





本文第一作者操雨康,南洋理工大学MMLab博士后,研究方向是3D/4D重建与生成,人体动作/视频生成,以及图像生成与编辑。
本文共同第一作者司晨阳,南京大学助理教授,研究方向是图像/视频生成,以及生成模型的优化和加速。
在图像处理领域,「图像 morphing」(图像变形)是一项常见又充满创意的任务 —— 它可以让两张风格迥异的图片平滑过渡、自然融合,从而生成令人惊艳的中间图像。你可能在动画、电影特效或照片编辑中见过它的身影。
过去,这项技术往往依赖于复杂的图像对齐算法和颜色插值规则,难以应对复杂纹理和多样语义的图像变化。近年来,虽然 GAN、VAE 等深度学习方法取得了显著进步,但它们仍然面临训练成本高、数据依赖强、反演不稳定等问题 —— 尤其在真实世界图像中表现并不稳定。
为了实现高质量的图像 morphing,研究者们先后尝试了从图像 warping 到颜色插值,从 GAN 到 VAE,甚至使用了 Stable Diffusion 和 CLIP 等大模型。然而,即使在最先进的方案中,训练成本高、适应性差依旧是难以回避的难题。
那么,是否可能完全抛开训练?不再依赖预训练模型或额外标注?只用两张图像,就能高效、自然地完成 morphing?为了解决这一挑战,来自南洋理工大学 S-Lab、南京大学以及香港中文大学的研究团队提出了一种全新的方法 ——FreeMorph。该方法不仅实现了无需训练、一步到位的图像 morphing 效果,还能在拥有不同语义与布局的图像之间,生成流畅自然的过渡过程,为 training-free 图像 morphing 打开了全新的可能性。

想深入了解 FreeMorph 的技术细节?我们已经为你准备好了完整的论文、项目主页和代码仓库!

论文地址:https://arxiv.org/abs/2507.01953
项目地址:https://yukangcao.github.io/FreeMorph/
GitHub:https://github.com/yukangcao/FreeMorph
引言
近年来,随着大规模文本 - 图像数据集的普及,视觉 - 语言模型(如 Chameleon)、扩散模型(如 Stable Diffusion)以及 transformer 架构(如 PixArt-α, FLUX)在从文本提示生成高质量图像方面展现出了惊人的能力。这些技术进步也为生成式图像变形(image morphing)方法的革新奠定了基础。Wang & Golland [1] 利用基于 CLIP 的文本嵌入的局部线性特性,通过潜在图像特征的插值来实现平滑过渡。在此基础上,IMPUS [2] 引入了一个多阶段训练框架,包括文本嵌入的优化与 LoRA 模块的训练,以更好地捕捉语义。尽管该方法在视觉效果上更为出色,但每个案例需约 30 分钟的训练时间。DiffMorpher [3] 则通过插值 latent noise,并引入自适应实例归一化(AdaIN)以提升性能。然而,这些方法在处理语义多样、布局复杂的图像时仍显力不从心,限制了其实用性。
针对这些问题,我们的目标是实现无需调参和训练的图像变形。但是,这一目标也带来了两个关键挑战:
1) 图像变形过程中的特征丢失:通常来讲,面对这一问题,大家的第一反应会是把输入图像先转化为预训练扩散模型的潜在特征,然后再通过球面插值来实现图像变形。然而,这一方法看似直接,但 diffusion 扩散模型的多步去噪的非线性过程会导致生成的中间变形图片不连续。同时,diffusion 扩散模型自身的预训练特征也容易造成身份信息丢失;
2) 难以实现连贯过渡:diffusion 扩散模型本身并不具备明确的 “变化趋势”,这使得实现平滑、连贯的变形序列仍需额外机制支持。
为了解决这两个问题,FreeMorph 通过改善 diffusion 扩散模型中的注意力 attention 机制,以实现无需训练的图像变形方法:
1) 引导感知的球面插值:我们首先通过修改预训练扩散模型的自注意力模块 self-attention,融入输入图像的显式引导来增强模型。这是通过球面插值实现的,它产生中间特征并用于两个关键方面:首先,我们进行球面特征聚合,以融合自注意力模块的 Key 和 Value 特征,确保整个生成图像序列的过渡一致性。其次,为解决身份信息丢失问题,我们引入了先验引导的自注意力机制,该机制融入输入图像的显式引导,以保留其独特身份特征。
2) 面向步骤的变化趋势:为实现丝滑的过渡,我们提出了一种新颖的步骤导向的变化趋势方法。该方法融合了分别源自两个输入图像的两个自注意力模块,实现了一种受控且一致的过渡,同时尊重两个输入。为进一步提升生成图像序列的质量,我们设计了一种改进的反向去噪和正向扩散过程,将这些创新组件无缝集成到原始的 DDIM 框架中。
为全面评估 FreeMorph 并与现有方法进行基准测试,我们专门收集了一个新的评估数据集。该数据集包含四组不同类别的图像对,这些类别根据图像的语义相似性和布局相似性进行划分。
FreeMorph: 无需训练的图像变形框架

