




三人是紧密的合作伙伴。
最近,OpenAI 又迎来了新的人事变动,但这次不是某个技术大牛离职,而是从谷歌挖来了一些新鲜血液。
这些「新人」来自谷歌 DeepMind 的苏黎世办事处,包括资深研究科学家 Xiaohua Zhai(翟晓华)、研究科学家 Lucas Beyer 和 Alexander Kolesnikov。在谷歌 DeepMind 工作期间,三人就是密切的合作伙伴,共同参与了 ViT 等重要研究。之后,他们将一起建立 OpenAI 苏黎世办事处。

OpenAI 高管在周二的一份内部备忘录中告诉员工,三人入职后将从事多模态 AI 研究。
在 DeepMind 工作期间,Beyer 似乎一直在密切关注 OpenAI 发布的研究成果以及该公司卷入的公共争议,他经常在 X 上向自己的 7 万多名粉丝发布相关信息。去年,当首席执行官 Sam Altman 被 OpenAI 董事会短暂解雇时,Beyer 发帖称,他目前读到的关于解雇的「最合理」解释是,Altman 同时参与了太多其他初创公司的工作。

在竞相开发最先进的人工智能模型的同时,OpenAI 及其竞争对手也在激烈竞争,从世界各地招聘有限的顶尖研究人员,通常为他们提供接近七位数或更高的年薪。对于最抢手的人才来说,在不同公司之间跳槽并不罕见。
例如,Tim Brooks 曾是 OpenAI 的 Sora 负责人,最近他离职前往 DeepMind 工作。不过,高调挖角的热潮远不止 DeepMind 和 OpenAI。今年 3 月,微软从 Inflection AI 公司挖走了其人工智能负责人 Mustafa Suleyman 以及该公司的大部分员工。而谷歌斥资 27 亿美元将 Character.AI 创始人 Noam Shazeer 拉回麾下。
在过去几个月里,OpenAI 的一些关键人物相继离职,有的加入了 DeepMind 和 Anthropic 等直接竞争对手,有的创办了自己的企业。OpenAI 联合创始人、前首席科学家 Ilya Sutskever 离职后,创办了一家专注于人工智能安全和生存风险的初创公司 Safe Superintelligence。OpenAI 前首席技术官 Mira Murati 于 9 月份宣布离职,据说她正在为一家新的人工智能企业筹集资金。
今年 10 月,OpenAI 表示正在努力向全球扩张。除了新的苏黎世办事处,该公司还计划在纽约市、西雅图、布鲁塞尔、巴黎和新加坡开设新的分支机构。除旧金山总部外,该公司已在伦敦、东京和其他城市设立了分支机构。
LinkedIn 上的资料显示,Zhai、Beyer 和 Kolesnikov 都住在苏黎世,苏黎世已成为欧洲一个相对突出的科技中心。苏黎世是 ETH (苏黎世联邦理工学院)的所在地,ETH 是一所公立研究型大学,拥有全球知名的计算机科学系。据《金融时报》今年早些时候报道,苹果公司还从谷歌挖走了一些人工智能专家,在「苏黎世的一个秘密欧洲实验室」工作。
 也有人猜测,OpenAI 之所以在苏黎世设立办事处,是因为三个人都不愿意搬家。
也有人猜测,OpenAI 之所以在苏黎世设立办事处,是因为三个人都不愿意搬家。紧密合作的三位科学家
从已发表的研究看,这三位研究者经常从事同一个项目的研究,并且他们也做出了一些非常重要的研究成果,其中一些被 AI 顶会作为 Spotlight 和 Oral 论文接收。
Xiaohua Zhai(翟晓华)

个人主页:https://sites.google.com/view/xzhai
Google DeepMind(苏黎世)的资深研究科学家和管理者。他领导着苏黎世的一个多模态研究团队,其研究重心是多模态数据、开放权重模型和包容性。
根据其领英简历,他于 2014 年在北京大学取得了计算机科学博士学位。之后曾在谷歌从事了三年软件工程师的工作。2017 年 12 月,他加入 DeepMind 担任研究科学家,并一直在此工作了 7 年。
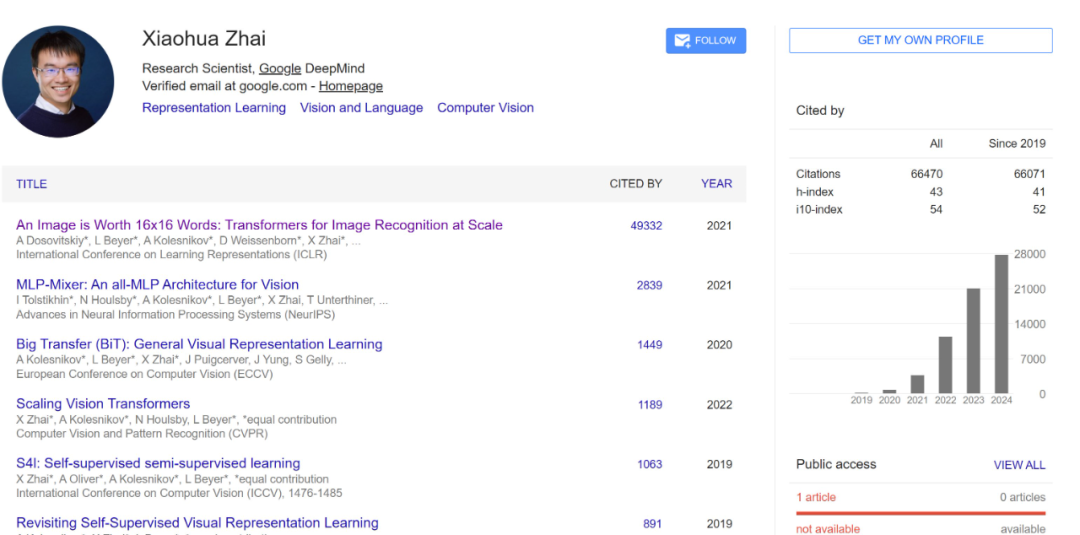
目前,翟晓华在 Google Scholar 上的被引量已经达到了 6 万多,其中大部分被引量来自他们三人共同参与的 ViT 论文《An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale》。
Lucas Beyer

