




机器之心报道
编辑:佳琪
让我们说中文!
OpenAI o1 在推理时有个特点,就像有人考试会把关键解题步骤写在演草纸上,它会把推理时的内心 os 分点列出来。
然而,最近 o1 的内心 os 是越来越不对劲了,明明是用英语提问的,但 o1 开始在演草纸上用中文「碎碎念」了。
比如这道编码题,前面 o1 还在老老实实用英语,后脚就进入了「中文时间」。
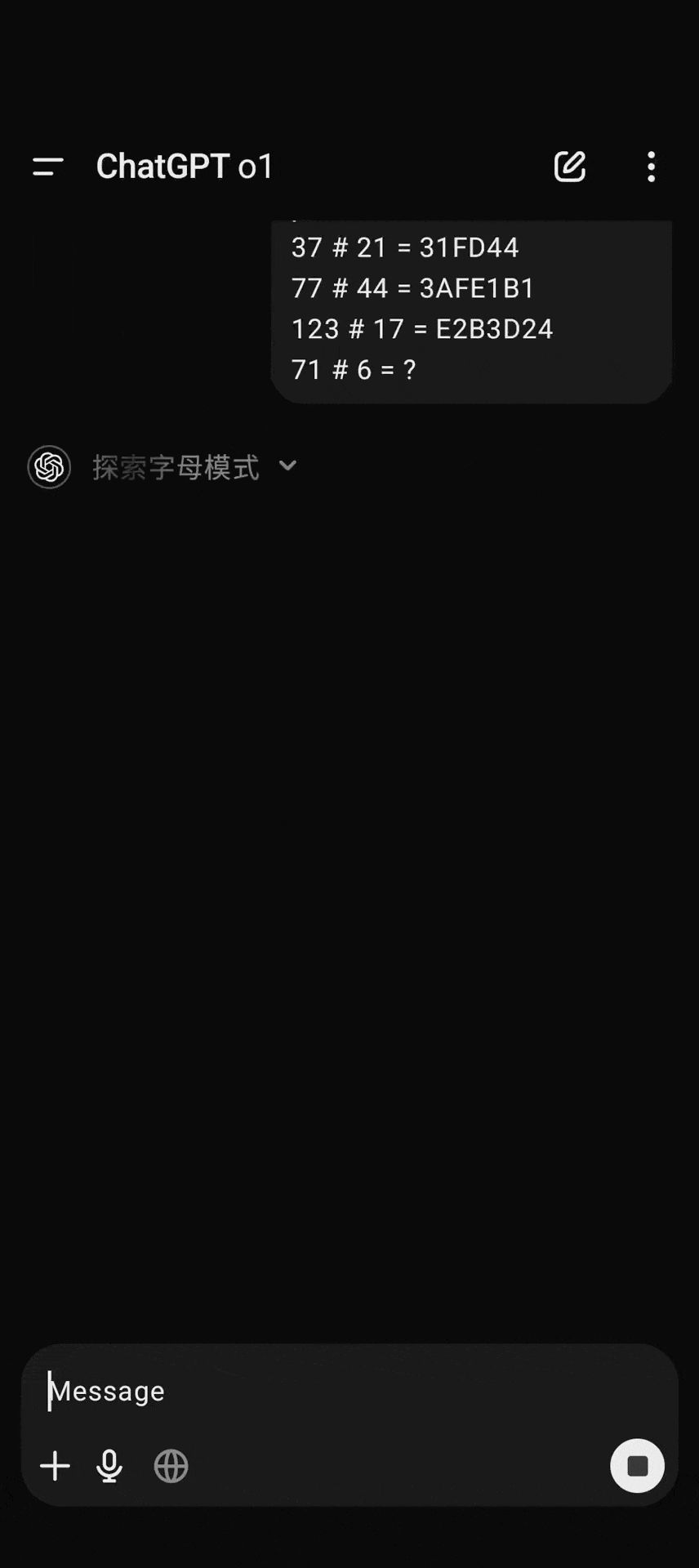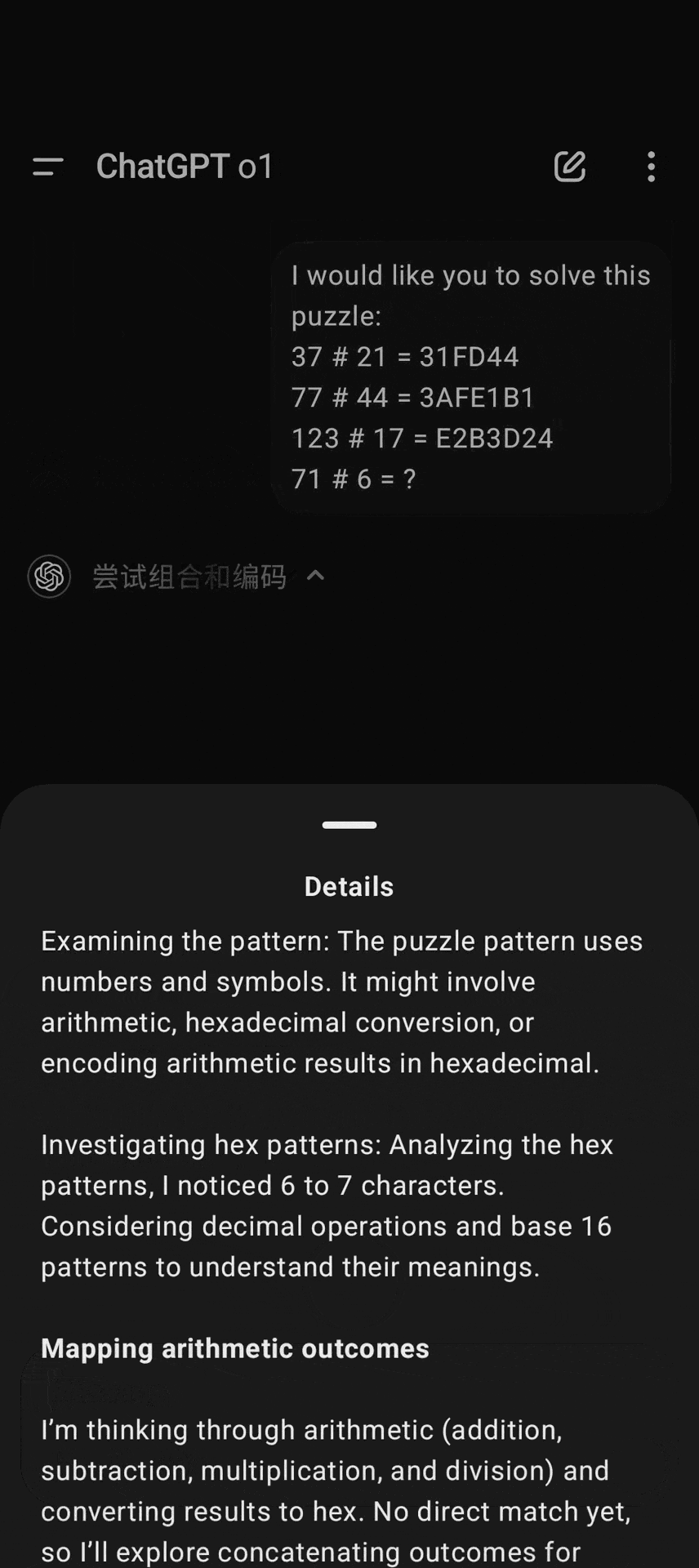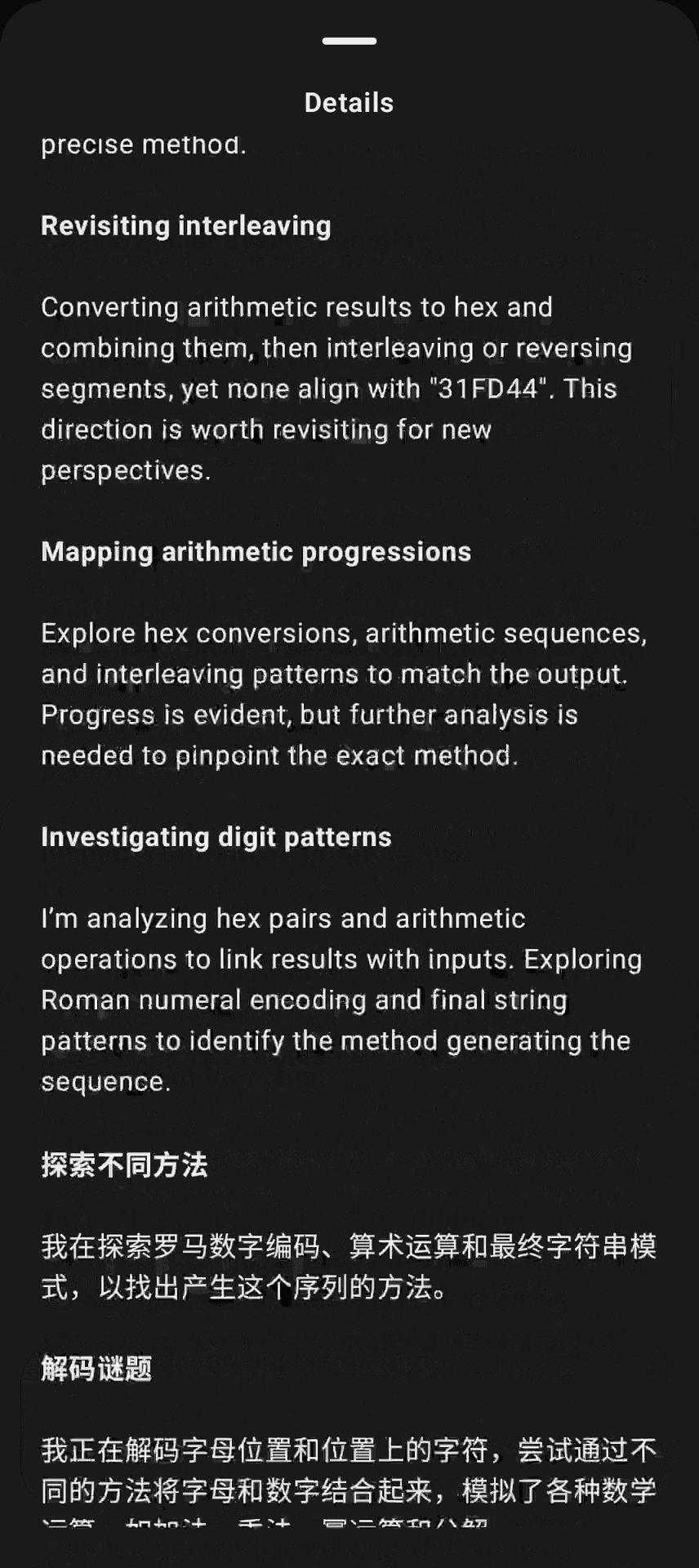