程或仓库级别的代码。
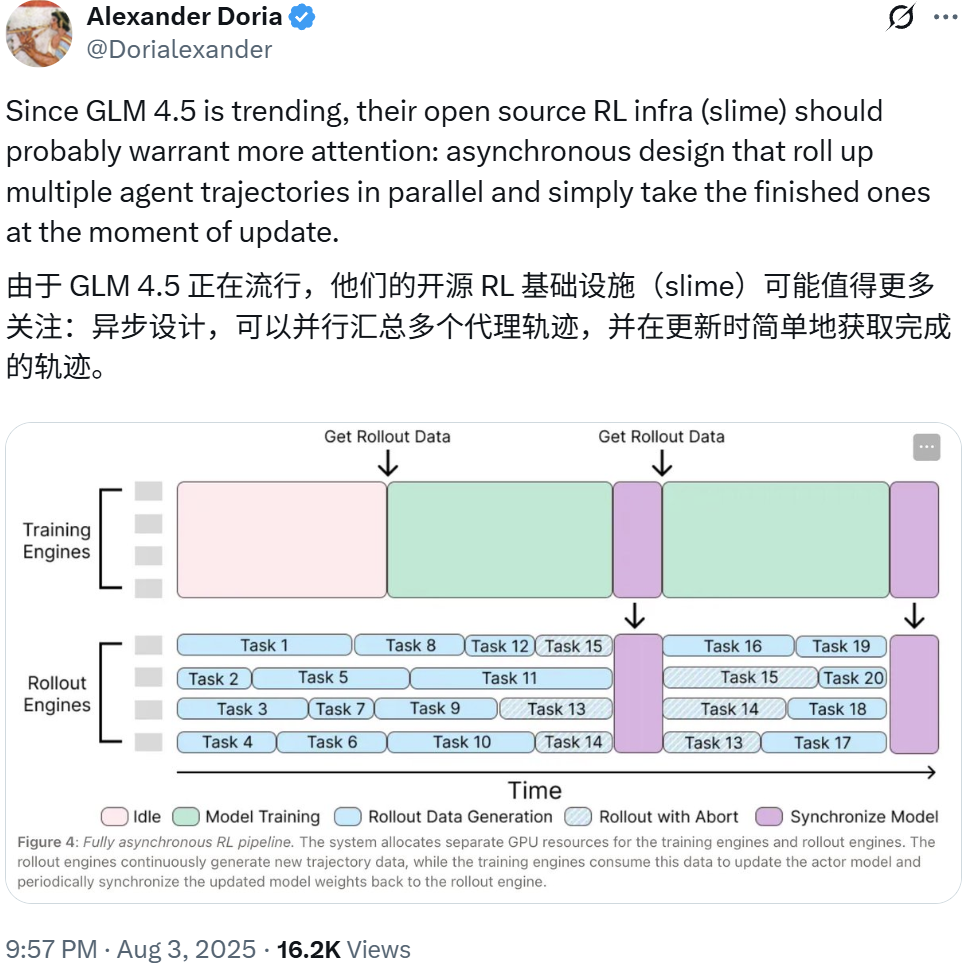
基于 slime 的大模型强化学习
为了支持 GLM-4.5 这样的大模型进行高效的强化学习(RL)训练,智谱设计、开发并开源了 slime。这是一个在灵活性、效率和可扩展性方面都表现卓越的 RL 框架。该框架已经发布了一些时日了,并已经在 GitHub 上收获了近 1200 star。
开源地址:https://github.com/THUDM/slime
具体而言,slime 由三个核心模块组成:
训练(Megatron),处理主要的训练过程,从 Data Buffer 读取数据,并在训练结束后将参数同步到 rollout 模块;
rollout(SGLang + Router),生成新的数据,包括奖励和验证器输出,并将其写入 Data Buffer;
Data Buffer,作为桥接模块,管理提示词初始化、自定义数据和 rollout 生成策略。
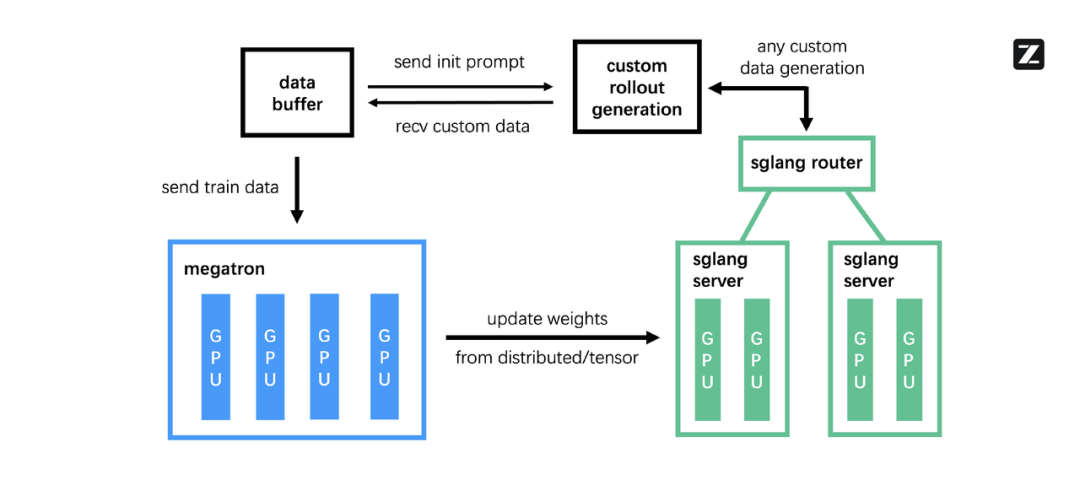
slime 旨在解决强化学习中的常见瓶颈,并针对复杂的智能体任务做了优化:
灵活的混合训练架构: slime 的核心优势在于其多功能的混合架构。它既支持同步、集中式训练(适合推理和通用强化学习训练),也支持分布式、异步训练模式。这种异步模式对于 Agentic RL 至关重要,因为在这类场景中,数据生成往往是一个缓慢的外部过程。通过将训练与数据收集解耦,可以确保训练 GPU 始终保持满负荷运行,最大化硬件利用率。
面向智能体的解耦设计: Agentic RL 经常面临环境交互时延迟高且分布长尾的问题,这严重限制了训练吞吐量。为此,slime 实现了完全解耦的基础架构,将环境交互引擎与训练引擎分离。这两个组件在不同的硬件上独立运行,将数据生成的瓶颈转化为可并行化的非阻塞过程。这种设计是加速长序列智能体任务的关键。
