




跟大模型说:要多想。
今年 1 月,DeepSeek R1 引爆了全球科技界,它创新的方法,大幅简化的算力需求撼动了英伟达万亿市值,更引发了全行业的反思。在通往 AGI(通用人工智能)的路上,我们现在不必一味扩大算力规模,更高效的新方法带来了更多的创新可能。
最近一段时间,全世界的科技公司、研究团队都在尝试复现 DeepSeek,但如果这个时候有人说「我还能大幅改进 AI 的推理效率」,你会怎么想?

s1 论文作者,斯坦福大学在读博士 Niklas Muennighoff 表示,DeepSeek r1 令人兴奋,但其缺少 OpenAI 的测试时间扩展图并且需要大量数据。我们推出的 s1 仅使用 1K 样本和简单的测试时间干预即可重现 o1 的预览扩展和性能。
这个新方法叫 s1。本周,斯坦福大学、华盛顿大学等研究机构尝试了最简化实现测试时间扩展(test-time scaling)的方法,仅让模型训练 1000 个问题就获得了超越 o1 的强推理性能。
测试时间扩展是一种有前途的语言建模新方法,它使用额外的测试时间计算来提高模型性能。此前,OpenAI 的 o1 模型展示了这种能力,但并未公开分享其方法。很多工作都在尝试复现 o1,这些尝试包含蒙特卡洛树搜索、多智能体等等。今年 1 月开源的 DeepSeek R1 成功实现了 o1 级别的性能,它是在数百万个样本上通过多训练阶段强化学习实现的。
在 s1 的新工作中,研究人员寻求最简单的方法来实现测试时间扩展。它们构建了一个小型数据集 s1K,其中包含 1000 个问题,并根据三个标准(难度、多样性和质量)与推理轨迹进行配对。
在此基础上,研究人员开发了「预算强制」来控制测试时间计算,方法是强制终止模型的思考过程,或者在模型试图结束时多次将「等待」附加到模型的生成中以延长思考。这有可能会导致模型仔细检查其答案,修复其不正确的推理步骤。
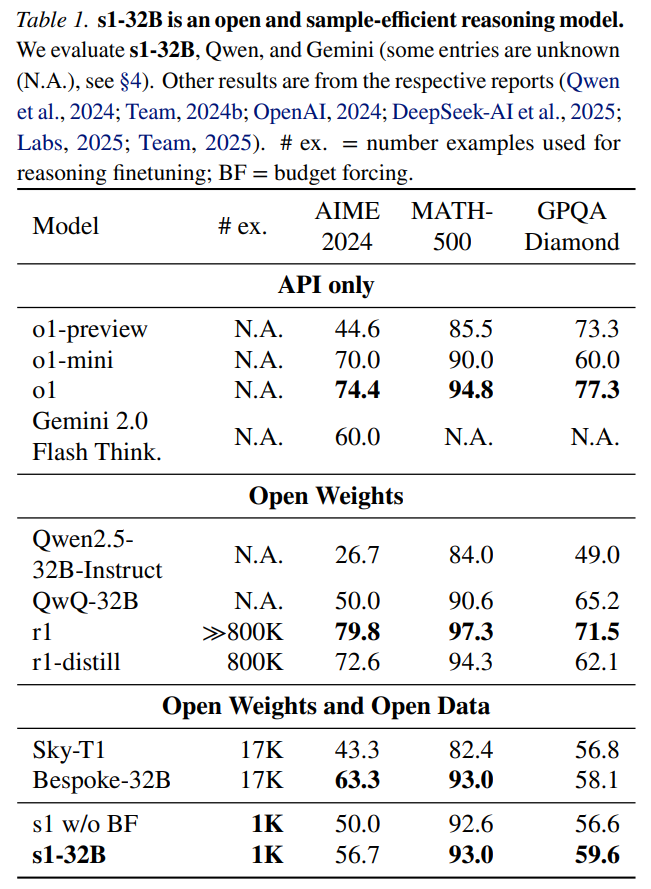
在 s1K 上对 Qwen2.5-32B-Instruct 语言模型进行监督微调(16 块 H100 GPU,26 分钟)并为其设定预算强制后,新模型 s1-32B 在竞赛数学问题上的表现比 o1-preview 高出 27%(MATH 和 AIME24)。

论文:《s1: Simple test-time scaling》
论文链接:https://arxiv.org/abs/2501.19393