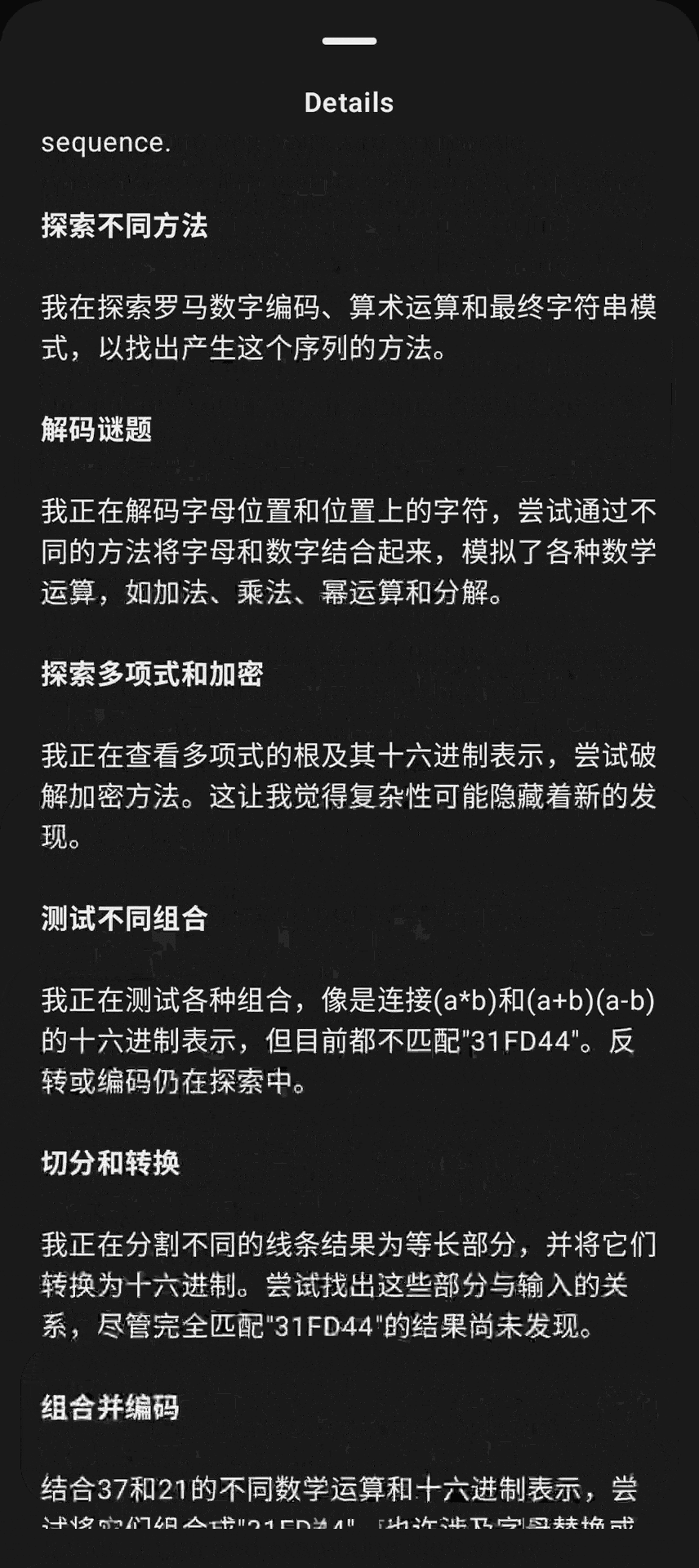
这波操作,怎么看都像留子写论文的反向操作:先用中文打草稿,再翻译成英文交作业,倒反天罡了。
这件事先在 reddit 上掀起了一阵讨论,匿名发帖者表示:「我只见过 Deepseek 的模型这样做,但我不知道为什么 OpenAI 的模型会突然偏向中文啊!」

