




除了提升数据效率之外,本文方法 MeCo 保证了计算开销与复杂性也几乎不会增加。
普林斯顿大学计算机科学系助理教授陈丹琦团队又有了新论文,这次将重点放在了「使用元数据来加速预训练」上来。
我们知道,语言模型通过在大量网络语料库上进行训练来实现卓越的通用能力。多样性训练数据凸显了一个根本性挑战:人们自然地根据数据源来调整他们的理解,与之不同,语言模型将所有内容作为等效样本来处理。
这种以相同方式处理异构源数据的做法会带来两个问题:一是忽略了有助于理解的重要上下文信号,二是在专门的下游任务中阻碍模型可靠地展示适当的行为,比如幽默或事实。
面对以上这些挑战,并为了提供每个文档来源的更多信息,陈丹琦团队在本文中提出通过在每个文档之前添加广泛可用的源 URL,从而在预训练期间使用文档相应的元数据进行调节。并且为了确保模型在推理过程中无论有无元数据都能高效地运行,在最后 10% 的训练中实施了冷却(cooldown)。他们将这种预训练方法称为 Metadata Conditioning then Cooldown(MeCo)。
先前的工作中已经有人使用元数据条件来引导模型生成并提高模型对恶意提示的稳健性,但研究者通过关键的两点确认了所提方法的通用实用性。首先,他们证明这一范式可以直接加速语言模型的预训练并提高下游任务性能。其次,MeCo 的冷却阶段确保模型在没有元数据的情况下可以执行推理,这点与以往的方法不同。
本文的主要贡献包括如下:
一、MeCo 大大加速了预训练过程。研究者证明,MeCo 使得 1.6B 的模型在少用 33%训练数据的情况下,实现与标准预训练模型相同的平均下游性能。MeCo 在模型规模(600M、1.6B、3B 和 8B)和数据源(C4、RefinedWeb 和 DCLM)表现出了一致的增益。
二、MeCo 开辟了一种引导模型的新方法。在推理过程中,在提示之前添加合适的真实或合成 URL 可以诱导期望的模型行为。举个例子,使用「factquizmaster.com」(并非真实 URL)可以增强常识知识任务的性能,比如零样本常识问题绝对性能可以提升 6%。相反,使用「wikipedia.org」(真实 URL)可以将有毒生成的可能性比标准无条件推理降低数倍。
三、MeCo 设计选择的消融实验表明,它能与不同类型的元数据兼容。使用散列 URL 和模型生成主题的消融实验表明,元数据的主要作用是按照来源对文档进行分组。因此,即使没有 URL,MeCo 也可以有效地合并不同类型的元数据,包括更细粒度的选项。
研究结果表明,MeCo 可以显著提高语言模型的数据效率,同时几乎不会增加预训练过程的计算开销和复杂性。此外,MeCo 提供了增强可控性,有望创建更可控的语言模型,并且它与更细粒度和创造性的元数据的普遍兼容性值得进一步探索。