项目链接:https://github.com/simplescaling/s1
测试时间扩展
本文将测试时间扩展方法分为两类:
序列扩展,即后续计算依赖于先前的计算结果;
并行扩展,即计算独立运行。
本文专注于序列扩展,因为直观上其具有更好的扩展性,因为后续计算可以基于中间结果进行,从而实现更深层次的推理和迭代优化。
此外,本文还提出了新的序列扩展方法以及对其进行基准测试的方式。
预算强制(Budget forcing)。本文提出了一种简单的解码时间(decoding-time )干预方法,通过在测试时强制设定最大或最小思考 token 数量来实现。图 3 为该方法的一个示例展示,说明了这种简单的方法可以引导模型得出更好的答案。

具体来说,本文通过简单地追加思考结束(end-of-thinking)token 分隔符和「Final Answer:」来强制设定最大 token 数量,从而提前退出思考阶段,使模型提供其当前的最佳答案。为了强制设定最小 token 数量,本文抑制思考结束 token 分隔符的生成,并选择性地在模型的当前推理轨迹后追加字符串「Wait」,以鼓励模型反思其当前生成的内容。
基线。本文用以下方法对预算强制进行基准测试:
(I)条件长度控制方法,该方法依赖于在提示中告诉模型它应该生成多长时间。本文按粒度将它们分组为(a)token 条件控制,在提示中指定思考 token 的上限;(b)步骤条件控制,指定思考步骤的上限;(c)类条件控制,编写两个通用提示,告诉模型思考一小段时间或很长一段时间。
(II)拒绝采样,即采样直到生成符合预定的计算预算。
实验
在训练阶段。本文使用 s1K 数据集对 Qwen2.5-32B-Instruct 进行监督微调,以获得本文的模型 s1-32B。微调是在 16 台 NVIDIA H100 GPU 上使用 PyTorch FSDP 进行的,耗时 26 分钟。
评估。本文采用了三个推理基准进行评估。
AIME24 包含 30 个问题,这些问题来自 2024 年 1 月 31 日至 2 月 1 日举行的美国 AIME 数学竞赛。AIME 用来测试模型在算术、代数、计数、几何、数论、概率等领域的能力;
MATH500 是一个包含不同难度竞赛数学问题的基准;
GPQA Diamond 包含 198 个来自生物学、化学和物理学的博士级科学问题。