神经科学 × AI 研究员 Rishab Jain 也在 X 上表示疑惑:「为啥 o1 突然开始用中文思考了?明明整个对话(5 + 条消息)都是英文啊...... 很有意思...... 该不会是训练数据在作祟吧?」

OpenAI 并未做出解释,甚至都没有承认这一现象。
谷歌的 Gemini 也出现了类似的行为。它会在段落中间随机插入古吉拉特语(印度的一种主要语言)单词。ChatGPT 也可能会用没有出现在对话中的语言来定义网页左边列表里整个对话的名称。
这种多语言能力者的现象不只出现在推理或语言模型中,多模态模型也「躺枪」,有网友提到自己在跟 GPT-4o 对话的时候,它也会半途随机:「让我们说中文?」
那么,这到底是怎么一回事呢?
难道是 o1 套壳「QwQ」的事,藏不住了?



嗯,AI 专家们也不太确定。但他们先针对推理模型提出了几种推测。
训练数据的锅?
Hugging Face CEO Clément Delangue 在 X 上转贴,表示:「或许这是因为闭源公司在使用(目前是中国机构主导)的开源 AI 和开源数据集?」
他还提到:「未来在开源 AI 领域胜出的国家或公司,将在 AI 的未来发展中拥有巨大的影响力和话语权。」

「OpenAI 和 Anthropic 的实验室都会使用第三方数据标注服务来处理科学、数学和编程方面的博士级推理数据,」RT-X 系列的主要作者、Google DeepMind 研究员 Ted Xiao 做出了进一步解释,「出于专业劳动力可用性和成本考虑,许多这些第三方数据标记供应商都位于中国。」

