




AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本文由香港科技大学(广州)、上海人工智能实验室、中国人民大学及南洋理工大学联合完成。主要作者包括香港科技大学(广州)研究助理党运楷、黄楷宸、霍家灏(共同一作)、博士生严一博、访学博士生黄思睿、上海AI Lab青年研究员刘东瑞等,通讯作者胡旭明为香港科技大学/香港科技大学(广州)助理教授,研究方向为可信大模型、多模态大模型等。
本文介绍了首个多模态大模型(MLLM)可解释性综述,由香港科技大学(广州)、上海人工智能实验室、以及中国人民大学联合发布。文章系统梳理了多模态大模型可解释性的研究进展,从数据层面(输入输出、数据集、更多模态)、模型层面(词元、特征、神经元、网络各层及结构)、以及训练与推理过程三个维度进行了全面阐述。同时,深入分析了当前研究所面临的核心挑战,并展望了未来的发展方向。本文旨在揭示多模态大模型决策逻辑的透明性与可信度,助力读者把握这一领域的最新前沿动态。

论文名称:Towards Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
论文链接:https://arxiv.org/pdf/2412.02104
多模态大模型可解释性
近年来,人工智能(AI)的迅猛发展深刻地改变了各个领域。其中,最具影响力的进步之一是大型语言模型(LLM)的出现,这些模型在文本生成、翻译和对话等自然语言任务中展现出了卓越的理解和生成能力。与此同时,计算机视觉(CV)的进步使得系统能够高效地处理和解析复杂的视觉数据,推动了目标检测、动作识别和语义分割等任务的高精度实现。这些技术的融合激发了人们对多模态 AI 的兴趣。多模态 AI 旨在整合文本、视觉、音频和视频等多种模态,提供更丰富、更全面的理解能力。通过整合多种数据源,多模态大模型在图文生成、视觉问答、跨模态检索和视频理解等多模态任务中展现了先进的理解、推理和生成能力。同时,多模态大模型已在自然语言处理、计算机视觉、视频分析、自动驾驶、医疗影像和机器人等领域得到了广泛应用。
然而,随着多模态大模型的不断发展,一个关键挑战浮现:如何解读多模态大模型的决策过程?
多模态大模型(MLLMs)的飞速发展引发了研究者和产业界对其透明性与可信度的强烈关注。理解和解释这些模型的内部机制,不仅关系到学术研究的深入推进,也直接影响其实际应用的可靠性与安全性。本综述聚焦于多模态大模型的可解释性,从以下三个关键维度展开深入分析:
1. 数据的解释性:数据作为模型的输入,是模型决策的基础。本部分探讨不同模态的输入数据如何预处理、对齐和表示,并研究通过扩展数据集与模态来增强模型的可解释性,增强对模型决策的理解。
