




好不容易找了把尺子,结果尺子会随机伸缩。
在机器学习和数据科学领域,余弦相似度长期以来一直是衡量高维对象之间语义相似度的首选指标。余弦相似度已广泛应用于从推荐系统到自然语言处理的各种应用中。它的流行源于人们相信它捕获了嵌入向量之间的方向对齐,提供了比简单点积更有意义的相似性度量。
然而,Netflix 和康奈尔大学的一项研究挑战了我们对这种流行方法的理解:余弦相似度可能导致任意且毫无意义的结果。

论文地址:https://arxiv.org/pdf/2403.05440v1
余弦相似度通过测量两个向量的夹角的余弦值来度量它们之间的相似性,机器学习研究常常通过将余弦相似性应用于学得的低维特征嵌入来量化高维对象之间的语义相似性。但在实践中,这可能比嵌入向量之间的非标准化点积效果更好,但有时也更糟糕。
图源:https://www.shaped.ai/blog/cosine-similarity-not-the-silver-bullet-we-thought-it-was
为了深入了解这一经验观察,Netflix 和康奈尔大学的研究团队研究了从正则化线性模型派生的嵌入,通过分析得出结论:对于某些线性模型来说,相似度甚至不是唯一的,而对于其他模型来说,它们是由正则化隐式控制的。
该研究讨论了线性模型之外的情况:学习深度模型时采用不同正则化的组合,当对结果嵌入进行余弦相似度计算时,会产生隐式和意想不到的效果,使结果变得不透明并且可能是任意的。基于这些见解,研究团队得出结论:不要盲目使用余弦相似度,并概述了替代方案。
最近,这篇论文在机器学习社区再度引起热议,一篇题为《Cosine Similarity: Not the Silver Bullet We Thought It Was(余弦相似度:不是我们想象的灵丹妙药)》的博客概述了研究内容。

博客地址:https://www.shaped.ai/blog/cosine-similarity-not-the-silver-bullet-we-thought-it-was
有网友表示:「问题没那么严重,相似度指标需要根据嵌入空间进行量身定制,需要测试不同的指标来建立定性评估。」

网友认为余弦相似度应该是一个足够好的方法。毕竟,「根据 OpenAI 关于嵌入的文档,他们还在代码片段中使用了余弦相似度。」

这个结论是怎么得出来的呢?让我们一起看看这篇论文的主要内容,一探究竟。
研究简介
研究团队发现了一个重要问题:在特定场景下,余弦相似度会随意产生结果,这使得该度量方法变得不可靠。
研究着重分析了线性矩阵模型。这类模型能够得到封闭形式的解与理论分析,在推荐系统等应用中被广泛用于学习离散实体的低维嵌入表示。
研究分析了 MF 模型的两个常用训练目标:
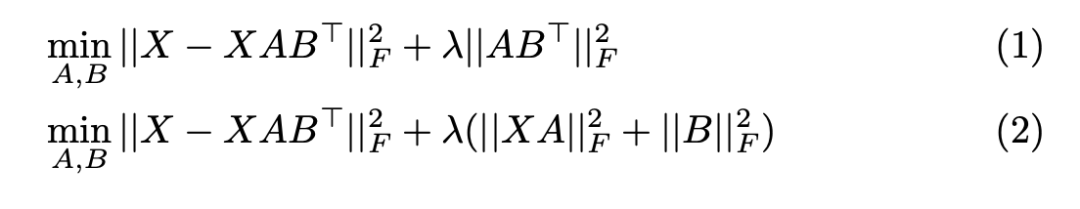
其中 X 是输入数据矩阵,A 和 B 是学习到的嵌入矩阵,λ 是正则化参数。
问题根源:正则化与自由度
研究人员发现,第一个优化目标(等同于使用去噪或 dropout 的学习方式)在学习到的嵌入中引入了一个关键的自由度。这种自由度允许对嵌入维度进行任意缩放,却不会影响模型的预测结果。
从数学角度来看,如果 Â 和 B̂ 是第一个目标的解,那么对于任意对角矩阵 D,ÂD 和 B̂D^(-1) 也是解。这种缩放会影响学习到的嵌入的归一化,从而影响它们之间的余弦相似度。

