




论文第一作者为清华大学自动化系博士生韩东辰,指导老师为黄高副教授。他的主要研究方向包括高效模型架构设计、多模态大模型等。
Mamba 是一种具有线性计算复杂度的状态空间模型,它能够以线性计算复杂度实现对输入序列的有效建模,在近几个月受到了广泛的关注。
本文给出了一个十分有趣的发现:强大的 Mamba 模型与通常被认为性能不佳的线性注意力有着内在的相似性:本文用统一的公式表述了 Mamba 中的核心模块状态空间模型(SSM)和线性注意力,揭示了二者之间的密切联系,并探究了是哪些特殊的属性和设计导致了 Mamba 的成功。
实验结果表明,等效遗忘门和宏观结构设计是 Mamba 成功的关键因素。本文通过分析自然地提出了一个新的模型结构:Mamba-Inspired Linear Attention(MILA),它同时继承了 Mamba 和线性注意力的优点,在各种视觉任务中表现出超越现有的视觉 Mamba 模型的精度,同时保持了线性注意力优越的并行计算与高推理速度。

论文链接:https://arxiv.org/abs/2405.16605
代码链接:https://github.com/LeapLabTHU/MLLA
视频讲解:https://www.bilibili.com/video/BV1NYzAYxEbZ
最近,以 Mamba 为例的状态空间模型引起了广泛的研究兴趣。不同于 Transformer 的平方复杂度,Mamba 模型能够以线性复杂度实现有效的序列建模,在长文本、高分辨率图像、视频等长序列建模和生成领域表现出很大的潜力。
然而,Mamba 并不是第一个实现线性复杂度全局建模的模型。早期的线性注意力使用线性归一化代替 Softmax 注意力中的 Softmax 操作,将计算顺序从 (QK) V 更改为 Q (KV) ,从而将计算复杂度降低为线性。然而,之前的许多工作表明线性注意的表达能力不足,难以取得令人满意的效果。