总之,作为一种简单、灵活、有效的训练范式,MeCo 可以同时提高语言模型的实用性和可控性。

论文标题:Metadata Conditioning Accelerates Language Model Pre-training
论文地址:https://arxiv.org/pdf/2501.01956v1
代码地址:https://github.com/princeton-pli/MeCo
论文一作高天宇(Tianyu Gao)还在评论区与读者展开了互动,并回答了一个问题「MeCo 是否需要平衡过拟合和欠拟合」。他表示,本文的一个假设是 MeCo 进行隐式数据混合优化(DoReMi、ADO)并上采样欠拟合和更多有用域。
OpenAI 一位研究人员 Lucas Beyer 表示,他很久之前就对视觉语言模型(VLM)做过类似的研究,很有趣,但最终用处不大。
方法概览
本文方法包括以下两个训练阶段,如下图 1 所示。

使用元数据条件进行预训练(前 90%):模型在串接的元数据和文档上进行训练,并遵循以下模板「URL:en.wikipedia.org\n\n[document]」。使用其他类型的元数据时,URL替换为相应的元数据名称。研究者仅计算文档token的交叉熵损失,而忽略出自模板或元数据的token。他们在初步实验中发现:使用这些token训练会损害下游任务性能。
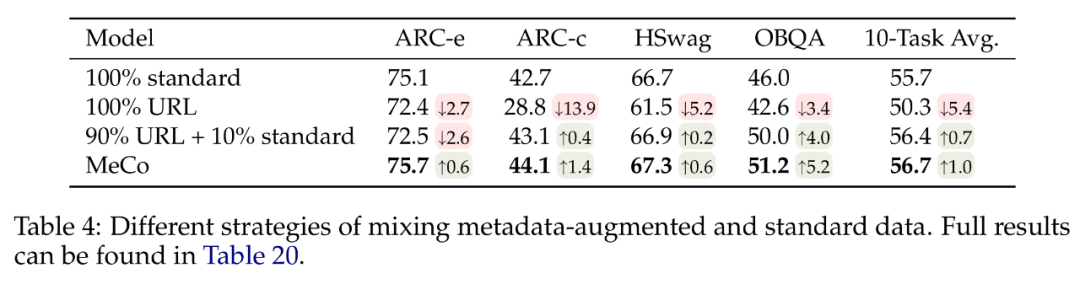
使用标准数据进行冷却(后 10%):对于仅使用元数据增强的数据进行训练的模型,在没有元数据的情况下性能会下降(具体可见下表 4)。为了确保通用性,研究者在冷却阶段,使用了没有任何元数据的标准预训练文档来训练模型,该阶段涵盖了预训练过程最后 10% 的步骤。
冷却阶段继承了来自元数据条件阶段的学习率计划和优化器状态,即它从上一个阶段的最后一个检查点初始化学习率、模型参数和优化器状态,并继续根据计划来调整学习率。
研究者还在所有实验中采用了以下两项技术,并且初步实验表明它们提高了基线预训练模型的性能:
禁用了跨文档注意力,此举既加快了训练速度(1.6B 模型的速度提升了 25%),又提高了下游任务的性能;
将多个文档打包成一个序列时,确保每个序列都从一个新文档开始,而不是从一个文档的中间开始,这可能会导致在将文档打包为一个固定长度时丢弃一些数据,但被证明有利于提高下游任务性能。
实验结果
研究者在所有实验中使用了 Llama 系列模型使用的 Transformer 架构和 Llama-3tokenizer,使用了四种规模的模型大小,分别是 600M、1.6B、3B 和 8B。他们对语言模型采用了标准优化设置,即 AdamW 优化器和余弦学习率计划。
少用 33% 数据,MeCo 性能与标准预训练方法相当