2. 模型的解释性:本部分分析模型的关键组成部分,包括词元、特征、神经元、网络层次以及整体网络结构,试图揭示这些组件在模型决策中的具体作用,从而为模型的透明性提供新的视角。
3. 训练与推理的解释性:本部分探讨模型的训练和推理过程可能影响可解释性的因素,旨在理解模型的训练和推理过程背后的逻辑。
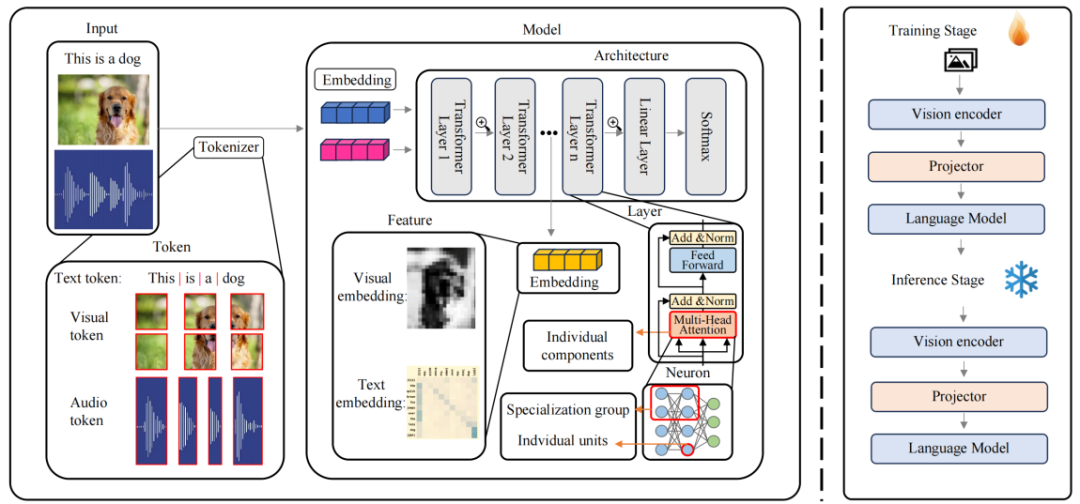
多模态大模型可解释性文章汇总
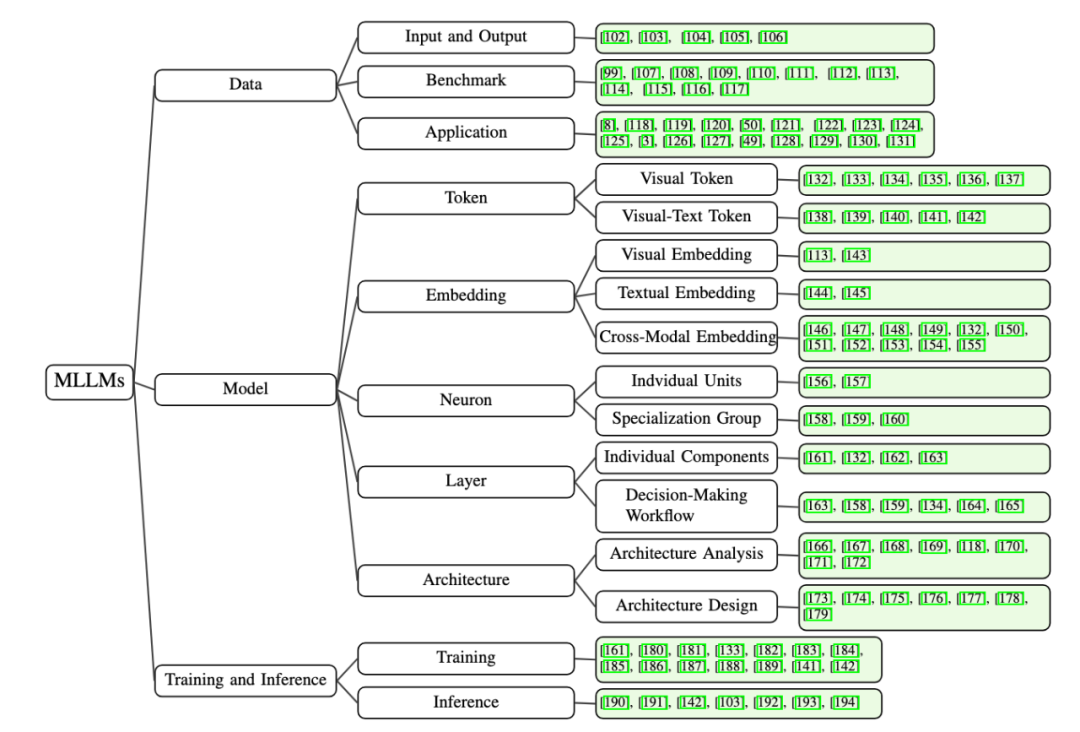
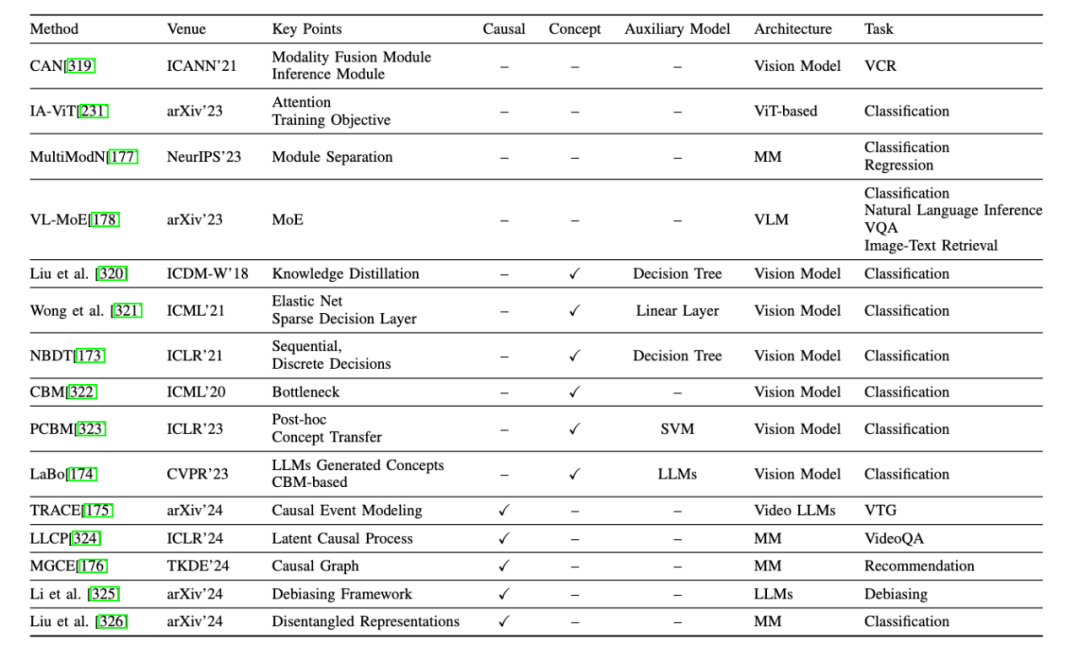
我们将现有的方法分类为三个视角:数据(Data)、模型(Model)和训练及推理(Traning & Inference)。具体如下:
1、数据视角的可解释性:从输入(Input)和输出(Output)角度出发,研究不同数据集(Benchmark)和更多模态的应用(Application),探讨如何影响模型的行为与决策透明性。
2、模型视角的可解释性:我们深入分析了模型内部的关键组成部分,重点关注以下五个维度:
Token:研究视觉词元(Visual Token)或视觉文本词元(Visual-textual Token)对模型决策的影响,揭示其在多模态交互中的作用。
