




机器之心报道
编辑:蛋酱、陈陈
最近,类 o1 模型的出现,验证了长思维链 (CoT) 在数学和编码等推理任务中的有效性。在长思考(long thought)的帮助下,LLM 倾向于探索、反思和自我改进推理过程,以获得更准确的答案。
在最近的一项研究中,微信 AI 研究团队提出了 DRT-o1,将长 CoT 的成功引入神经机器翻译 (MT)。实现这一目标有两个关键点:
一是适合在机器翻译中使用长思考的翻译场景:并不是所有的场景都需要在翻译过程中进行长思考。例如,对于简单的表达,直译就可以满足大多数需求,而长思考的翻译可能没有必要;
二是一种能够合成具有长思考能力的机器翻译数据的方法。
展开来说,文学书籍中可能会涉及明喻和隐喻,由于文化差异,将这些文本翻译成目标语言在实践中是非常困难的。在这种情况下,直译往往无法有效地传达预期的含义。即使是专业的人工翻译,也必须在整个翻译过程中仔细考虑如何保留语义。
为了在 MT 中模拟 LLM 的长思考能力,本文首先从现有文学书籍中挖掘包含明喻或隐喻的句子,然后开发出了一个多智能体框架通过长思考来翻译这些句子。
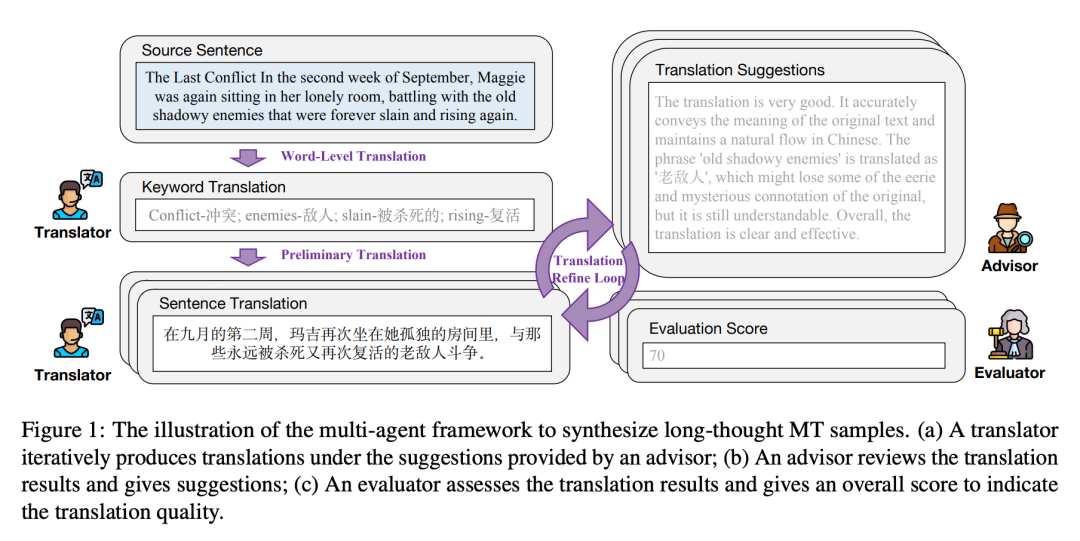
该框架有三个智能体,即翻译者(translator)、顾问(advisor)和评估者(evaluator)。数据合成过程是迭代的,每次迭代包括以下三个步骤:
(1)翻译者根据前一步的翻译和顾问的相应改进建议生成新的翻译;
(2)顾问评估当前翻译并提供详细反馈;
(3)评估者评估当前翻译并使用预定义的评分标准给出评估分数。一旦评估者提供的翻译分数达到预定义的阈值或迭代次数达到最大值,迭代将停止。
此后,每一步中的翻译和建议都可以形成长思考的机器翻译样本。为了提高长思考数据的可读性和流畅性,本文使用 GPT-4o 来重新表述长思考的内容。
基于收集的长思考机器翻译样本,本文分别使用 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 作为主干模型,对 DRT-o1-7B 和 DRT-o1-14B 进行训练(SFT)。在文学翻译上的实验结果证明了 DRT-o1 的有效性。例如,DRT-o1-7B 的表现比 Qwen2.5-7B-Instruct 高出 8.26 BLEU、1.31 CometKiwi 和 3.36 CometScore。它的表现也比 QwQ32B-Preview 高出 7.82 BLEU 和 1.46 CometScore。
本文贡献主要包括:
提出 DRT-o1,旨在构建具有长思考机器翻译能力的 LLM。为了实现这一目标,本文挖掘了带有明喻或隐喻的文学句子,并收集具有长思考过程的机器翻译样本;
为了合成长思考机器翻译样本,本文提出了一个多智能体框架,其中包括翻译者、顾问和评估者。这三个智能体以迭代方式协作,在机器翻译过程中产生长思考。最后,使用 GPT4o 进一步提高合成长思考机器翻译样本的质量;
在文学翻译上的实验结果验证了 DRT-o1 的有效性,通过长思考,LLM 可以在机器翻译过程中学会思考。

