




强化微调可以轻松创建具备强大推理能力的专家模型。
昨天关于 o1 和 200 美元一个月的 o1-pro 的新闻已经消化完了吗?咱们该夸夸,该吐嘈就吐嘈,但也不得不说,OpenAI 是懂营销宣传的,至少这个 12 天连续发布的策略着实是赚足了眼球。

现在,OpenAI 的 12 天计划进入了第 2 天。凌晨两点,我们迎来了一个开发者和研究者更感兴趣的产品:Reinforcement Fine-Tuning,即强化微调。

今天参与发布的四人组是 OpenAI 研究副总裁 Mark Chen、OpenAI 技术员 John Allard 和 Julie Wang、Berkeley Lab 的环境基因组学和系统生物学研究者 Justin Reese。

Mark Chen 首先表示,今天发布的强化微调「允许你将你的黄金数据集转化为独特的产品,这将能让你将我们具有的神奇能力提供给你自己的用户和客户。」但它实际上要到明年才会真正公开推出。
OpenAI 微调团队 Steven Heidel 也在 X 上给出了一句话总结:

什么是强化微调?
去年,OpenAI 就已经为自家产品推出了监督式微调 API。简单来说,监督式微调要做的是让模型模仿它在输入文本或图像中找到的特征。这种强大的技术可用于修改模型的语气、样式或响应格式等等。
强化微调(RFT)则是一种更进一步模型定制技术,可让开发者使用强化学习针对具体任务对模型进行进一步的微调,并根据提供的参考答案对模型的响应进行评分。
也就是说,强化微调不仅会教模型模仿其输入,更是会让其学会在特定领域以新的方式进行推理。
具体来说,当模型发现问题时,要为它提供思考问题的空间,然后再对模型给出的响应进行打分。之后,利用强化学习的力量,可以强化模型得到正确答案的思维方式并抑制导向错误答案的思维方式。John Allard 表示:「只需几十个例子,模型就能学会在自定义领域以新的有效方式进行推理。」看起来,这种技术既能提高其在该领域特定任务上的准确性,还能增强模型对类似问题的推理能力。
Allard 还指出,OpenAI 内部在训练 GPT-4o 和 o1 系列模型时也使用了同样的技术。
Julie Wang 表示:「开发者、研究人员和机器学习工程师将能够使用强化学习来创建能够在其领域内擅长其特定任务的专家模型。我们相信,任何需要在 AI 模型方面拥有深厚专业知识的领域都能受益,比如法律、金融、工程、保险。」她举了个例子,OpenAI 最近与汤森路透合作,使用强化微调来微调 o1-mini,从而得到了好用的 AI 法律助理,能帮助他们的法律专业人员完成一些「最具分析性的工作流程」。
伯克利实验室的 Justin Reese 也谈到了强化微调对自己在罕见疾病方面的研究的帮助。他表示,罕见疾病其实并不罕见 —— 全球患有不同罕见疾病的人总数可达到 3 亿人;而罕见疾病患者在确诊之前往往需要数月乃至数年的漫长诊断过程。因为为了诊断出这些疾病,既需要医学专业知识,还必须基于生物医学数据进行系统性推理。而 o1 加上强化微调就能满足这样的需求。
如何实现强化微调?
OpenAI 通过一个根据症状推理预测可能基因的示例展现了强化微调的巨大潜力 —— 这实际上也正是伯克利实验室与 OpenAI 的合作项目之一。结果发现,使用强化微调后,模型规模更小的 o1-mini 的表现可超过性能更加强劲的 o1。
下面将基于具体示例介绍如何实现强化微调。
首先来看训练数据集。具体来说,这里的数据集是一个 .jsonl 文件,其中每一行都是一个训练样本。在这个示例中,数据集中包含 11 个样本。