Embedding:评估多模态嵌入 (Visual Embedding, Textual Embedding, Cross-modal Embedding) 如何在模型中进行信息融合,并影响决策透明度。
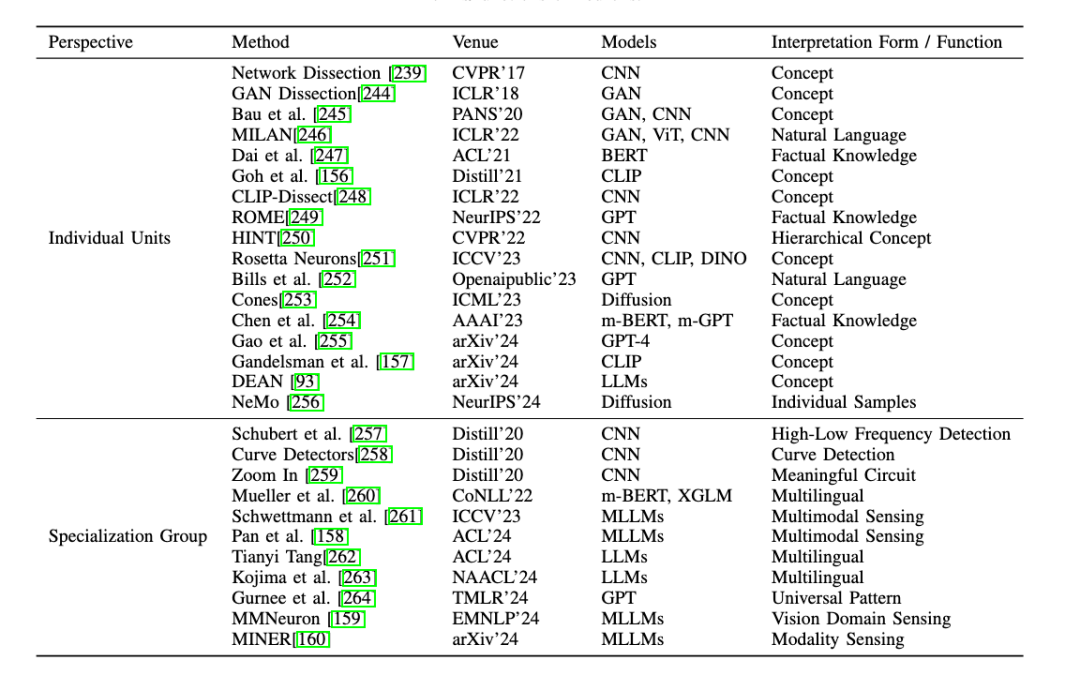
Neuron:分析个体神经元(Indvidual Units)和神经元组 (Specialization Group) 对模型输出的贡献。
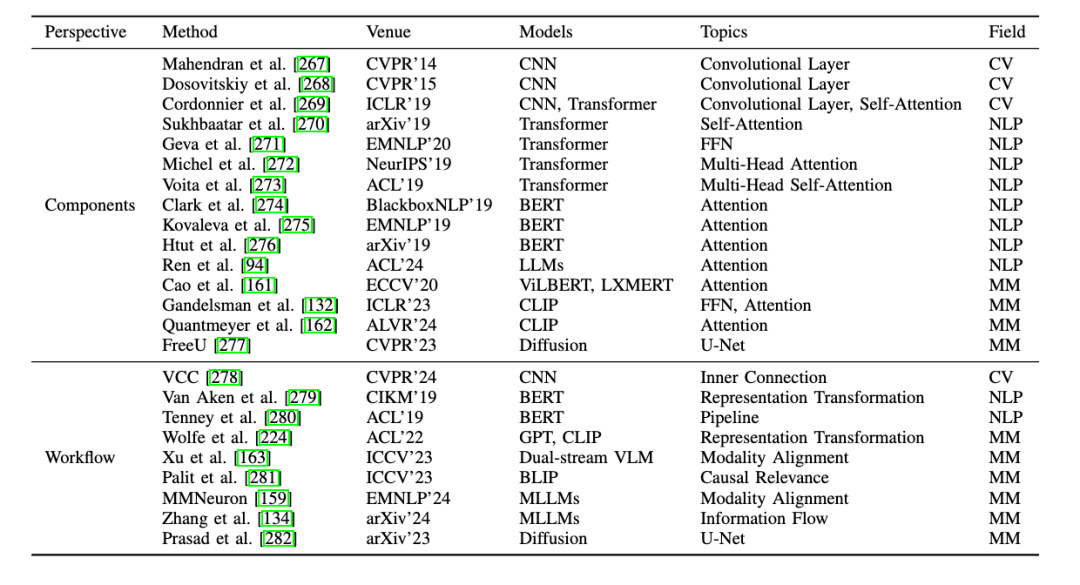
Layer:探讨单个网络层(Individual Components)和不同网络层(Decision-Making Workflow)在模型决策过程中的作用。
Architecture:通过对网络结构分析(Architecture Analysis)和网络结构设计(Architecture Design),促进模型架构的透明度和可理解性。
3、训练与推理的可解释性:我们从训练和推理两个阶段研究多模态大模型的可解释性:
训练阶段:总结多模态大模型预训练机制或训练策略,重点讨论如何增强多模态对齐、减少幻觉现象,对提高模型可解释性。
推理阶段:研究无需重新训练的情况下,缓解幻觉等问题的方法,如过度信任惩罚机制和链式思维推理技术,以提升模型在推理阶段的透明性和鲁棒性。
解码多模态大模型
从词元到网络结构的可解释性全面剖析