令人惊讶的是,本文发现高性能的 Mamba 和表达能力不足的线性注意力的公式之间存在深层次的关联。因此,一个引人思考的研究问题是:是什么因素导致了 Mamba 的成功和它相较于线性注意力的显著优势?
从这个问题出发,本文在以下几个方面进行了探索:
1. 揭示了 Mamba 与 Linear Attention Transformer 之间的关系:Mamba 和 Linear Attention Transformer 可以使用统一的公式表示。进一步地,Mamba 可以视为具有若干特殊设计的线性注意力,其特殊设计为:输入门 (input gate)、遗忘门 (forget gate)、快捷连接 (shortcut)、无注意力的归一化、single-head 和更先进的宏观架构。
2. 实验证明,遗忘门和宏观架构很大程度上是 Mamba 性能成功的关键。然而,遗忘门会导致循环计算,可能并不适合视觉模型。本文发现,适当的位置编码能够在视觉任务中替代遗忘门的作用,同时保持并行计算和快速的推理。
3. 提出了一系列名为 MILA 的 Linear Attention Transformer 模型,它引入了 Mamba 的设计思想,并且比原始 Mamba 模型更适合视觉任务。
一、线性注意力与状态空间模型回顾
本文首先简略回顾线性注意力和状态空间模型的数学表达。本部分公式较多,详细推导请参考论文或视频讲解。
1. 线性注意力
对于输入序列,单头线性注意力可以表达为:
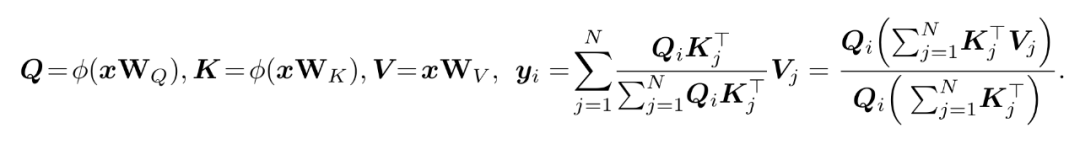