来自论文:《Is Cosine-Similarity of Embeddings Really About Similarity? 》
举两个随意产生结果的例子:
1. 在全秩 MF 模型中,通过适当选择 D,item-item 余弦相似度可以等于单位矩阵。这个奇怪的结果表明每个 item 只与自己相似,而与所有其他 item 完全不相似。
2. 通过选择不同的 D,user-user 余弦相似度可以简化为 ΩA・X・X^T・ΩA,其中 X 是原始数据矩阵。这意味着相似度仅基于原始数据,完全没有利用到学习的嵌入。
线性模型之外
除了线性模型,类似的问题在更复杂的场景中也存在:
1. 深度学习模型通常会同时使用多种不同的正则化技术,这可能会对最终嵌入的余弦相似度产生意想不到的影响。
2. 在通过点积优化来学习嵌入时,如果直接使用余弦相似度,可能会得到难以解释且没有实际意义的结果。
研究人员提出了几种解决这些问题的方法:
直接针对余弦相似度训练模型,可能需要借助层归一化等技术。
完全避免在嵌入空间中工作。相反,在应用余弦相似度之前,先将嵌入投影回原始空间。
在学习过程中或之前应用归一化或减少流行度偏差,而不是像余弦相似度那样仅在学习后进行归一化。
语义分析中余弦相似度的替代方案
在论文的基础上,博客作者 Amarpreet Kaur 归纳了一些可以替换余弦相似度的备选项:
欧几里得距离:虽然由于对向量大小敏感而在文本数据中不太流行,但在嵌入经过适当归一化时可以发挥作用。
点积:在某些应用中,嵌入向量之间的非归一化点积被发现优于余弦相似度,特别是在密集段落检索和问答任务中。
软余弦相似度:这种方法除了考虑向量表示外,还考虑了单个词之间的相似度,可能提供更细致的比较。
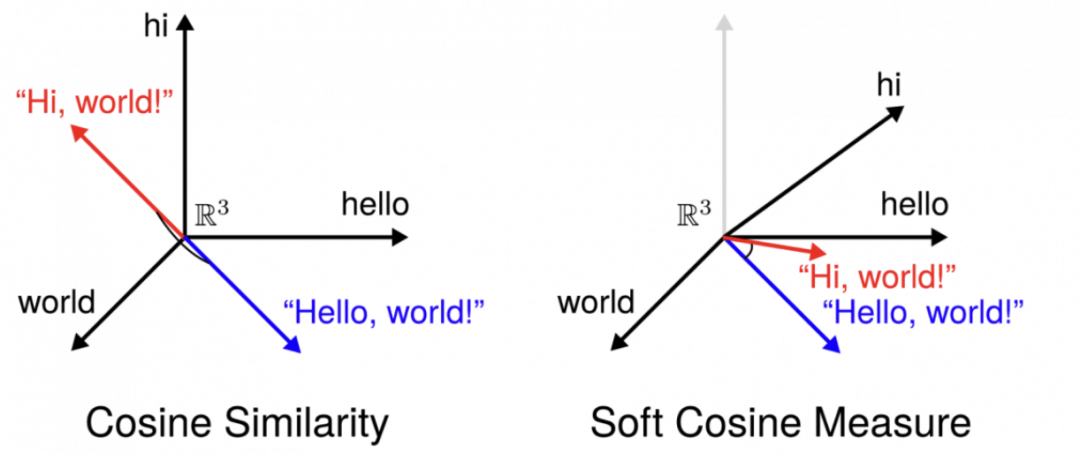
图源:https://www.machinelearningplus.com/nlp/cosine-similarity/
语义文本相似度(STS)预测:专门为语义相似度任务训练的微调模型 (如 STSScore) 有望提供更稳健和和更可解释的相似度度量。
归一化嵌入与余弦相似度:在使用余弦相似度之前,应用层归一化等归一化技术能有效提升相似度计算的准确性。
在选择替代方案时,必须考虑任务的具体要求、数据的性质以及所使用的模型架构。通常需要在特定领域的数据集上进行实证评估,以确定最适合特定应用的相似度。
我们经常用「余弦相似度」来计算用户或物品之间的相似程度。这就像是测量两个向量之间的夹角,夹角越小,相似度越高。论文中的实验结果也表明,余弦相似度给出的答案经常与实际情况不符。
在比较简单的线性模型上都已经如此随机,在更复杂的深度学习模型中,这个问题可能会更严重。因为深度学习模型通常使用更多复杂的数学技巧来优化结果,这些技巧会影响模型内部的数值大小,从而影响余弦相似度的计算。
这就像是把一个本来就不太准的测量工具放在一个更复杂的环境中使用,结果可能会更不可靠。因此,需要寻找更好的方法,比如使用其他相似度计算方式,或者研究正则化技术对语义的影响。这提醒大家:在开发 AI 系统时,要多思考、多测试,确保工具真的好用。
对于这项研究的结论,你怎么看?



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