混合精度加速数据生成: 为了进一步提升吞吐量,slime 采用混合精度推理来加速环境交互。它使用 FP8 精度进行数据生成(Rollout),同时在模型训练中保留 BF16 精度以确保训练稳定性。这种技术在不影响训练质量的前提下,大幅提升了整体训练速度。
这种整体化的设计使得 slime 能够无缝集成多个智能体框架,支持各种任务类型,并通过统一而强大的接口高效管理长序列环境交互。
增强智能体能力的后训练
后训练对 LLM 至关重要,模型通过自主探索和积累经验来不断优化策略。强化学习是突破模型能力边界的关键步骤。
GLM-4.5 不仅整合了 GLM-4-0414 的通用能力和 GLM-Z1 的推理能力,还重点提升了智能体能力,包括智能体编程、深度搜索和通用工具使用。
训练过程首先在精选的推理数据和合成的智能体场景数据上进行监督微调,然后通过专门的强化学习阶段分别训练专家模型。
推理能力训练:智谱完整的 64K 上下文长度上进行单阶段强化学习,采用基于难度的课程学习来进行多阶段 RL。为了确保训练稳定性,智谱引入了改进的技术:使用动态采样温度来平衡探索与利用,以及在 STEM 问题上使用自适应裁剪来保证策略更新的稳定性。
智能体任务训练: 训练聚焦于两个可验证的任务:基于信息检索的问答和软件工程任务。智谱开发了可扩展的策略来合成基于搜索的问答对,方法是通过人工参与的内容提取和选择性地模糊网页内容。编程任务则通过在真实软件工程任务上基于执行结果的反馈来驱动。
虽然强化学习训练只针对有限的可验证任务,但获得的能力提升可以迁移到相关领域,比如通用工具使用能力。最后,他们通过专家蒸馏将这些专门技能整合起来,使 GLM-4.5 在各项任务上都具备全面的能力。
更多技术细节,请查看 GLM-4.5 技术报告原文。
效果怎么样?
