




AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本篇综述的作者团队包括宾州州立大学的博士研究生王发利,张智维,吴纵宇,张先仁,指导教师王苏杭副教授,以及来自伦斯勒理工学院的马耀副教授,亚马逊汤先锋、何奇,德克萨斯大学休斯顿健康科学中心黄明副教授团队。
摘要:大型语言模型(LLMs)在多种任务中表现出色,但由于庞大的参数和高计算需求,面临时间和计算成本挑战。因此,小型语言模型(SLMs)因低延迟、成本效益及易于定制等优势优点,适合资源有限环境和领域知识获取,正变得越来越受欢迎。我们给出了小语言模型的定义来填补目前定义上的空白。我们对小型语言模型的增强方法、已存在的小模型、应用、与 LLMs 的协作、以及可信赖性方面进行了详细调查。我们还探讨了未来的研究方向,并在 GitHub 上发布了相关模型及文章:https://github.com/FairyFali/SLMs-Survey。

论文链接:https://arxiv.org/abs/2411.03350
文章结构

LLMs 的挑战
神经语言模型(LM)从 BERT 的预训练微调到 T5 的预训练提示,再到 GPT-3 的上下文学习,极大增强了 NLP。模型如 ChatGPT、Llama 等在扩展至大数据集和模型时显示出 “涌现能力”。这些进步推动了 NLP 在多个领域的应用,如编程、推荐系统和医学问答。
尽管大型语言模型(LLMs)在复杂任务中表现出色,但其庞大的参数和计算需求限制了部署本地或者限制在云端调用。这带来了一系列挑战:
LLMs 的高 GPU 内存占用和计算成本通常使得其只能通过云 API 部署,用户需上传数据查询,可能引起数据泄漏及隐私问题,特别是在医疗、金融和电商等敏感领域。
在移动设备上调用云端 LLMs 时面临云延迟问题,而直接部署又面临高参数和缓存需求超出普通设备能力的问题。
LLMs 庞大的参数数量可能导致几秒至几分钟的推理延迟,不适合实时应用。
LLMs 在专业领域如医疗和法律的表现不佳,需要成本高的微调来提升性能。
虽然通用 LLMs 功能强大,但许多应用和任务只需特定功能和知识,部署 LLMs 可能浪费资源且性能不如专门模型。
SLMs 的优势
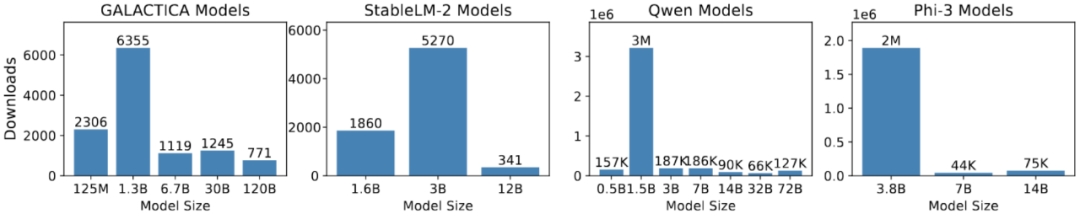
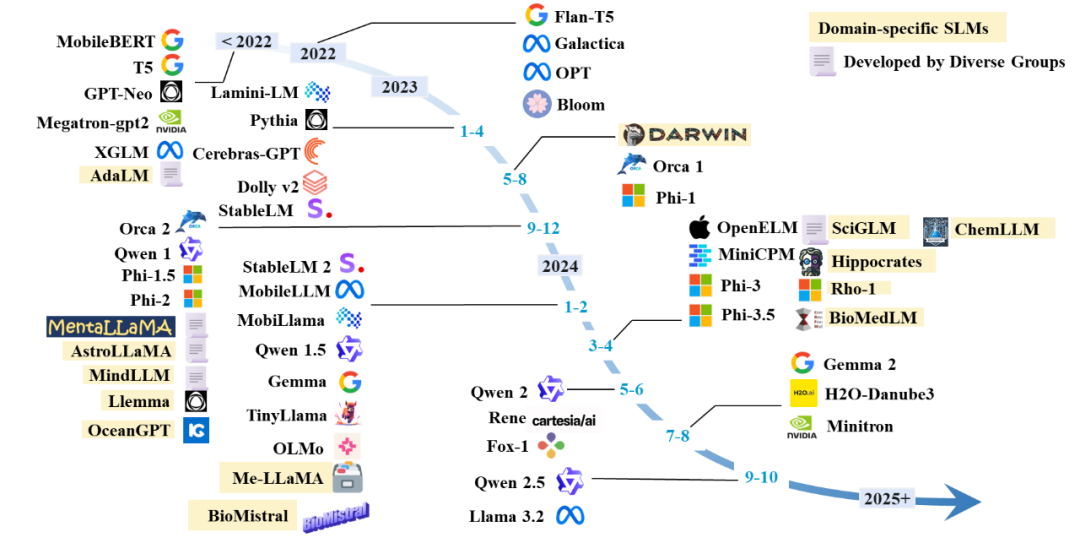
最近,小型语言模型(SLMs)在处理特定领域问题时显示出与大型语言模型(LLMs)相当的性能,同时在效率、成本、灵活性和定制方面具有优势。由于参数较少,SLMs 在预训练和推理过程中节约了大量计算资源,减少了内存和存储需求,特别适合资源有限的环境和低功耗设备。因此,SLMs 作为 LLMs 的替代品越来越受到关注。如图 2 所示,Hugging Face 社区中 SLMs 的下载频率已超过大型模型,而图 3 显示了 SLMs 版本随时间推移的日益流行。
SLMs 的定义