下表 1 显示了研究者在 DCLM 上的 160B token 上,对 1.6B 语言模型进行预训练的主要结果。他们首先观察到,在大多数任务中,MeCo 的性能显著优于标准预训练方法。MeCo 还超越了数据挑选基线。并且与数据挑选方法不同的是,MeCo 不会产生任何计算开销,它利用了预训练数据中随时可用的 URL 信息。
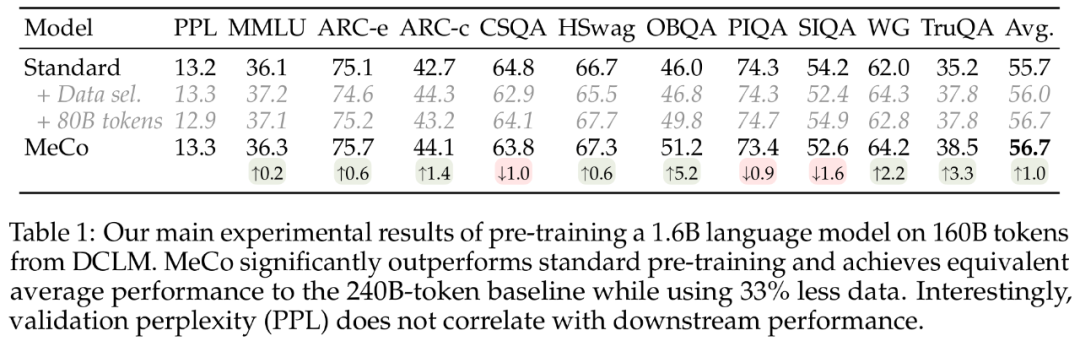
更重要的是,MeCo 实现了与标准预训练方法相当的性能,同时使用的数据和计算量减少了 33%,代表了数据效率的显著提高。
下表 1 为困惑度指标,表明了验证困惑度与下游性能无关。值得注意的是,当将 240B 基线模型与 160B MeCo 模型比较时,由于数据量较大,基线模型表现出的困惑度要低得多,但这两个模型实现了类似的平均性能。
研究者在下图 2 中展示了整个预训练过程中下游任务的性能变化。对于 MeCo,图中的每个检查点都包含使用 16B token(占总训练 token 的 10%)的冷却阶段。例如,80B 检查点包含了 64B token 的条件训练和 16B token 的冷却。他们观察到,MeCo 始终超越了基线模型,尤其是在训练后期。
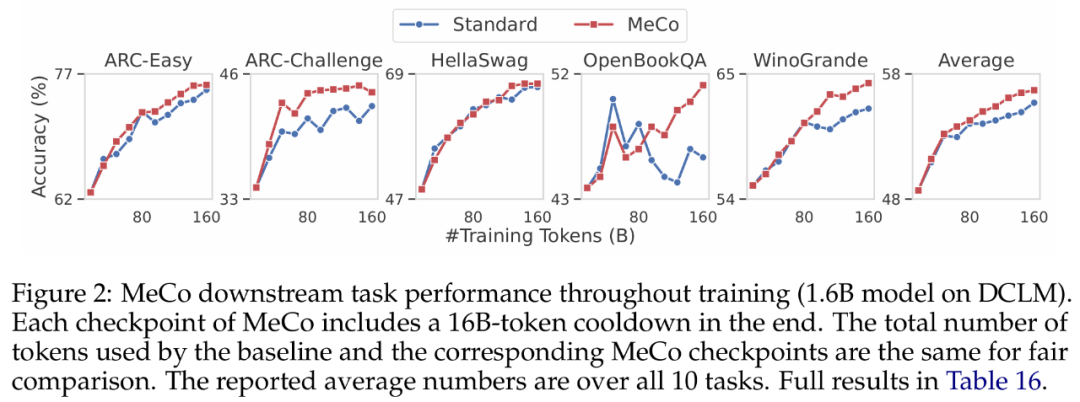
MeCo 在所有模型规模下均提升了性能
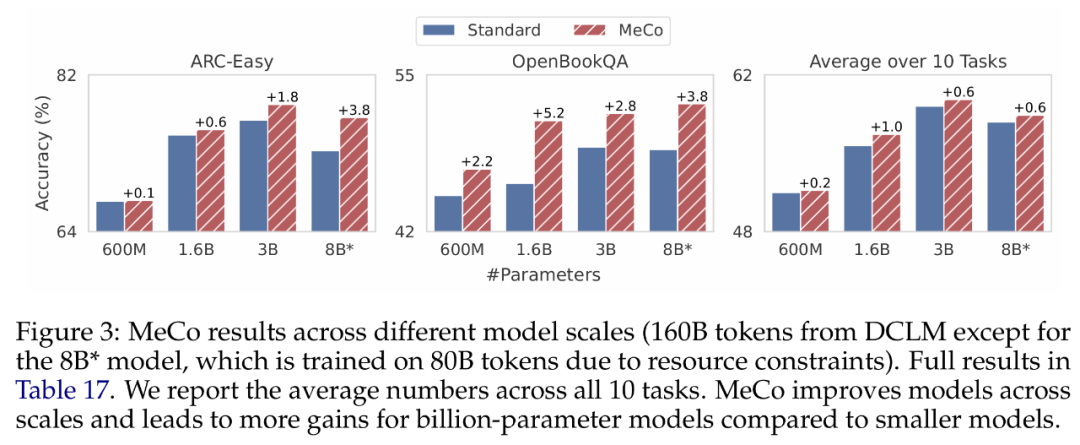
下图 3 显示了不同模型规模(600 M、1.6B、3B 和 8B)的结果。研究者使用相同的优化超参数和相同的数据量(DCLM 上的 160B)来训练所有模型,其中 8B 模型是个个例,它使用 80B token 进行训练,由于资源限制和训练不稳定而导致学习率较低。
研究者观察到,MeCo 在所有规模下均提升了模型性能。并且 MeCo 看起来可以为更大的模型带来更多的改进,十亿级参数的模型与 600M 相比显示出更显著的收益。不过需要注意,这是一个定性观察,与预训练损失相比,下游任务性能的扩展不太平稳。
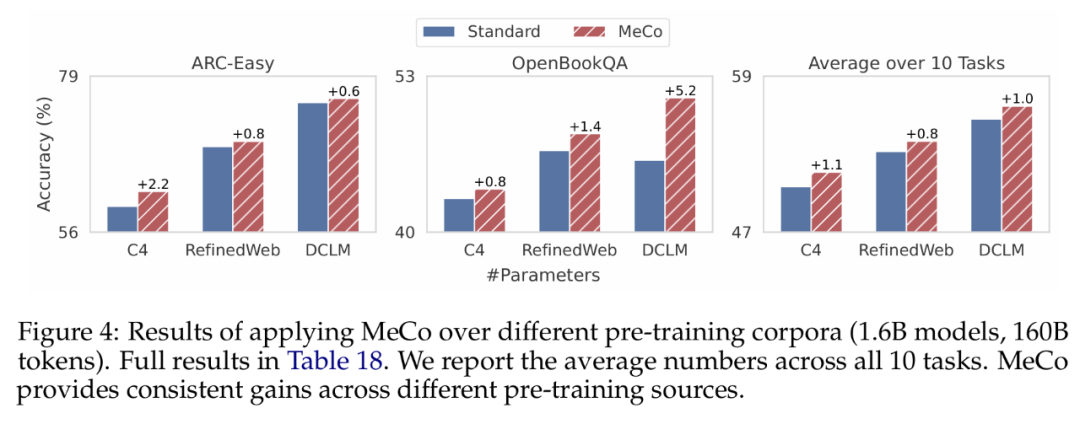
MeCo 提升了不同训练语料库的性能
研究者基于三个不同的数据源(C4、RefinedWeb 和 DCLM),在 160B token 上训练了 1.6B 模型,结果如下图 4 所示。如果将平均下游性能作为数据质量指标,三个数据源的排序为 DCLM > RefinedWeb > C4。他们观察到,MeCo 在不同数据源上实现了一致且显著的增益,平均准确率和单个任务均是如此。
更多技术细节请参阅原论文。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