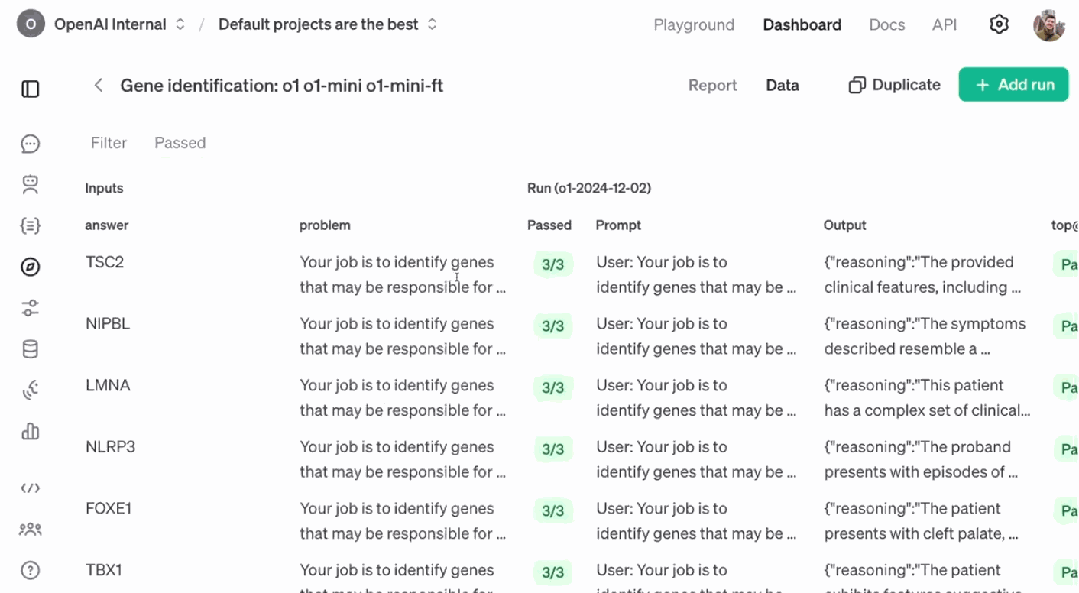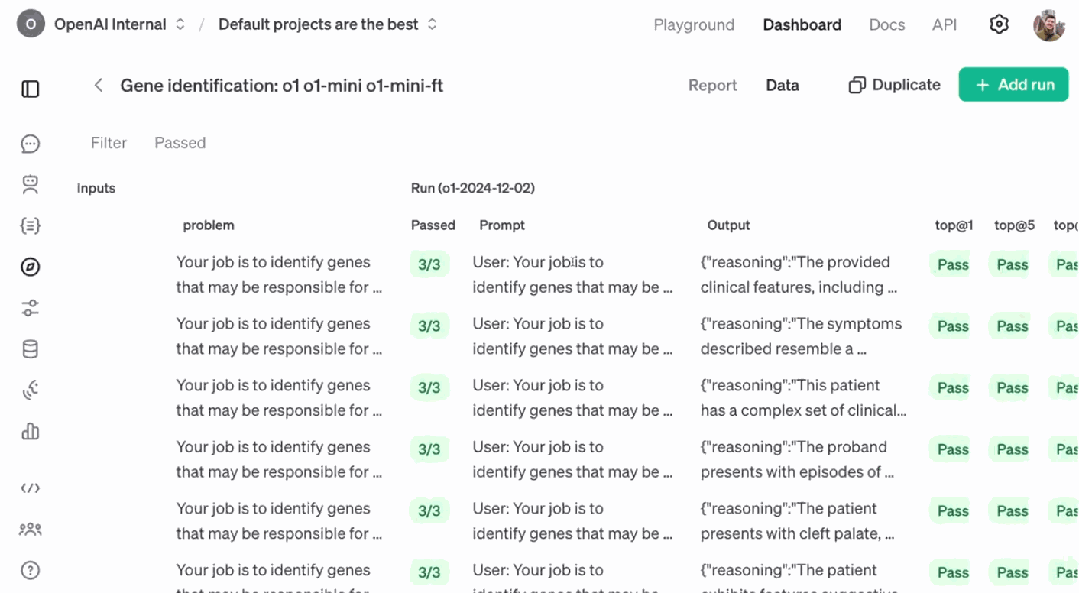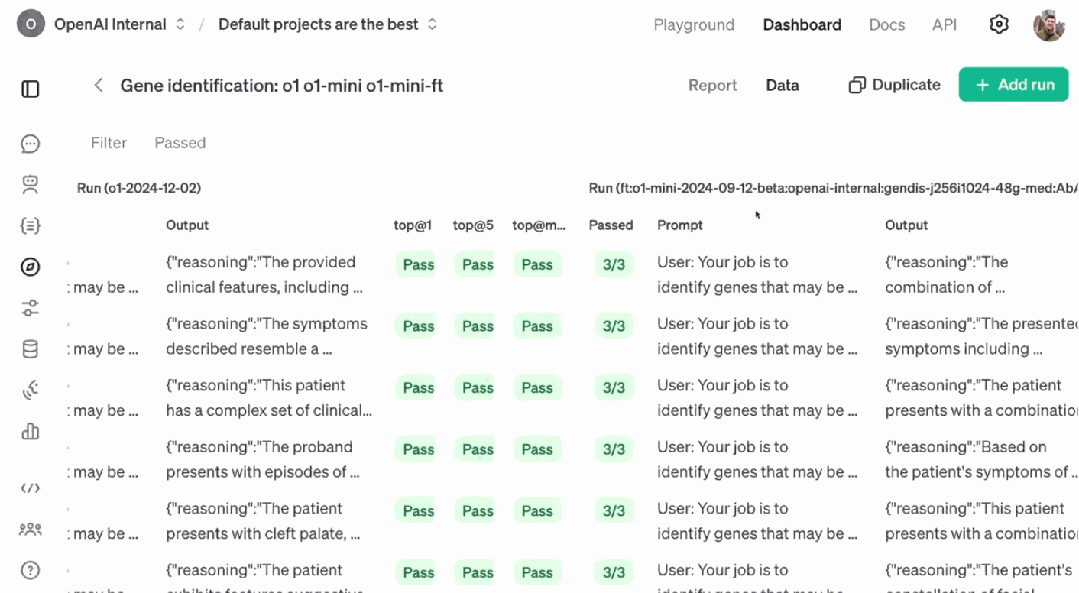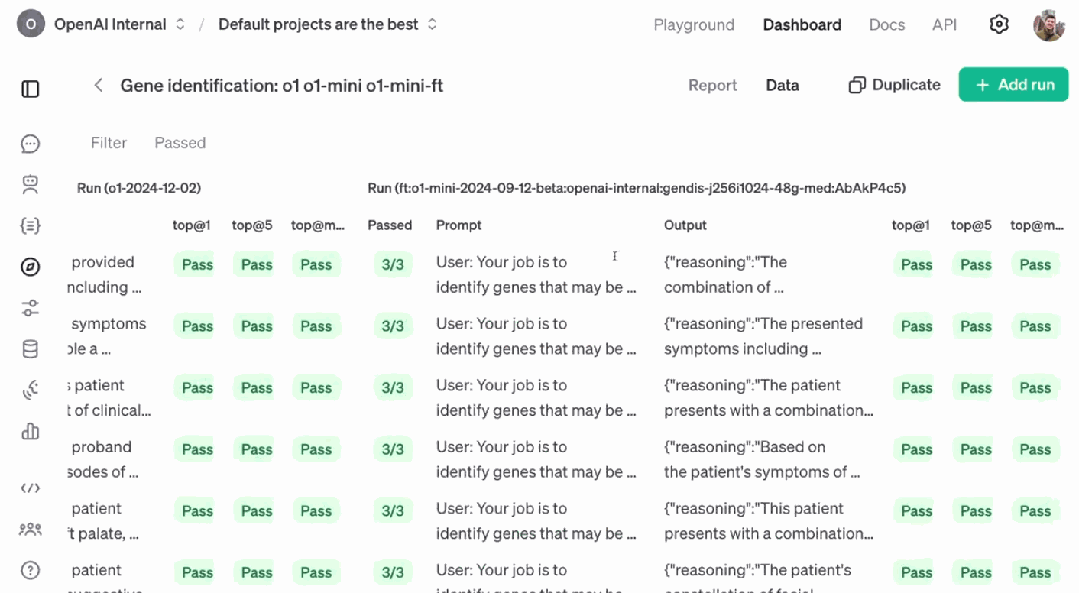
下面展示了一个具体数据样本。可以看到其中包含三项:病例报告(包含基本信息、症状以及没有的症状)、指令和正确答案。