智谱在 12 个基准上评估了 GLM-4.5 在 ARC(智能体、推理和代码)任务上的表现,具体包括:MMLU-Pro、AIME 24、MATH-500、SciCode、GPQA、HLE、LCB(2407-2501)、SWE-Bench Verified、Terminal-Bench、TAU-Bench、BFCL V3、BrowseComp。
智能体任务
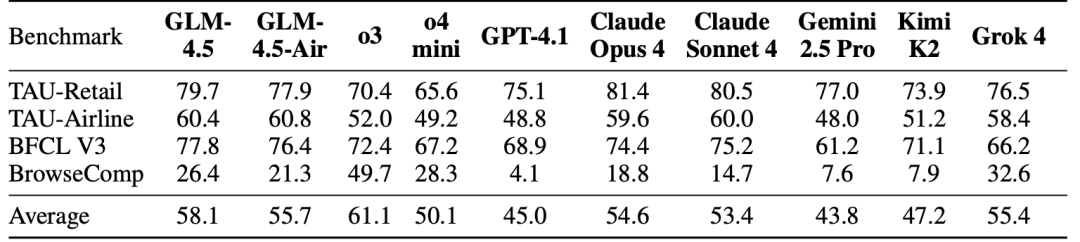
研究团队在 TAU-bench 和 BFCL-v3(Berkeley Function Calling Leaderboard v3)上测量了其工具调用能力,在 BrowseComp 上测量了其作为网页浏览智能体的能力。
在 TAU-bench 上,GLM-4.5 的表现优于 Gemini 2.5 Pro,并且接近 Claude Sonnet 4;在 BFCL V3 上,GLM-4.5 在所有基线模型中取得了最高的总体得分;在 BrowseComp 上,OpenAI o3 的表现明显优于其他模型,而 GLM-4.5 的表现接近 o4-mini,并显著优于 Claude Opus 4。
推理
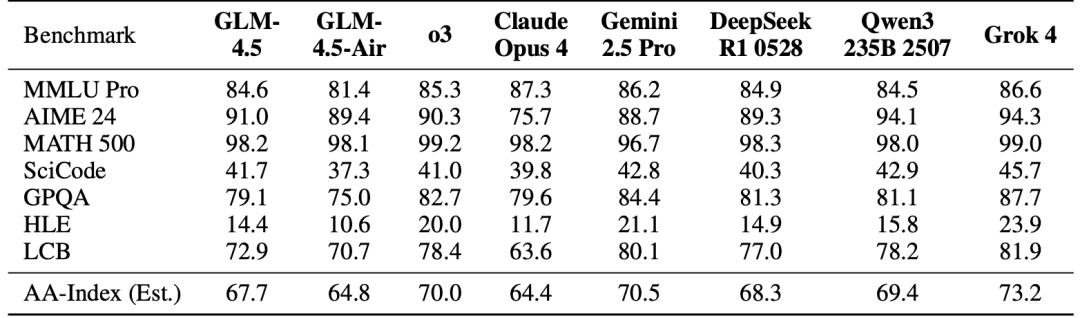
研究团队在七个基准上评估了 GLM-4.5 的推理能力,这些基准包括 MMLU-Pro、AIME 24、MATH 500、SciCode、GPQA、Humanity’s Last Exam(HLE)以及 LiveCodeBench(LCB)。
对于 AIME 和 GPQA 基准,他们分别展示了 32 次和 8 次采样的平均准确率(Avg@32、Avg@8),以减轻结果的随机性波动。答案验证由一个 LLM 自动完成。对于 HLE 基准,仅评测了基于文本的问题,正确性由 GPT-4o 判定。他们还使用 Artificial Analysis 提出的智能指数(intelligence index),计算了上述七个基准的平均推理性能。
结果显示,GLM-4.5 在 AIME 24 和 SciCode 基准上超过了 OpenAI o3。在整体平均表现上,GLM-4.5 优于 Claude Opus 4,并接近 DeepSeek-R1-0528。
代码
为了衡量 GLM-4.5 解决真实世界代码任务的能力,研究团队在两个具有挑战性的基准 SWE-bench Verified 和 Terminal-Bench 上进行了评测。
在 SWE-bench Verified 上,GLM-4.5 的表现优于 GPT-4.1 和 Gemini-2.5-Pro。在 Terminal-Bench 上,GLM-4.5 超过了 Claude Sonnet 4。

整体而言,在代码任务上,GLM-4.5 算得上是 Claude Sonnet 4 最有力的竞争对手。
除此之外,研究团队还对 GLM-4.5 的通用能力、安全、在真实世界的实际表现(包括通用聊天、Coding Agent、逻辑推理和翻译)等方面进行了评估。详情请查看 GLM-4.5 技术报告原文。
写在最后
随着这份技术报告的发布,GLM-4.5 的「幕后故事」终于完整呈现。从架构设计到训练方法,再到为其量身打造的 RL 框架 slime,智谱不仅交出了性能成绩单,也公开了实现路径。
对关注国产开源大模型的人来说,这不仅是一份报告,更是一把洞察未来研发方向的钥匙。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