给定两张输入图像,我们首先提出两个模块:(1) 引导感知的球面插值和(2) 步骤导向的变化趋势,以增强定向性(保持身份特征的能力)和一致性(平滑过渡)。此外,我们注意到,在去噪步骤中简单应用这两个模块中的任何一个,效果都不够理想。因此,我们针对正向扩散和反向去噪过程开发了一种改进的方法,如上述算法所示。
引导感知的球面插值
现有的图像渐变方法 [25, 47, 49] 通常需要为每张输入图像训练低秩适应(LoRA)模块,以增强语义理解并实现平滑过渡。然而,这种方法通常效率低下且耗时,并且难以处理语义或布局不同的图像。
本文中,我们提出了一种基于预训练 Stable Diffusion 模型的免调参图像渐变方法。利用 DDIM(如公式 2 所示)进行图像反转和插值的能力,人们可能会考虑将输入图像


,并应用球面插值,这看起来像是一个简单直接的解决方案:
转换为潜在特征

其中


。在实验中,我们设置 J=5。
是中间图像的索引,
然而,直接将这些插值后的潜在特征
反转为图像,常常会导致过渡不一致 和身份信息丢失(见下图)。这个问题的根源在于:
1. 多步去噪过程高度非线性,导致生成的图像序列不连续;
2. 缺乏显式引导来控制去噪过程,使得模型继承了预训练扩散模型本身的偏见。

球面特征融合(Spherical feature aggregation):从先前的图像编辑技术中汲取见解,我们观察到:使用特征
的特征替换 Key 和 Value 特征(K 和 V),可以显著提升图像过渡的平滑度和特征信息保持度,尽管可能仍存在一些瑕疵(见上图)。
作为初始化,并在注意力机制中用来自右侧图像
受此发现的启发,并认识到 Query 特征(Q)在很大程度上反映了图像的整体布局,我们提出首先融合来自左右图像(

)的特征,为多步去噪过程提供显式引导。
具体操作如下:
在去噪步骤 t 中:
1. 我们将输入图像



,以获取它们的 Key和 Value特征(
输入预训练的
对应的潜在特征
2. 接着,我们替换掉当前中间状态


得到的原始 K 和 V 特征
输入
3. 我们计算左右图像 K 和 V 特征的平均值,并据此修改注意力机制:

其中,

得到的。
输入预训练
是通过将
先验驱动的自注意力机制(Prior-driven Self-attention Mechanism):虽然我们的球面特征融合技术显著改善了图像渐变中的身份信息保持度,但我们发现,在前向扩散和反向去噪阶段统一使用这种方法,会导致生成的图像序列变化极小,无法准确代表输入图像。这个结果是预料之中的,因为潜在噪声会对反向去噪过程产生重大影响(如下图所示)。因此,应用上述公式中描述的特征融合会引入模糊性 —— 来自输入图像的一致且强大的约束,使得每个中间潜在噪声 i 都显得非常相似,从而限制了过渡的有效性。

为解决这一问题,我们进一步提出了一种先验驱动的自注意力机制。该机制优先考虑来自球面插值的潜在特征,以确保潜在噪声空间内的平滑过渡;同时,在后续阶段强调输入图像以维持身份信息。具体策略为:
在反向去噪阶段:我们继续使用公式 5 描述的方法(融合左右图像特征)。
在前向扩散步骤:我们采用一种不同的注意力机制,通过修改自注意力模块来实现:

即:使用所有 J 个中间步骤 k 对应的 Key 和 Value 特征 (

) 的平均来计算注意力。
步骤导向的变化趋势
在获得了能够体现方向性并准确反映输入图像身份的图像序列后,下一个挑战是如何实现从左图像

变化的变化趋势。
一致且渐进的过渡。这个问题源于缺乏一个捕捉从
到右图像
为此,我们提出了一种步骤导向的变化趋势,它逐渐改变输入图像(

)在生成过程中的影响力:

其中

代表图片总数(包括生成的 J 张图像和输入的 2 张图像)。
整体前向扩散和反向去噪过程:
高频高斯噪声注入(High-frequency gaussian noise injection):如前所述,FreeMorph 在前向扩散和反向去噪阶段都融合了左右图像的特征。然而,我们观察到,这有时会给生成过程施加过于严格的约束。为缓解此问题并允许更大的灵活性,我们提出在前向扩散步骤后,向潜在向量 z 的高频域注入高斯噪声:

其中,


分别表示快速傅里叶逆变换和快速傅里叶变换。
表示随机采样的噪声向量,m是一个与 z 大小相同的二值高通滤波器掩码。
整体流程(Overall process):为提升图像渐变效果,我们发现在所有去噪步骤中统一应用引导感知球面插值或步骤导向的变化趋势会导致次优结果。
为此,我们为前向扩散和反向去噪过程开发了一种精细化方案:
前向扩散 :
前
步:使用标准自注意力机制。
从
到
步:应用先验驱动的自注意力机制(即平均所有中间状态特征)。
剩余步骤:实施步骤导向的变化趋势(动态混合左右图影响力)。
反向去噪 :
前
步:使用步骤导向的变化趋势。
从
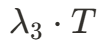
步:应用特征融合方法(即双图特征平均融合)。
到
最终步骤:切换回原始自注意力机制 (追求最高保真度)。
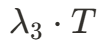
这里,

是超参数,T=50 是总步数。
实验
实验结果:在下图中,我们展示了 FreeMorph 生成的效果,这些结果充分证明了其生成高质量平滑过渡的能力。FreeMorph 在多样化场景中表现卓越:既能处理不同语义与布局的图像,也能驾驭具有相似特征的画面。同时,该方法还能有效捕捉细微变化 —— 无论是不同颜色的蛋糕,还是人物表情的微妙差异,均能精准呈现。

与其他图像变形方法的对比:下图中,我们提供了与现有图像变形方法的定性对比。有效的图像变形结果应当呈现从源图像(左)到目标图像(右)的渐进式过渡,同时保持原始身份特征。基于此标准可得出以下观察:
1. 处理语义与布局差异较大的图像时,IMPUS [2] 存在身份特征丢失及过渡不平滑问题。如下图第二案例所示:(i) 第三张生成图像偏离原始身份特征;(ii) 第三与第四生成图像间出现突变;
2. 尽管 Diffmorpher [3] 比 IMPUS 实现了更平滑的过渡,但其结果常存在模糊且整体质量较低(见下图第一个案例);
3. 基本方法 "Slerp"(仅采用球面插值与 DDIM 过程)存在三大缺陷:(i) 因缺乏显式引导而难以准确解析输入图像,(ii) 图像质量欠佳,(iii) 过渡突变。相比之下,本方法始终展现优越性能,其平滑过渡特性与高清画质优势显著。

总结
本文提出 FreeMorph,一种无需调参的新型流程,可在 30 秒内为两张输入图像生成高质量平滑过渡。具体而言,本方法创新性地通过修改自注意力模块引入显式图像引导,其核心技术包含两大创新组件:球面特征聚合机制与先验驱动自注意力机制。此外,我们提出步骤导向的定向变分趋势,确保过渡方向与输入图像严格一致。为将上述模块融入原始 DDIM 框架,还专门设计了改进型前向扩散与反向去噪流程。大量实验表明,FreeMorph 在多样化场景中均能生成高保真结果,以明显优势超越现有图像变形技术。
局限性和失败案例:尽管我们的方法达到了当前的最先进水平,但仍存在一些局限性。我们在下图中展示了若干失败案例,具体包括:
1)当处理语义或布局差异较大的图像时,虽然模型仍能生成一定程度上合理的结果,但过渡过程可能不够平滑,存在突变现象;
2)由于我们的方法基于 Stable Diffusion,其固有的偏差也会被继承,导致在处理涉及人体四肢等结构时,图像过渡的准确性受到影响。
 参考文献
参考文献[1] Interpolating between images with diffusion models. ICML workshop 2023.
[2] IMPUS: Image morphing with perceptually-uniform sampling using diffusion models. ICLR 2023.
[3] Diffmorpher: Unleashing the capability of diffusion models for image morphing. CVPR 2024



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