在强化微调的训练过程中,模型并不能看到正确答案。在给模型提供病例报告和指令之后,模型会输出如上图底部所示的响应 —— 一个基因列表,其中排在第一位的基因是模型认为最可能的基因,以此类推。
接下来,还需要上传一个验证数据集。验证数据与训练数据的格式完全一样,但内容没有重叠。这样才能验证模型能否在该任务上进行泛化,而不仅仅是记住了训练数据。

在训练过程中,强化微调的「强化」部分就体现在评分器(Grader)的使用上。其设计思路很简单,评分器会比较模型输出与正确答案,然后返回一个 0 到 1 之间的分数。0 表示模型的输出中不包含正确答案,而 1 表示正确答案在输出的第一个位置。如下图所示,正确答案在第 2 个位置,评分器给出了 0.7 的分数。

当然,有些任务的输出结果并不是列表形式,因此 OpenAI 也提供了其它评分器,可以「相当有效地覆盖你可能拥有的意图的空间」。并且他们也在不断增加更多评分器,未来也会支持用户自己定制的评分器。

配置好评分器之后,用户还可以选择调整模型种子和一些超参数,包括批量大小、学习率乘数、epoch 数量。

接下来,点击 Create,再等待一段时间,用户就能得到经过强化微调的定制模型。Allard 表示,根据具体任务的不同,这个训练过程可能需要数小时到数天时间。

接下来,他演示了一个之前已经微调好的模型,以下截图展示了该模型的相关信息,可以看到基础模型是 o1-mini,经过强化微调后会得到一个输出模型。

同一个页面中还能看到模型在验证数据集上的分数变化情况。

那么,这个经过强化微调的 o1-mini 的表现究竟如何呢?评估结果表明,在 top@1(正确答案在列表第 1 个位置的概率)、top@5(正确答案在列表前 5 个位置的概率)和 top@max(输出中包含正确答案的概率)指标上,其表现都明显胜过性能更加强大的最新版 o1。


下面展示了一些运行过程示例:
当然,强化微调是一种通用技术。理论上,只要有合适的数据集和评估器,你就能将 o1 训练成你的专业 AI 助手。
目前,OpenAI 仅支持强化微调的 Alpha 测试申请,并且名额有限,「非常适合正在与专家团队一起处理非常复杂任务的组织」,个人用户至少得等到明年了。如果你有需求,可以在这里尝试申请:
https://openai.com/form/rft-research-program/
同样,今天的发布也在一个圣诞笑话中收尾:
圣诞老人正在努力制造一辆自动驾驶雪橇,但由于某种原因,他的模型一直无法识别树木,导致雪橇老是撞树。你猜原因是什么?
因为他没有 pine-tune 自己的模型。
你看懂这个🎄谐音梗笑话了吗?对强化微调又有何感想呢?



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