论文标题:DRT-o1: Optimized Deep Reasoning Translation via Long Chain-of-Thought
论文链接:https://arxiv.org/pdf/2412.17498
项目地址:https://github.com/krystalan/DRT-o1
DRT-o1 数据
论文以英译汉为研究对象,在本节中通过三个步骤介绍如何收集 DRT-o1 训练数据:
(1)收集在翻译过程中往往需要长时间思考的英语句子(§ 2.1);
(2)通过设计的多智能体框架对收集到的句子进行长时间思考翻译过程的合成(§ 2.2);
(3)改进长时间思考内容的可读性和流畅性,形成最终的长时间思考 MT 样本(§ 2.3)。
最后,对收集到的数据进行统计,加深理解(§ 2.4)。
文学图书挖掘
研究者利用了古腾堡计划公共领域书籍库中的文学书籍,这些书籍通常有 50 多年的历史,其版权已过期。他们利用了大约 400 本英文书籍来挖掘含有比喻或隐喻的句子。
首先,从这些书籍中提取所有句子,并过滤掉太短或太长的句子,即少于 10 个单词或多于 100 个单词的句子,最终得到 577.6K 个文学句子。
其次,对于每个句子,使用 Qwen2.5-72B-Instruct 来判断该句子是否包含比喻或隐喻,并舍弃不包含比喻或隐喻的句子。
第三,对于剩下的句子,让 Qwen2.5-72B-Instruct 将其直译为中文,然后判断译文是否符合母语为中文的人的习惯。如果答案是否定的,则保留相应的句子,将其视为「适合长思考翻译」。
这样,最终从 577.6K 个涉及比喻或隐喻的文学句子中收集了 63K 个直译也有缺陷的句子,称为预收集句子。
多智能体框架
对于每个预先收集的句子(用 s 表示),研究者设计了一个多智能体框架,通过长时间的思考将其从英文翻译成中文。如图 1 所示,框架包括三个智能体:翻译者、顾问和评估者。合成过程如下:
(1) 词语级翻译。
(2) 初步翻译。
(3) 翻译完善循环。
长思考重配方
经过多智能体协作,得到了一个漫长的思考过程:
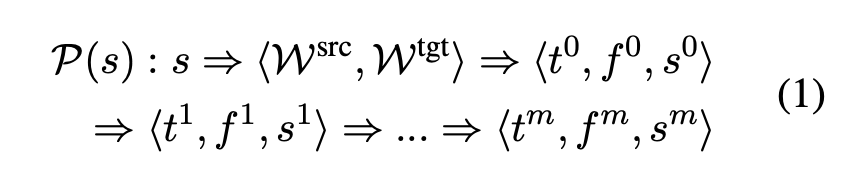
其中,P (s) 表示 s 的多智能体思考过程,m 为迭代步数。为了强调有效的思维过程,没有分数变化的翻译将被删除。也就是说,如果 s^i 等于 s^(i-1)(i = 1,2,...,m),研究者将舍弃 P (s) 中的⟨t^i , f^i , s^i ⟩,结果为:
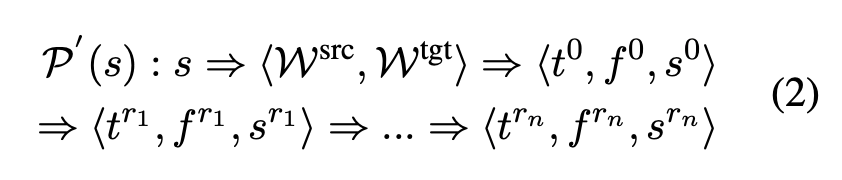
其中 1≤r_1 < r_2 < ... < r_n ≤ m,n 为剩余步数。如果 n < 3,将放弃整个样本,即 P (s) / P′ (s)。
对于其余样本,研究者效仿 Qin et al. (2024) 的做法,利用 GPT-4o 将 P ′ (s) 修改并打磨为自我反思描述。最后,获得了 22264 个带有长思考的机器翻译样本。图 2 举例说明了合成结果。