可以看到,线性注意力通过先计算 K 和 V 的乘积,将计算复杂度降低到。上式中,每个 Q 拥有全局感受野,可以与所有的 K、V 进行信息交互。实际应用中,线性注意力也可以应用在自回归的模型中,限制每个 token 只能与之前的 token 进行信息交互:
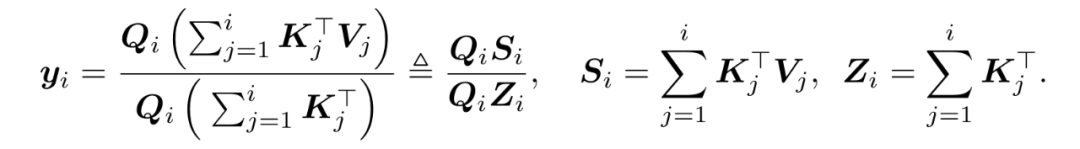
这种因果的线性注意力范式可以进一步写成循环形式:
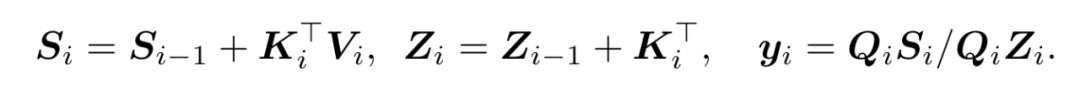
2. 状态空间模型
对于实数序列输入,Mamba 所采用的状态空间模型可以表达为:
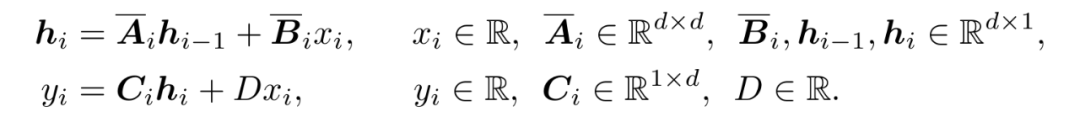
为了方便后续推导,此处对上式进行了 3 处数学表达上的等价变形,具体请参考原论文。等价变形后得到的公式为:
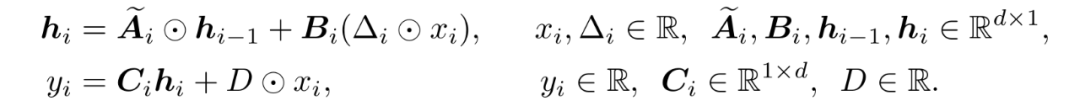
对于向量序列输入,Mamba 会在每个维度分别应用上式的实数输入 SSM,从而得到下面状态空间模型:
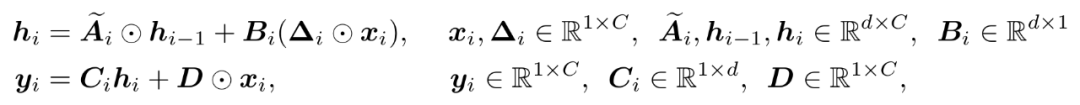
值得注意的是,上式严格等价于 Mamba 所进行的 SSM 操作,这里仅仅进行了数学表达形式上的等价变换。
二、Mamba 与线性注意力关系解析
对于输入序列,Mamba与线性注意力的公式之间有许多相似之处。为了便于比较,本文将二者使用相同的公式进行表达:
以下是上述两个公式的示意图:
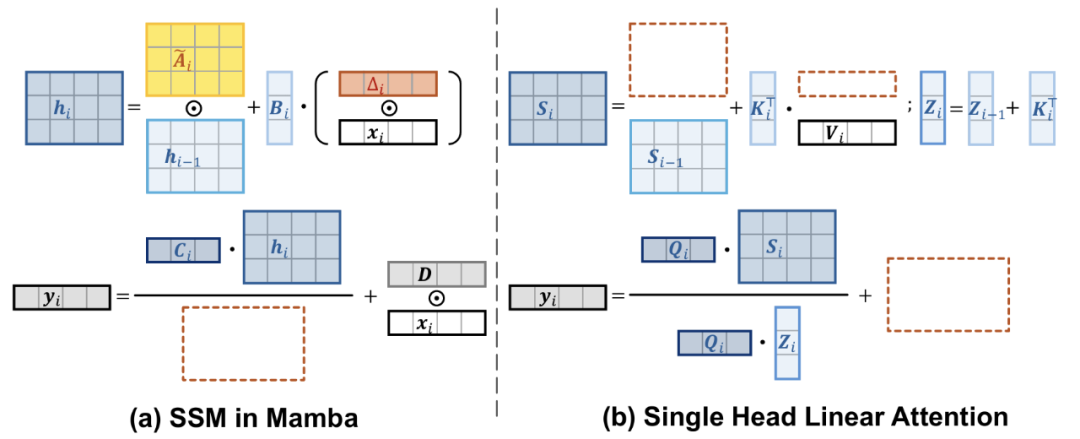 图 1:Mamba 与线性注意力操作示意图