词元与嵌入(Token and Embedding) 的可解释性:词元(Token)和嵌入(Embedding)作为模型处理和表示数据的关键单元,对于模型的可解释性具有重要意义。
词元研究:我们通过分析视觉词元 (Visual Token),揭示了模型如何将图像分解为基本视觉组件,从而理解单个词元对预测的影响。同时,通过探索视觉 - 文本词元 (Visual-Textual Token) 的对齐机制,揭示其在复杂任务(如视觉问答、活动识别)中的影响。
嵌入研究:在特征嵌入 (Embedding) 方面,研究聚焦于多模态特征的表示方式,旨在提升模型的透明度和可解释性。例如,通过生成稀疏、可解释的向量,捕捉多模态的语义信息,进一步揭示特征嵌入在多模态对齐中的作用。
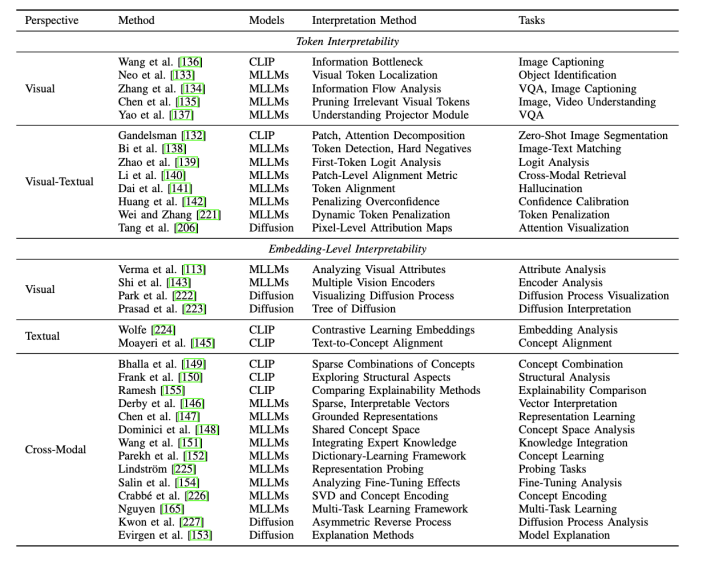
神经元 (Neuron) 的可解释性:神经元是多模态大模型的核心组件,其功能和语义角色的研究对揭示模型内部机制至关重要。
单个神经元的研究:对于单个神经元,一些研究通过将单个神经元与特定的概念或功能关联起来,发现能够同时响应视觉和文本概念的神经元,为理解多模态信息整合提供新的视角。
神经元群体的研究:对于神经元群体,研究表明某些神经元组可以集体负责特定任务,例如检测图像中的曲线、识别高低频特征,或在语言模型中调节预测的不确定性。此外,在多模态任务中,神经元群体被用来连接文本和图像特征,提出了新的方法来检测跨模态神经元,为多模态信息处理的透明化提供了重要依据。