数据统计
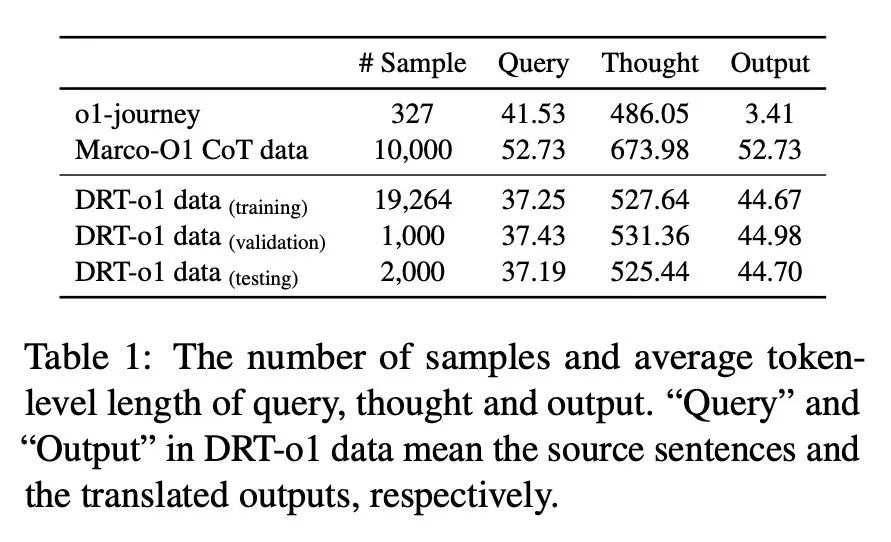
研究者将收集到的 22264 个样本分为训练集、验证集和测试集,样本数分别为 19264、1000 和 2000。表 1 列出了 DRT-o1 数据和以往类似 O1 数据的数据统计。对于 Marco-O1 CoT 数据,由于其尚未完全发布,此处使用其演示数据来计算数据统计。可以看到,合成的思考中的平均 token 数达到了 500 多个,这与之前面向数学的 O1 类 CoT 数据相似。
实验
为了计算 CometKiwi 和 CometScore,研究者使用了官方代码和官方模型。为了计算 BLEU 分数,使用 sacrebleu 工具包计算语料库级别的 BLEU。此处,研究者采用 Qwen2.5-7B-Instruct 和 Qwen2.5-14B-Instruct 作为 DRT-o1 的骨干。
下表 2 显示了文献翻译的结果。研究者将 DRT-o1-7B 和 DRT-o1- 14B 与之前的 Qwen2.5-7B-Instruct、Qwen2.5- 14B-Instruct、QwQ-32B-preview 和 Marco-o1- 7B 进行了比较。根据收集到的数据进行指令调整后,DRT-o1-7B 的 BLEU、CometKiwi 和 CometScore 分别为 8.26、1.31 和 3.36,优于 Qwen2.5-7B-Instruct。DRT-o1-14B 在 7.33 BLEU、0.15 CometKiwi 和 1.66 CometScore 方面优于 Qwen2.5-14B-Instruct。此外,DRT-o1-14B 在所有指标方面都取得了最佳结果,显示了长思考在机器翻译中的有效性。

图 3 显示了 DRT-o1-14B 的一个示例。可以看到,该模型学习了收集的数据的思维过程。DRT-o1-14B 首先执行词级翻译,然后尝试初步翻译。接下来,它会不断改进翻译,直到它认为翻译足够好为止。

更多研究细节,可参考原论文。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











