




快科技1月16日消息,今日,阿里云通义开源全新的数学推理过程奖励模型Qwen2.5-Math-PRM,72B及7B尺寸模型性能均大幅超越同类开源过程奖励模型。
据了解,在识别推理错误步骤能力上,Qwen2.5-Math-PRM以7B的小尺寸超越了GPT-4o。同时,通义团队还开源了首个步骤级的评估标准 ProcessBench,此项评估标准填补了大模型推理过程错误评估的空白。

据了解,为更好衡量模型识别数学推理中错误步骤的能力,通义团队提出的全新评估标准ProcessBench。该基准由3400个数学问题测试案例组成,其中还包含奥赛难度的题目,每个案例都有人类专家标注的逐步推理过程,可综合全面评估模型识别错误步骤能力。这一评估标准也已开源。
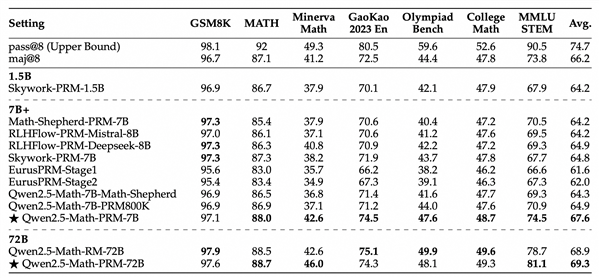
此外,在ProcessBench上对错误步骤的识别能力的评估中,72B及7B尺寸的Qwen2.5-Math-PRM均显示出显著的优势,7B版本的PRM模型不但超越同尺寸开源PRM模型,甚至超越了闭源GPT-4o-0806。这证明了过程奖励模型(PRM)能够显著提高推理的可靠性,为未来开发推理过程监督技术开辟了新的途径。
【本文结束】如需转载请务必注明出处:快科技
责任编辑:秋白



新浪科技公众号

“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