通常,具有涌现能力的语言模型被归类为大型语言模型(LLMs)。然而,小型语言模型(SLMs)的分类尚无统一标准。一些研究认为 SLMs 的参数少于 10 亿,且在移动设备上通常配备约 6GB 的内存;而另一些研究则认为 SLMs 的参数可达到 100 亿,但这些模型通常缺乏涌现能力。考虑到 SLMs 在资源受限的环境及特定任务中的应用,我们提出了一个广义的定义:SLMs 的参数范围应介于能展现专门任务涌现能力的最小规模和在资源限制条件下可管理的最大规模之间。这一定义旨在整合不同观点,并考虑移动计算及能力阈值因素。
SLMs 的增强方法
在大语言模型时代小语言模型的增强方法会有不同,包括从头开始训练 SLMs 的训练方法、使 SLMs 遵循指令的监督微调 (SFT)、先进的知识提炼和量化技术,以及 LLMs 中经常使用的技术,以增强 SLMs 针对特定应用的性能。我们详细介绍了其中一些代表性方法,包括参数共享的模型架构(从头开始训练子章节 3.1)、从人类反馈中优化偏好(有监督微调子章节 3.2)、知识蒸馏的数据质量(3.3 章节)、蒸馏过程中的分布一致性(3.4 章节)、训练后量化和量化感知训练技术(3.5 章节)、RAG 和 MoE 方法增强 SLMs(3.6 章节)。这一章节的未来方法是探索可提高性能同时降低计算需求的模型架构,比如 Mamba。
SLMs 的应用
由于 SLMs 能够满足增强隐私性和较低的内存需求,许多 NLP 任务已开始采用 SLMs,并通过专门技术提升其在特定任务上的性能(见 4.1 节),如问答、代码执行、推荐系统以及移动设备上的自动化任务。典型应用包括在移动设备上自动执行任务,SLMs 可以作为代理智能调用必需的 API,或者根据智能手机 UI 页面代码自动完成给定的操作指令(见 4.1.5 节)。
此外,部署 SLMs 时通常需考虑内存使用和运行效率,这对预算有限的边缘设备(特别是智能手机)上的资源尤为关键(见 4.2 节)。内存效率主要体现在 SLMs 及其缓存的空间占用上,我们调研了如何压缩 SLMs 本身及其缓存(见 4.2.1 节)。运行效率涉及 SLMs 参数量大及切换开销,如内存缓存区与 GPU 内存之间的切换(见 4.2.2 节),因此我们探讨了减少 MoE 切换时间和降低分布式 SLMs 延迟等策略。
未来研究方向包括使用 LoRA 为不同用户提供个性化服务、识别 SLMs 中的固有知识及确定有效微调所需的最少数据等(更多未来方向详见第 8 章)。
已存在的 SLMs
我们总结了一些代表性的小型语言模型(详见图 3),这些模型包括适用于通用领域和特定领域的小型语言模型(参数少于 70 亿)。本文详细介绍了这些小型语言模型的获取方法、使用的数据集和评估任务,并探讨了通过压缩、微调或从头开始训练等技术获取 SLMs 的策略。通过统计分析一些技术,我们归纳出获取通用 SLMs 的常用技术,包括 GQA、Gated FFN,SiLU 激活函数、RMS 正则化、深且窄的模型架构和 embedding 的优化等(见 5.1 章)。特定领域的 SLMs,如科学、医疗健康和法律领域的模型,通常是通过对大模型生成的有监督领域数据进行指令式微调或在领域数据上继续训练来获取的(见 5.2 章)。未来的研究方向将包括在法律、金融、教育、电信和交通等关键领域开发专业化的小型语言模型。