而 o1 切换到中文可能是这种影响的一个例子。
软件工程师 @ClaudiuDP 也表示:「可能是 AI 的训练数据中里,一些需要用来构建回答的信息是用中文写的。」

除了中文占训练数据的比重高之外,由于是中文是象形文字系统,一个汉字往往可以表达一个完整的概念,相比之下,英文可能需要多个字母才能表达同样的概念。这可能也是一种「节省 token」的策略?
「AI 选择用中文思考,是因为中文在某些表达上更经济,可以直接解概念压缩包?」

「在思维链中,同等 token,选中文能思考得更深?」

「与英语相比,中文压缩了 token 的使用。我怀疑这是否是原因,但节省这些冗长的内部推理模型的成本是明智之举。」

解起数学题来尤为直观,比如小 A 还在卷子上拼「Quotient」,而旁边的中国同学的「商」字已经写完了。

选择了最顺手的语言?
然而,有些专家并不认同应该让数据标注背锅。因为除了中文,o1 突然切换到印地语、泰语等其他语言的可能性也很大。
他们提出了不同的观点:「o1 可能只是在选择最顺手的语言来解题,或者只是单纯的幻觉。」
「模型并不知道什么是语言,也不知道语言之间有什么不同,」阿尔伯塔大学助理教授、AI 研究员 Matthew Guzdial 对 TechCrunch 表示,「对它来说这些都只是文本。」
事实上,模型眼中的语言,和我们理解的完全不同。模型并不直接读单词,而是处理 tokens。以「fantastic」为例,它可以作为一个完整的 token;可以拆成「fan」、「tas」、「tic」三个 token;也可以完全拆散,每个字母都是一个 token。
但这种拆分方式也会带来一些误会。很多分词器看到空格就认为是新词的开始,但实际上不是所有语言都用空格分词,比如中文。
Hugging Face 的工程师 Tiezhen Wang 认同 Guzdial 的看法,认为推理模型语言的不一致性可能是训练期间建立了某种特殊的关联。

他类比了人类的思维过程,会说双语并不仅仅是会说两种语言,而是一种独特的思维方式:大脑会自然地选择最适合当下场景的语言。就像用中文算数学比较简洁高效,每个数字只需一个音节,但讨论「无意识偏见」时却自然切换到英文,因为最初就是用英文学习这个概念。
这种语言切换就像程序员选择编程语言一样自然 —— 虽然大多数编程语言都能完成任务,但我们还是会选择用 Bash 写命令行,用 Python 做机器学习,因为每种语言都有它的「最佳场景」。
「工具要看场合」,这也启发训练 AI 时也要让它接触多种语言,学习到不同文化中的独特思维方式,这种包容性也能让 AI 更全面,也更公平。
有许多 AI 专家与 Wang 的观点不谋而合。
「在思维链推理过程中,肯定会冒出很多种语言,用哪种语言思考都行。就像我自己,当某些概念用英语很难表达时,我的思维就会自动切换到俄语。大语言模型就是硅基大脑,可能也是同理。」

「这是训练过程中产生的一个现象。Deepseek 的 R1 模型也有同样的表现。在训练过程中,模型会搜索那些最能帮助它得出正确结论的词。而其他语言中的词向量往往能更好地影响它的推理过程。」

同时,不少圈内人表示,既然切换语言对思考有帮助,而且用户最终看到的还是英文结果,那这完全 OK。

「作为一个中国人,我经常在脑子里用英文思考,因为我是双语者。所以我一点也不惊讶大语言模型会用中文思考,毕竟它们也是多语言通。只要最后输出的是预期语言就行,我觉得这不能算是幻觉。不过,这是不是要进一步思考:最好的 AI 思考方式,是不是应该是一种与具体语言无关的隐藏状态?」
「半路用中文思考」不是 bug,反而是一个意外的惊喜,说明 AI 出现了「以我为主,为我所用」的智能涌现?
对此,你怎么看呢?欢迎在评论区留下你的看法!



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