层级结构 (Layer) 的可解释性:深度神经网络由多个层级组成,层级结构的研究揭示了各层在模型决策过程中的作用。
单个层的研究:研究者探索了注意力头(Attention Heads)、多层感知器(MLP)等层内组件对于模型决策的影响。
跨层研究:对跨层的整体决策过程进行分析,增强跨模态信息的整合能力。
网络结构(Architecture)的可解释性:除了在神经元和层级层面探讨多模态大模型的可解释性外,一些研究还从更粗粒度的网络结构层面进行探索。与之前聚焦于 MLLMs 具体组件的方法不同,这里从整体网络结构视角出发,研究分为网络结构分析与设计两大类:
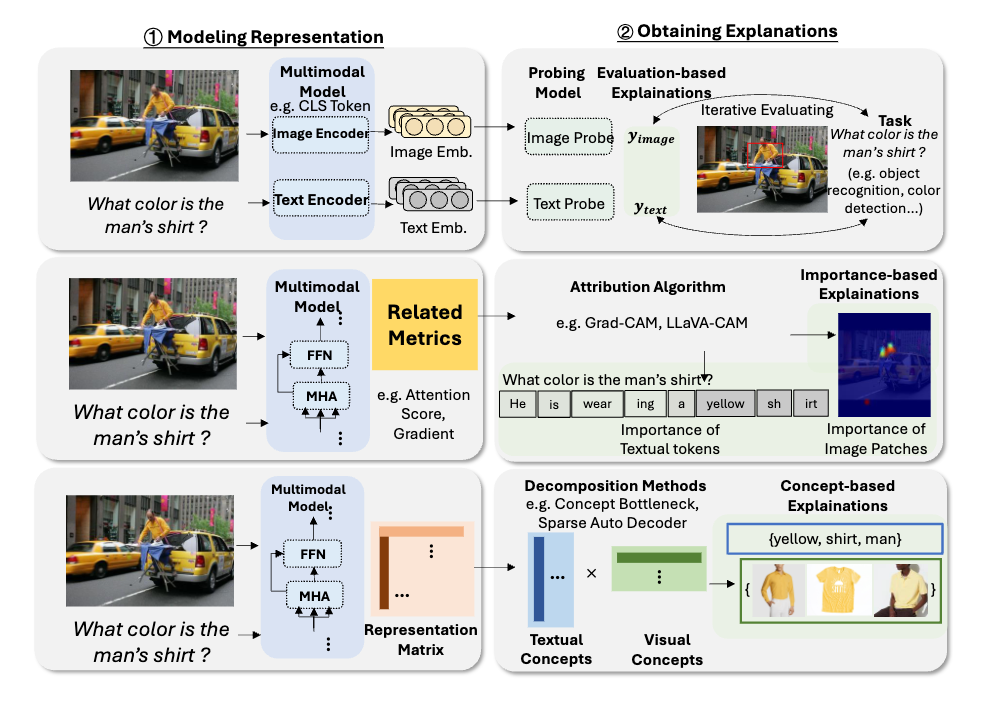
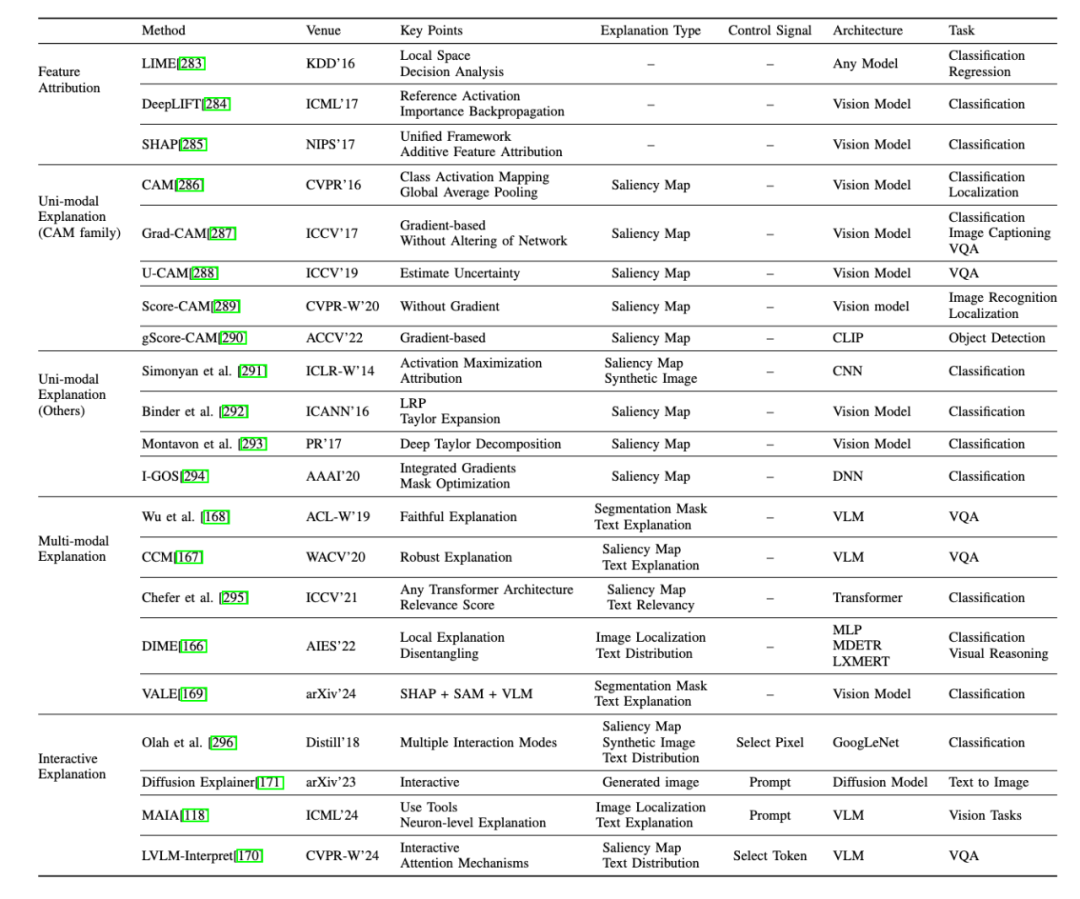
1、网络结构分析:这种方法独立于任何特定的模型结构或内部机制,包括:
特征归因:通过为特征分配重要性分数,提供基础性解释方法,。
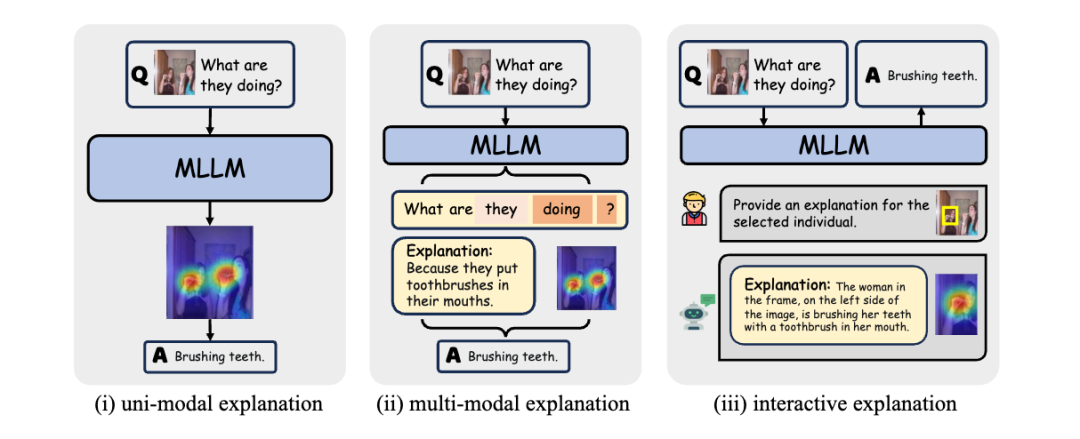
单模态解释:提供单一模态(主要是图像模态)的解释。
多模态解释:提供多模态(如图像和文本结合)的解释。
交互式解释:根据人类的指令或偏好提供解释的方法。