Lucas Beyer 是 DeepMind 研究科学家。
个人博客:https://lucasb.eyer.be/
他在 2018 年于德国亚琛工业大学完成了自己的高等学业,期间曾在谷歌以实习生身份从事过研究工作,也在 Kindred.ai 担任过 AI 工程师,在德国亚琛工业大学担任过研究助理。
毕业后,他正式加入谷歌,先后在谷歌大脑与 DeepMind 从事研究工作。
他在博客中写到:「我是一名自学成才的黑客和科学家,致力于创造非凡事物。目前在瑞士苏黎世生活、工作、恋爱和玩耍。」

Alexander Kolesnikov

Alexander Kolesnikov 已经更新了自己的领英页面,他曾经也是 DeepMind 的研究科学家。
个人主页:https://kolesnikov.ch
他于 2012 年硕士毕业于莫斯科国立大学,之后在奥地利科学技术研究所取得了机器学习与计算机视觉博士学位。类似地,2018 年博士毕业后,他也先后在谷歌大脑和 DeepMind 从事研究工作。

出色的研究成果
很显然,这三位研究者是一个非常紧密的研究团队,也因此,他们的很多研究成果都是三人共同智慧的结晶(当然还有其他合作者),我们下面将其放在一起介绍。
首先必须提到的就是这篇论文:

论文标题:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
论文地址:https://arxiv.org/pdf/2010.11929
项目地址:https://github.com/google-research/vision_transformer
这篇就是大名鼎鼎的 Vision Transformer(ViT)论文,其中提出可以使用 Transformer 来大规模地生成图像,机器之心也曾做过报道,参阅《NLP/CV 模型跨界进行到底,视觉 Transformer 要赶超 CNN?》。目前,这篇论文的引用量已经接近 5 万,这三位研究者均是共同技术一作。

此后,他们还研究了 ViT 的 Scaling Law。

论文标题:Scaling Vision Transformers
论文地址:https://arxiv.org/pdf/2106.04560
通过扩大和缩小 ViT 模型和数据的规模,他们研究了错误率、数据和计算之间的关系。在此过程中,他们还对 ViT 的架构和训练进行了改进,减少了内存消耗并提高了生成模型的准确性。

另外,他们也为 ViT 开发了一些改进版本,对其性能或效率等不同方面进行了优化,比如能适应不同图块大小的 FlexiViT,参阅论文《FlexiViT: One Model for All Patch Sizes》。
他们也探索了另一些架构创新,比如他们在论文《MLP-Mixer: An all-MLP Architecture for Vision》中提出了一种用于视觉任务的纯 MLP 架构 MLP-Mixer;在论文《Big Transfer (BiT): General Visual Representation Learning》中,他们重新审视了在大型监督数据集上进行预训练并在目标任务上微调模型的范式,并通过扩大了预训练的规模提出了所谓的 Big Transfer 方案。
他们也开发了一些在当时都达到了 SOTA 的开发模型,比如 PaliGemma,这是一个基于 SigLIP-So400m 视觉编码器和 Gemma-2B 语言模型的开放式视觉语言模型 (VLM),其在同等规模下的表现非常出色。而在论文《Sigmoid Loss for Language Image Pre-Training》中,他们仅使用 4 块 TPUv4 芯片,在 2 天时间内就训练出了一个在 ImageNet 上实现了 84.5% 的零样本准确度的模型。

他们在计算机视觉方面的很多研究成果都统一在了 Google 的 Big Vision 项目中,参阅 https://github.com/google-research/big_vision
他们近期的研究重心是统一、简化和扩展多模态深度学习,比如:
UViM: A Unified Modeling Approach for Vision with Learned Guiding Codes,该论文提出了一种建模多样化计算机视觉任务的统一方法。该方法通过组合使用一个基础模型和一个语言模型实现了互相增益,从而在全景分割、深度预测和图像着色上取得了不错的效果。
Tuning computer vision models with task rewards,这项研究展示了强化学习在多种计算机视觉任务上的有效性,为多模态模型的对齐研究做出了贡献。
JetFormer: An Autoregressive Generative Model of Raw Images and Text,这是上个月底才刚刚发布的新研究成果,其中提出了一种创新的端到端多模态生成模型,通过结合归一化流和自回归 Transformer,以及新的噪声课程学习方法,实现了无需预训练组件的高质量图像和文本联合生成,并取得了可与现有方法竞争的性能。
当然,这三位研究者多年的研究成果远不只这些,更多成果请访问他们各自的主页。
看来,OpenAI 这次是真挖到宝了,难怪有人说谷歌失去这三位人才会是一个战略失误。




“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