图 1:Mamba 与线性注意力操作示意图从公式和示意图可以看到,Mamba 的 SSM 操作与线性注意力有深刻的联系。具体来说,SSM 中的 C 类似于线性注意力中的 Q,B 类似于 K^T ,x 类似于 V ,h 类似于 S。因此,Mamba 和线性注意力有着非常密切的关系,Mamba 可以被认为是一种特殊的线性注意力。此外,基于公式和示意图中还可以发现二者的几个不同点:
(1) 在 Mamba 中,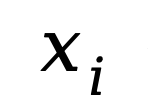


是每一位严格大于零的向量,因此可将其视为一个等效的输入门,可以控制
输入SSM的比例。
(2) 在 Mamba 中,有额外的与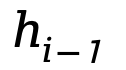
逐位相乘。在Mamba的实现中,
每一位都是0到1之间的实数,因此
实际控制对于之前的状态空间
的衰减程度,因此可将其理解为等效的遗忘门。
(3) Mamba 中,有一个额外的可学习的 shortcut,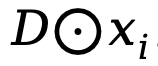
(4) 线性注意力中,有一个保证注意力之和为 1 的归一化分母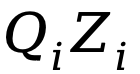
除此之外,该图和公式中的线性注意力都是单头设计,因为仅有一组 Q 和 K。所以可以认为 Mamba 等效于单头线性注意力,而没有采用多头设计(即多组 Q 和 K)。进一步,除了核心操作不同之外,Mamba 和传统的线性注意力模型在宏观结构上也有区别。二者的宏观结构如下图,Mamba 采用比较符合的结构,包含线性层、卷积、SSM 等。
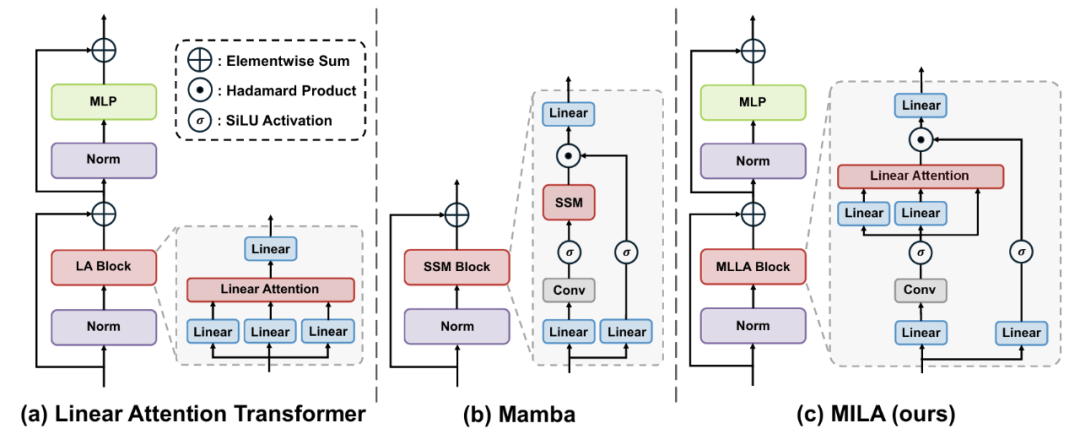 图 2:线性注意力模型、Mamba 和 MILA 的宏观模型架构