其他:包括通过模型比较提供探究的网络结构级模型分析方法等。
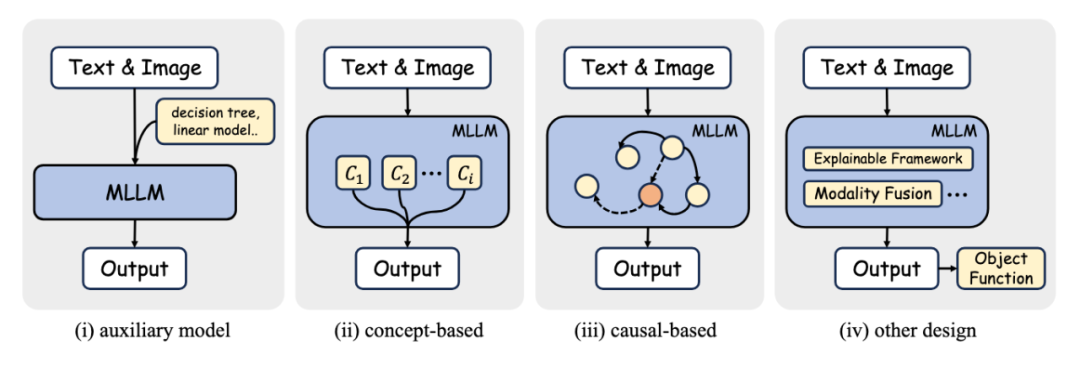
2、网络结构设计:这类方法通过在模型网络结构中引入高度可解释的模块来增强模型的可解释性。专注于特定的模型类型,利用独特的结构或参数来探索内部机制。这一类包括:
替代模型:使用更简单的模型,如线性模型或决策树,来近似复杂模型的性能。
基于概念的方法:使模型能够学习人类可理解的概念,然后使用这些概念进行预测。
基于因果的方法:在网络结构设计中融入因果学习的概念,如因果推理或因果框架。
其他:包括网络结构中无法归类到上述类别的其他模块相关的方法。
训练和推理(Training & Inference)的可解释性:在多模态大模型(MLLMs)的训练与推理中,通过优化策略提升模型的透明性:
训练阶段:通过合理的预训练策略优化多模态对齐,揭示跨模态关系,同时减少生成过程中的偏差与幻觉现象,为模型鲁棒性提供支持。
推理阶段:链式思维推理和上下文学习技术为实现结构化、可解释的输出提供了新的可能性。这些方法有效缓解了模型在生成内容中的幻觉问题,有效提升了模型输出的可信度。
挑战与机遇并存
多模态大模型的可解释性未来展望?
随着多模态大模型(MLLMs)在学术与工业界的广泛应用,可解释性领域迎来了机遇与挑战并存的未来发展方向。以下是我们列出一些未来的展望:
数据集与更多模态的融合:改进多模态数据的表示和基准测试,开发标准化的预处理和标注流程,确保文本、图像、视频和音频的一致性表达。同时,建立多领域、多语言、多模态的评估标准,全面测试模型的能力。
多模态嵌入与特征表示:加强对模型预测结果的归因,探索动态词元重要性机制,确保结果与人类表达方式一致。通过优化视觉与文本特征的对齐,构建统一框架,揭示模型处理多模态信息的内在机制。
模型结构的可解释性:聚焦神经元间的对齐机制和低成本的模型编辑方法,解析多模态信息处理中的关键内部机制。同时,探索视觉、音频等模态向文本嵌入空间对齐的过程,为跨模态理解提供支持。
模型架构的透明化:改进架构设计,深入分析不同模块在跨模态信息处理中的作用,揭示从模态输入到集成表示的全流程信息流动。这将提升模型的鲁棒性与信任度,并为实际应用提供更可靠的支持。
训练与推理的统一解释框架:在训练阶段优先考虑可解释性和与人类理解的对齐,推理阶段提供实时、任务适配的可解释结果。通过建立覆盖训练与推理的统一评估基准,开发出透明、可靠且高性能的多模态系统。
未来的研究不仅需要从技术层面推动多模态大模型的可解释性,还需注重其在人类交互和实际应用中的落地,为模型的透明性、可信性、鲁棒性和公平性提供坚实保障。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