其他模型。本文将 s1-32B 与以下模型进行基准测试对比:OpenAI o1 闭源系列模型;DeepSeek r1 开源模型;Qwen 的 QwQ-32B-preview 等模型。
值得一提的是,s1-32B 是完全开源的,包括权重、推理数据和代码。
性能
测试时间扩展。图 1 展示了 s1-32B 在使用预算强制技术后,随着测试时间计算资源的增加,性能的变化情况。
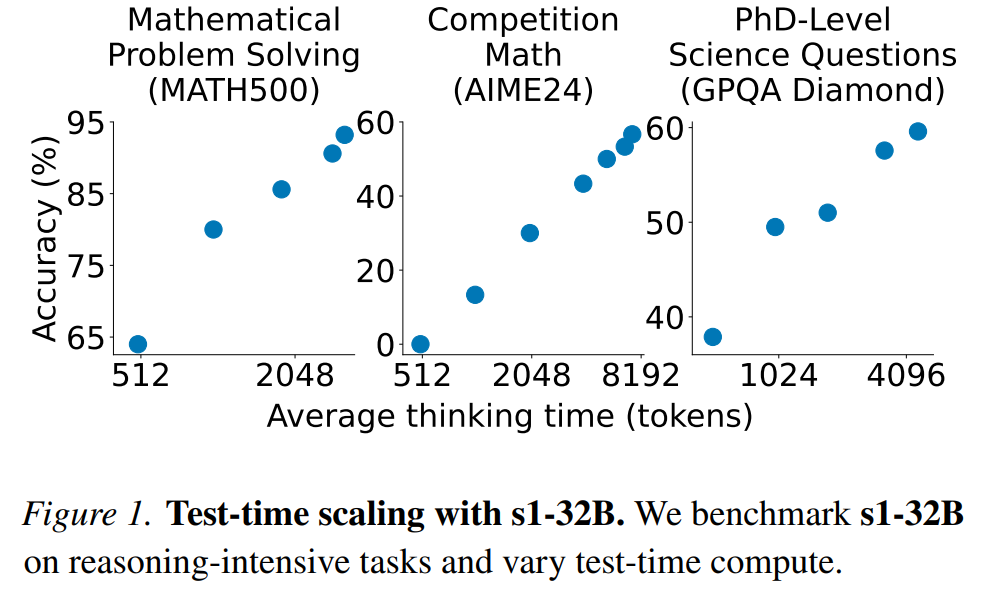
图 4(左)扩展了图 1(中)的图表,结果显示虽然本文可以通过预算强制技术和更多的测试时计算资源提升 AIME24 的性能,但最终在六倍计算量时趋于平缓。可以得出过于频繁地抑制思考结束 token 分隔符可能会导致模型陷入循环重复,而不是持续推理。
图 4(右)展示了在对 Qwen2.5-32B-Instruct 进行 1,000 个样本的训练,从而生成 s1-32B,并为其配备简单的预算强制技术后,它进入了一种不同的扩展范式。通过多数投票在基础模型上扩展测试时间计算资源无法赶上 s1-32B 的性能,这验证了这一直觉,即序列扩展比并行扩展更有效。
 图 5 提供了 s1-32B 的生成示例。
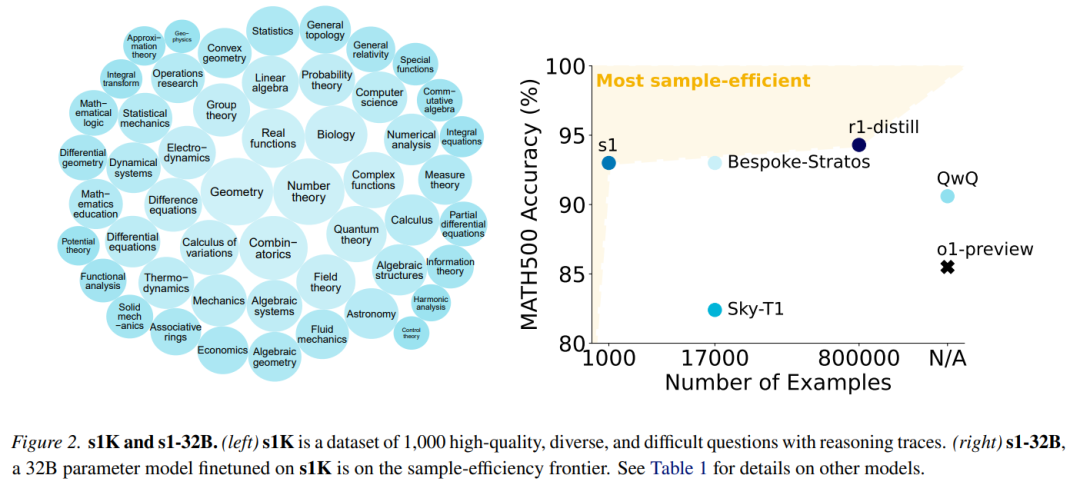
图 5 提供了 s1-32B 的生成示例。 样本效率。图 2(右)和表 1 将 s1-32B 与其他模型进行了比较。
样本效率。图 2(右)和表 1 将 s1-32B 与其他模型进行了比较。结果显示, s1-32B 是样本效率最高的开放数据推理模型。尽管只在额外的 1000 个样本上进行训练,但它的表现明显优于基础模型(Qwen2.5-32B-Instruct)。
r1-32B 在仅使用 SFT 的情况下表现出比 s1-32B 更好的性能,但前者是在 800 倍以上的推理样本上进行训练的。仅用 1000 个样本是否能达到这个性能还是一个悬而未决的问题。
s1-32B 在 AIME24 上几乎与 Gemini 2.0 Thinking 相匹配,因为 s1-32B 是从 Gemini 2.0 中蒸馏出来的,这表明本文的蒸馏程序可能是有效的。
最后,本文还进行了一系列消融实验,感兴趣的读者,可以查看原论文,了解更多内容。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