图 2:线性注意力模型、Mamba 和 MILA 的宏观模型架构总而言之,Mamba 可以视为具有 6 种特殊设计的线性注意力模型,其特殊设计为:输入门、遗忘门、shortcut、无注意力归一化、单头设计、更先进的宏观结构。
三、实验
Mamba 被视为 Transformer 的一种有力挑战者,而线性注意力通常性能不佳。在之前的分析中,本文发现这两种性能差距很大的模型具有深刻的相似性,并指出了他们之间的 6 个不同设计。接下来,本文通过实验来验证究竟是哪些设计导致了二者之间如此大的性能差距。
1. 核心验证实验
本文使用线性注意力作为 baseline 模型,在其基础上引入每一个不同设计,并在 ImageNet 上实验验证模型性能的变化。结果如下图所示:
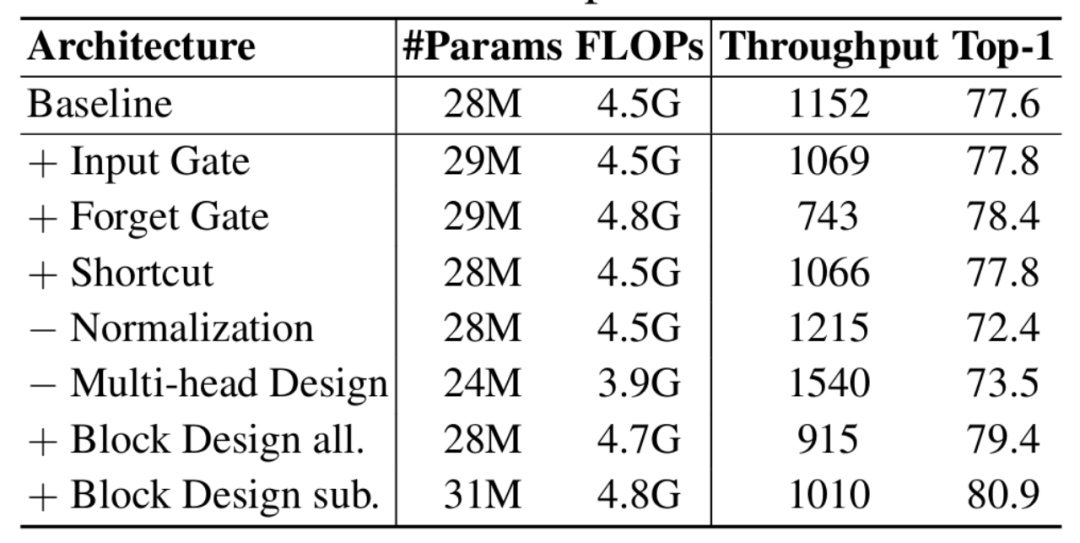 图 3:每个不同设计的影响
图 3:每个不同设计的影响可以看到,Mamba 的等效遗忘门和宏观设计对于模型性能最为关键,而其他设计影响不大或者不如线性注意力。同时,本文发现,由于遗忘门必须采用循环计算,引入遗忘门使得模型推理速度明显下降。遗忘门带来的循环计算对于语言模型等自回归模型是合适的,因为模型在推理时本来就需要不断自回归循环计算。然而,这种模式对于图像等非因果并不自然,因为它不仅限制了模型的感受野,还极大降低了模型的推理速度。本文发现,在视觉任务中,适当的位置编码能够引入类似遗忘门的位置信息,同时保持全局感受野、并行计算和更快的推理速度。
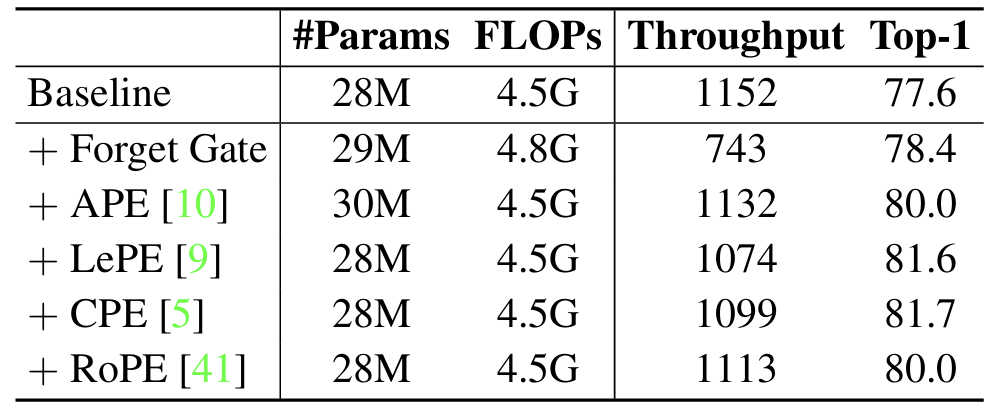 图 4:在视觉模型中用位置编码代替遗忘门
图 4:在视觉模型中用位置编码代替遗忘门2. MILA 模型