SLMs 辅助 LLMs
由于 SLMs 在运行效率上表现出色且与 LLMs 的行为规律相似,SLMs 能够作为代理辅助 LLMs 快速获取一些先验知识,进而增强 LLMs 的功能,例如减少推理过程中的延迟、缩短微调时间、改善检索中的噪声过滤问题、提升次优零样本性能、降低版权侵权风险和优化评估难度。
在第 6 章中,我们探讨了以下五个方面:
(i) 使用 SLMs 帮助 LLMs 生成可靠内容:例如,使用 SLMs 判断 LLMs 输入和输出的真实置信度,或根据 LLMs 的中间状态探索幻觉分数。详细的可靠生成方法、增强 LLMs 的推理能力、改进 LLMs RAG 以及缓解 LLMs 输出的版权和隐私问题,请参考原文。
(ii) SLMs 辅助提取 LLMs 提示:一些攻击方法通过 SLMs 逆向生成 Prompts。
(iii) SLMs 辅助 LLMs 微调:SLMs 的微调参数差异可以模拟 LLMs 参数的演变,从而实现 LLMs 的高效微调。
(iv) SLMs 在特定任务上辅助 LLMs 表现:定制化的 SLMs 在某些特定任务上可能优于 LLMs,而在困难样本上可能表现不佳,因此 SLMs 和 LLMs 的合作可以在特定任务上实现更优表现。
(v) 使用 SLMs 评估 LLMs:SLMs 在经过微调后可以作为评估器,评估 LLMs 生成的更加格式自由的内容。
未来的方向包括使用 SLMs 作为代理探索 LLMs 更多的行为模式,如优化 Prompts、判断缺失知识和评估数据质量等,更多信息请参见原文第 8 章未来工作。
SLMs 的可信赖性
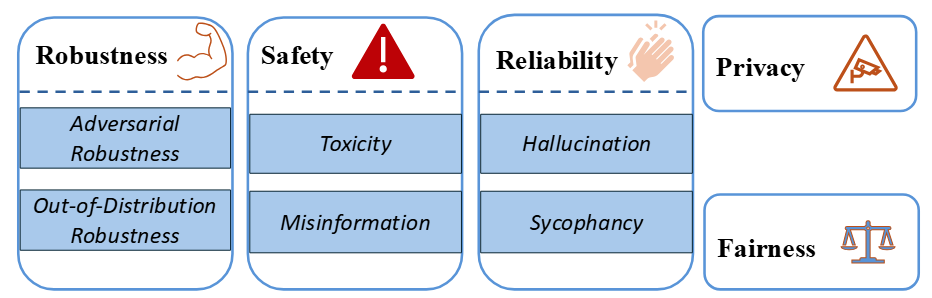
语言模型已成为我们日常生活中不可或缺的一部分,我们对它们的依赖日益增加。然而,它们在隐私、公平等信任维度上存在局限,带来了一定风险。因此,许多研究致力于评估语言模型的可信赖性。尽管目前的研究主要集中在大型语言模型(LLMs)上,我们在第 7 章关注 7B 参数及以下的模型和五个关键的信任场景:鲁棒性、隐私性、可靠性、安全性和公平性,详见图 4。在鲁棒性方面,我们讨论了对抗性鲁棒性和分布外鲁棒性两种情况;在安全性方面,我们重点分析了误导信息和毒性问题;在可靠性方面,我们主要关注幻觉和谄媚现象。然而,大多数现有研究都集中在具有至少 7B 参数的模型上,这留下了对小型语言模型(SLMs)可信度全面分析的空白。因此,系统地评估 SLMs 的可信度并了解其在各种应用中的表现,是未来研究的重要方向。
总结
随着对小型语言模型需求的增长,当下研究文献涵盖了 SLMs 的多个方面,例如针对特定应用优化的训练技术如量化感知训练和选择性架构组件。尽管 SLMs 性能受到认可,但其潜在的可信度问题,如幻觉产生和隐私泄露风险,仍需注意。当前缺乏全面调查彻底探索 LLMs 时代 SLMs 的这些工作。本文旨在提供详尽调查,分析 LLMs 时代 SLMs 的各个方面及未来发展。详见我们的综述原文。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











