




真正有用的主力模型。
BERT 于 2018 年发布,这个时间点,如果按照 AI 的纪事年代来说,可以说是一千年以前的事了!虽然过去了这么多年,但至今仍被广泛使用:事实上,它目前是 HuggingFace 中心下载量第二大的模型,每月下载量超过 6800 万次。
好消息是,六年后的今天,我们终于有了替代品!
近日,新型 AI 研发实验室 Answer.AI、英伟达等发布了 ModernBERT。
ModernBERT 是一个新的模型系列,具有两个型号:基础版 139M 、较大版 395M。在速度和准确率方面都比 BERT 及其同类模型有了显著改进。该模型采用了近年来在大型语言模型 (LLM) 方面的数十项进展,包括对架构和训练过程的更新。

除了速度更快、准确度更高外,ModernBERT 还将上下文长度增加到 8k 个 token,而大多数编码器只有 512 个 token,并且是第一个在训练数据中包含大量代码的仅编码器专用模型。

原文地址:https://huggingface.co/blog/modernbert
论文地址:https://arxiv.org/pdf/2412.13663
项目主页:https://github.com/huggingface/blog/blob/main/modernbert.md
Answer.AI 联合创始人 Jeremy Howard 表示,ModernBERT 不炒作生成式 AI(GenAI),而是真正的主力模型,可用于检索、分类,是真正有用的工作。此外还更快、更准确、上下文更长、更有用。

仅解码器模型
近期,GPT、Llama 和 Claude 等模型迅速崛起,这些模型是仅解码器模型,也可以说是生成模型。它们的出现催生出令人惊叹的新型领域 GenAI,例如生成艺术和交互式聊天。本文所做的,本质上就是将这些进展移植回仅编码器模型。
为什么要这么做?因为许多实际应用都需要一个精简的模型!而且它不需要是一个生成模型。
更直白地说,仅解码器模型对于许多工作来说太大、太慢、太私密、太昂贵。想想最初的 GPT-1 是一个 1.17 亿参数的模型。相比之下,Llama 3.1 模型有 4050 亿个参数,对于大多数公司来说,这种方法过于复杂和昂贵,无法复制。
GenAI 的流行热潮掩盖了仅编码器模型的作用。这些模型在许多科学和商业应用中发挥了巨大作用。
仅编码器模型
仅编码器模型的输出是数值列表(嵌入向量),其将「答案」直接编码为压缩的数字形式。该向量是模型输入的压缩表示,这就是为什么仅编码器模型有时被称为表示模型。
虽然仅解码器模型(如 GPT)可以完成仅编码器模型(如 BERT)的工作,但它们受到一个关键约束:由于它们是生成模型,因此从数学上讲它们「不允许窥视」后面的 token。这与仅编码器模型形成对比,后者经过训练,每个 token 都可以向前和向后(双向)查看。它们就是为此而构建的,这使得它们在工作中非常高效。
基本上,像 OpenAI o1 这样的前沿模型就像法拉利 SF-23,这显然是工程学的胜利,旨在赢得比赛。但仅是更换轮胎就需要专门的维修站,而且你无法自己购买。相比之下,BERT 模型就像本田思域,这也是一项工程学的胜利,但更微妙的是,它被设计成价格实惠、省油、可靠且极其实用的车型。因而无处不在。
我们可以从不同的角度看待这个问题。
首先是基于编码器的系统:在 GPT 出现之前,社交媒体和 Netflix 等平台中都有内容推荐。这些系统不是建立在生成模型上,而是建立在表征模型(如仅编码器模型)上。所有这些系统仍然存在,并且仍在大规模运行。
接着是下载量:在 HuggingFace 上,RoBERTa 是基于 BERT 的领先模型之一,其下载量超过了 HuggingFace 上 10 个最受欢迎的 LLM 的总下载量。事实上,目前,仅编码器模型每月的下载量总计超过 10 亿次,几乎是仅解码器模型(每月下载量为 3.97 亿次)的三倍。
最后是推理成本:按推理计算,每年在纯编码器模型上执行的推理要比纯解码器模型或生成模型多很多倍。一个有趣的例子是 FineWeb-Edu,团队选择使用仅解码器模型 Llama-3-70b-Instruct 生成注释,并使用经过微调的基于 BERT 的模型执行大部分过滤。此过滤耗时 6,000 H100 小时,按照每小时 10 美元的定价,总计 60,000 美元。另一方面,即使使用成本最低的 Google Gemini Flash 及其低推理成本(每百万个 token 0.075 美元),向流行的仅解码器模型提供 15 万亿个 token 也需要花费超过一百万美元!
性能
以下是 ModernBERT 和其他模型在一系列任务中的准确率比较 。ModernBERT 是唯一在每个类别中都获得最高分的模型:
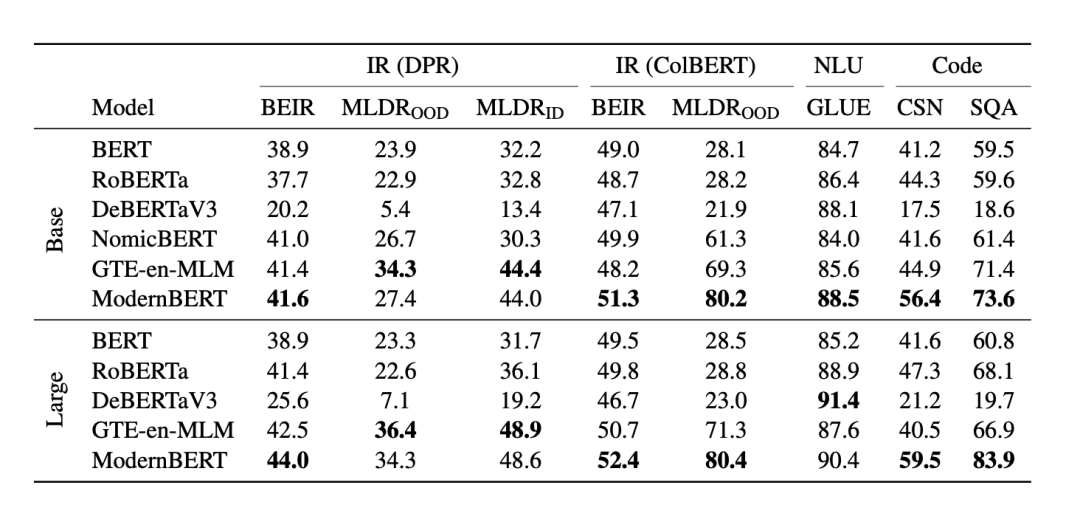
如果你了解 Kaggle 上的 NLP 竞赛,那么你就会知道 DeBERTaV3 多年来一直是处于冠军位置。但现在情况已经变了:ModernBERT 不仅是第一个在 GLUE 上击败 DeBERTaV3 的模型,而且它使用的内存还不到 Deberta 的 1/5。
当然,ModernBERT 的速度也很快,它的速度是 DeBERTa 的两倍 —— 事实上,在输入混合长度的情况下,速度最高可提高 4 倍。它的长上下文推理速度比其他高质量模型(如 NomicBERT 和 GTE-en-MLM)快近 3 倍。
ModernBERT 的上下文长度为 8,192 个 token,比大多数现有编码器长 16 倍以上。
对于代码检索,ModernBERT 的性能是独一无二的,因为之前从未有过编码器模型在大量代码数据上经过训练。例如,在 StackOverflow-QA 数据集 (SQA) 上,这是一个混合了代码和自然语言的混合数据集,ModernBERT 的专业代码理解和长上下文使其成为唯一一个在此任务上得分超过 80 的模型。
与主流模型相比,ModernBERT 在检索、自然语言理解和代码检索这三大类任务中表现突出。虽然 ModernBERT 在自然语言理解任务上稍微落后于 DeBERTaV3,但其速度要快很多倍。
与特定领域的模型相比,ModernBERT 在大多数任务中都相当或更胜一筹。此外,ModernBERT 在大多数任务中都比大多数模型更快,并且可以处理多达 8,192 个 token 的输入,比主流模型长 16 倍。
效率
以下是 ModernBERT 和其他解码器模型在 NVIDIA RTX 4090 上的内存(最大批大小,BS)和推理(以每秒数千个 token 为单位)效率对比结果:

对于可变长度的输入,ModernBERT 比其他模型都快得多。
对于长上下文输入,ModernBERT 比第二快的模型快 2-3 倍。此外,由于 ModernBERT 的效率,它可以使用比几乎任何其他模型都大的批处理大小,并且可以在更小、更便宜的 GPU 上有效使用。特别是基础模型的效率可能会使新应用程序能够直接在浏览器、手机等上运行。
ModernBERT
接下来文章解释了为什么我们应该更加重视编码器模型。作为值得信赖、但被低估的主力模型,自 2018 年 BERT 发布以来,它们的更新速度出奇地慢!
更令人惊讶的是:自 RoBERTa 以来,还没有编码器能够提供整体的改进:DeBERTaV3 具有更好的 GLUE 和分类性能,但牺牲了效率和检索。其他模型(例如 AlBERT)或较新的模型(例如 GTE-en-MLM)都在某些方面比原始 BERT 和 RoBERTa 有所改进,但在其他方面有所退步。
ModernBERT 项目主要有三个核心点:
现代化的 transformer 架构;
特别重视注意力效率;
以及数据。
认识新的 Transformer
Transformer 架构已成为主流,如今绝大多数模型都在使用它。但值得注意的是,Transformer 不止一个,而是有很多种。其主要共同点是,都坚信注意力机制才是所需要的一切,因此围绕注意力机制构建了各种改进。
用 RoPE 替换旧的位置编码:这使得模型能够更好地理解单词之间的关系,并允许扩展到更长的序列长度。
将旧的 MLP 层替换为 GeGLU 层,改进原始 BERT 的 GeLU 激活函数;
通过删除不必要的偏置项来简化架构,从而更有效地使用参数预算;
在嵌入后增加一个额外的归一化层,有助于稳定训练。
全局和局部注意力
ModernBERT 最具影响力的功能之一是 Alternating 注意力机制,而不是全局注意力机制。
随着注意力计算复杂度随着每个额外的 token 而膨胀,这意味着 ModernBERT 可以比任何其他模型更快地处理长输入序列。实际上,它看起来像这样:

Unpadding 和序列 Packing
另一个有助于 ModernBERT 提高效率的核心机制是 Unpadding 和序列 Packing。
为了能够处理同一批次中的多个序列,编码器模型要求序列具有相同的长度,以便可以执行并行计算。传统上的做法是依靠 padding 来实现这一点:找出哪个句子最长,并添加无意义的 token 来填充序列。
虽然填充解决了这个问题,但它并不优雅:大量的计算最终被浪费在填充 token 上,而这些 token 不会提供任何语义信息。

比较 padding 和序列 packing。序列 packing(unpadding )避免了模型在填充 token 上的计算浪费。
Unpadding 解决了这个问题,其不会保留这些填充 token,而是将它们全部删除,并将它们连接到批大小为 1 的小批次中,从而避免了不必要的计算。如果你使用的是 Flash Attention,unpadding 甚至比以前的方法更快,比以前的方法加快 10-20%。
训练
编码器落后的一大方面在于训练数据。在通常的理解中,这仅指的是训练数据规模,但事实并非如此:以往的编码器(如 DeBERTaV3)经过足够长时间的训练,甚至可能突破了万亿 tokens 规模。
但问题在于数据多样性:很多旧模型在有限的语料库上进行训练,通常包括 Wikipedia 和 Wikibooks。很明显,这些混合数据是单一的文本模态:它们只包含高质量的自然文本。
相比之下,ModernBERT 的训练数据具有多种英语来源,包括网页文档、代码和科学文章。该模型训练了 2 万亿 tokens,其中大多数是唯一的,而不像以往编码器那样常常重复 20 到 40 次。这种做法的影响是显而易见的:在所有的开源编码器中,ModernBERT 在编码任务上实现了 SOTA。
流程
团队坚持原始 BERT 训练方法,并在后续工作的启发下进行了一些小的升级,包括删除了下一句(Next-Sentence)预测目标,原因是它在增加开销的情况下没有明显的收益,并将掩蔽率从 15% 提高了 30%。
两个模型都采用三段式训练流程。首先在序列长度为 1024 的情况下训练了 1.7T tokens 的数据,然后采用一个长上下文适应阶段,在序列长度为 8192 的情况下训练了 250B tokens 的数据,同时通过降低批大小来保持每个批次的总 tokens 数大体一致。最后按照 ProLong 中强调的长上下文扩展思路,对不同采样的 50B tokens 数据进行退火。
从结果来看,三段式训练可以确保模型运行良好,在长上下文任务上具有竞争力,也不会影响其处理短上下文的能力。
此外还有另一个好处:对于前两个阶段,团队在预热阶段完成之后使用恒定学习率来训练,只对最后的 50B tokens 执行学习率衰减,并遵循了梯形(预热 - 稳定 - 衰减)学习率。更重要的是:受到 Pythia 的启发,团队可以在这些稳定的阶段发布每一个直接中间检查点。这样做的主要原因是支持未来的研究和应用:任何人都可以从团队的预衰减检查点重新开始训练,并对适合自己预期用途的域数据进行退火。
技巧
最后,该团队使用了两个技巧来加快实现速度。
第一个技巧很常见:由于初始训练步骤更新了随机权重,因而采用批大小预热。首先从较小的批大小开始,这样相同数量的 token 会更加频繁地更新模型权重,接下来逐渐增加批大小直到达到最终的训练大小。这样做大大加快了初始阶段的模型训练速度,其中模型学习到了最基础的语言理解。
第二个技巧不太常见:通过对较大的模型平铺(tiling)来进行权重初始化,这一灵感来自微软的 Phi 系列模型。该技巧基于以下认知:当我们有一组非常好的 ModernBERT-base 权重时,为什么要利用随机数来初始化 ModernBERT-large 的初始权重呢?的确,事实证明了,将 ModernBERT-base 的权重平铺到 ModernBERT-large 要比随机权重的初始化效果好。此外,该技巧跟批大小预热一样可以在堆叠后带来额外好处,从而更快地进行初始训练。
总之,ModernBERT 成为新的小型、高效的仅编码器 SOTA 系列模型,并为 BERT 提供了亟需的重做。另外证明了仅编码器模型可以通过现代方法得到改进,并在一些任务上仍能提供非常强大的性能,并实现极具吸引力的尺寸 / 性能比。
参考内容:
https://huggingface.co/blog/modernbert



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