基于以上分析和验证,本文将 Mamba 和线性注意力的优秀设计结合起来,将 Mamba 的两项核心设计的精髓引入线性注意力,构建了 Mamba-Inspired Linear Attention (MILA) 模型。MILA 能够以线性复杂度实现全局建模,同时享有并行计算和更快的推理速度,在多种视觉任务上都取得了优于各类视觉 Mamba 模型的效果。以下是一些实验结果:
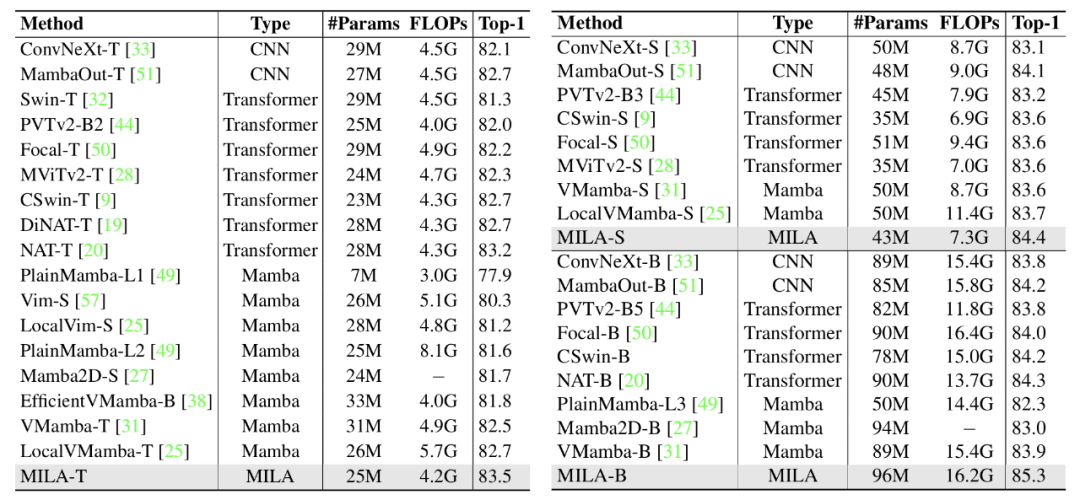 图 5:ImageNet 分类实验
图 5:ImageNet 分类实验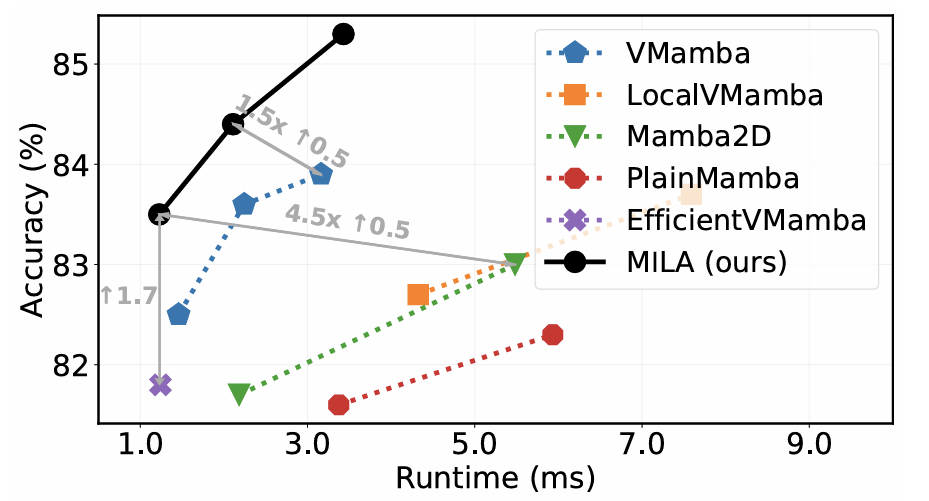
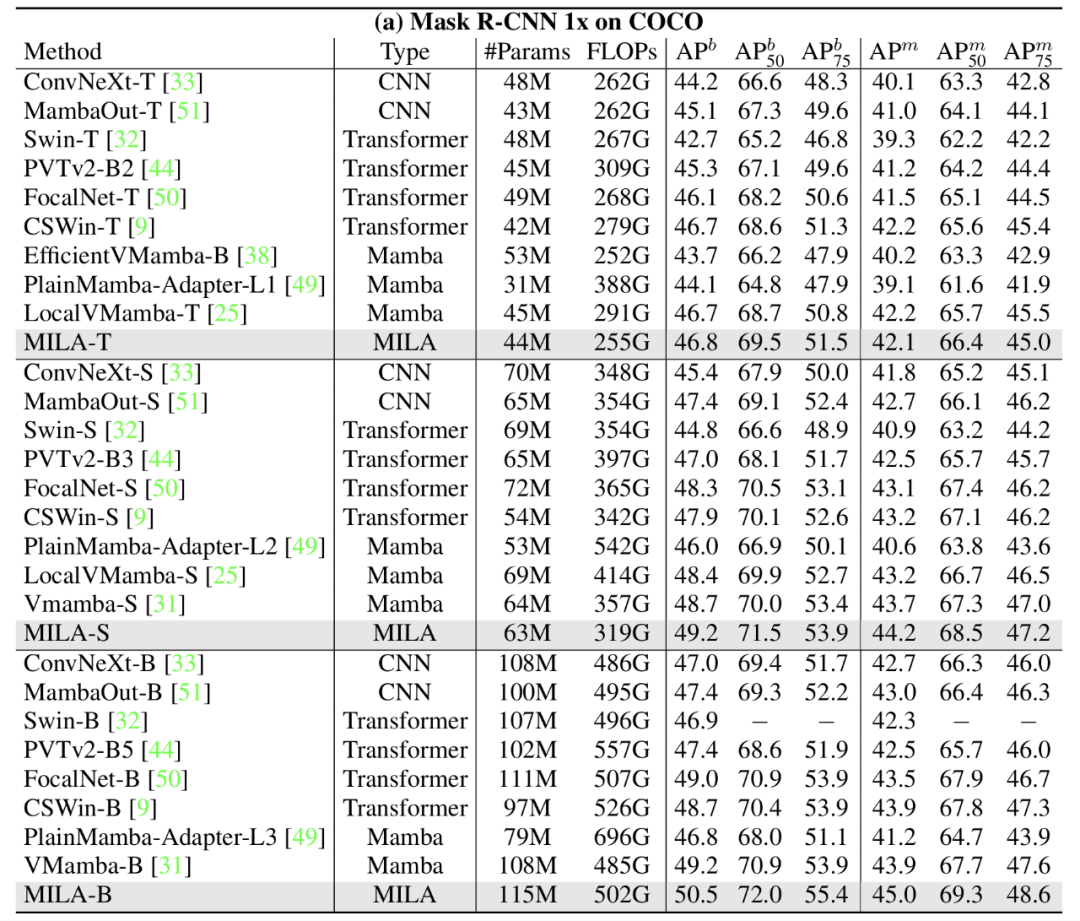 图 7:高分辨率下游任务 —— 物体检测
图 7:高分辨率下游任务 —— 物体检测四、总结
(1) Mamba 可以视为具有若干特殊设计的线性注意力,其特殊设计为:输入门 (input gate)、遗忘门 (forget gate)、快捷连接 (shortcut)、无注意力的归一化、单头设计 (single-head) 和更先进的宏观架构。
(2) 实验证明,遗忘门和宏观架构很大程度上是 Mamba 性能成功的关键。然而,遗忘门会导致循环计算,可能并不适合视觉模型。本文发现,适当的位置编码在视觉任务中替代遗忘门的作用,同时保持并行计算和快速的推理。
(3) 本文提出了一系列名为 MILA 的 Linear Attention Transformer 模型,它继承了 Mamba 的核心优点,并且比原始 Mamba 模型更适合视觉任务。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











