




AIxiv专栏是机器之心发布学术、技术内容的栏目。过去数年,机器之心AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com
本论文作者杨睿是中国科学技术大学 2019 级硕博连读生,师从王杰教授、李斌教授,主要研究方向为强化学习、自动驾驶等。他曾以第一作者在 NeurIPS、KDD 等顶级期刊与会议上发表论文两篇,曾获滴滴精英实习生(16/1000+)。
近日,中科大王杰教授团队 (MIRA Lab) 针对离线强化学习数据集存在多类数据损坏这一复杂的实际问题,提出了一种鲁棒的变分贝叶斯推断方法,有效地提升了智能决策模型的鲁棒性,为机器人控制、自动驾驶等领域的鲁棒学习奠定了重要基础。论文发表在 CCF-A 类人工智能顶级会议 Neural Information Processing Systems(NeurIPS 2024)。

论文地址:https://arxiv.org/abs/2411.00465
代码地址:https://github.com/MIRALab-USTC/RL-TRACER
引言
在机器人控制领域,离线强化学习正逐渐成为提升智能体决策和控制能力的关键技术。然而,在实际应用中,离线数据集常常由于传感器故障、恶意攻击等原因而遭受不同程度的损坏。这些损坏可能表现为随机噪声、对抗攻击或其他形式的数据扰动,影响数据集中的状态、动作、奖励和转移动态等关键元素。经典离线强化学习算法往往假设数据集是干净、完好无损的,因此在面对数据损坏时,机器学习到的策略通常趋向于损坏数据中的策略,进而导致机器在干净环境下的部署时性能显著下降。
尽管研究者在鲁棒离线强化学习领域已经取得了一些进展,如一些方法尝试通过增强测试期间的鲁棒性来缓解噪声或对抗攻击的影响,但它们大多在干净数据集上训练智能体模型,以防御测试环境中可能出现的噪声和攻击,缺乏对训练用离线数据集存在损坏的应对方案。而针对离线数据损坏的鲁棒强化学习方法则只关注某一特定类别的数据存在损坏,如状态数据、或转移动态数据存在部分损坏,他们无法有效应对数据集中多个元素同时受损的复杂情况。
为了针对性地解决这些现有算法的局限性,我们提出了一种鲁棒的变分贝叶斯推断方法(TRACER),有效地增强了离线强化学习算法在面临各类数据损坏时的鲁棒性。TRACER 的优势如下所示:
1. 据我们所知,TRACER 首次将贝叶斯推断引入到抗损坏的离线强化学习中。通过将所有离线数据作为观测值,TRACER 捕捉了由各类损坏数据所导致的动作价值函数中的不确定性。
2. 通过引入基于熵的不确定性度量,TRACER 能够区分损坏数据和干净数据,从而调控并减弱损坏数据对智能体模型训练的影响,以增强鲁棒性。
3. 我们在机器人控制(MuJoCo)和自动驾驶(CARLA)仿真环境中进行了系统性地测试,验证了 TRACER 在各类离线数据损坏、单类离线数据损坏的场景中均显著提升了智能体的鲁棒性,超出了多个现有的 SOTA 方法。
1. 方法介绍
1.1 动机
考虑到(1)多种类型的损毁会向数据集的所有元素引入较高的不确定性,(2)每个元素与累积奖励(即动作值、Q 值)之间存在明确的相关性关系(见图 1 中的虚线),因此使用多种受损数据估计累积奖励函数(即动作值函数)会引入很高的不确定性。
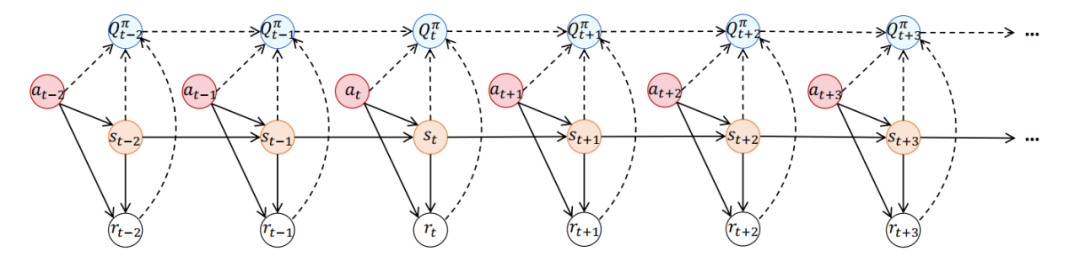
为了处理这类由多种数据损毁(即状态、动作、奖励、状态转移数据受损)导致的高不确定性问题,基于图 2 所示的概率图模型,我们提出利用数据集中的所有元素作为观测数据。我们旨在利用这些观测数据与累积奖励之间的高度相关性,来准确地识别动作值函数的不确定性。
1.2 基于受损数据的贝叶斯推断
我们提出使用离线数据集的所有元素作为观测值,利用数据之间的相关性同时解决不确定性问题。具体地,基于离线数据集中动作价值与四个元素(即状态、动作、奖励、下一状态)之间的关系,我们分别使用各个元素作为观测数据,通过引入变分贝叶斯推理框架,我们最大化动作值函数的后验分布,从而推导出各个元素对应的基于最大化证据下界 (ELBO) 的损失函数。基于对动作价值函数的后验分布的拟合,我们能有效地将数据损坏建模为动作值函数中的不确定性。
1.3 基于熵的不确定性度量
为了进一步应对各类数据损坏带来的挑战,我们思考如何利用不确定性进一步增强鲁棒性。鉴于我们的目标是提高在干净环境中的智能体性能,我们提出减少损坏数据的影响,重点是使用干净数据来训练智能体。因此,我们提供了一个两步计划:(1)区分损坏数据和干净数据;(2)调控与损坏数据相关的损失,减少其影响,从而提升在干净环境中的表现。
对于(1),由于损坏数据通常会造成比干净数据更高的不确定性和动作价值分布熵,因此我们提出通过估计动作值分布的熵,来量化损坏数据和干净数据引入的不确定性。
对于 (2),我们使用分布熵指数的倒数来加权我们提出的 ELBO 损失函数。因此,在学习过程中,TRACER 能够通过调控与损坏数据相关的损失来减弱其影响,并同时专注于最小化与干净数据相关的损失,以增强在干净环境中的鲁棒性和性能。
1.4 算法架构
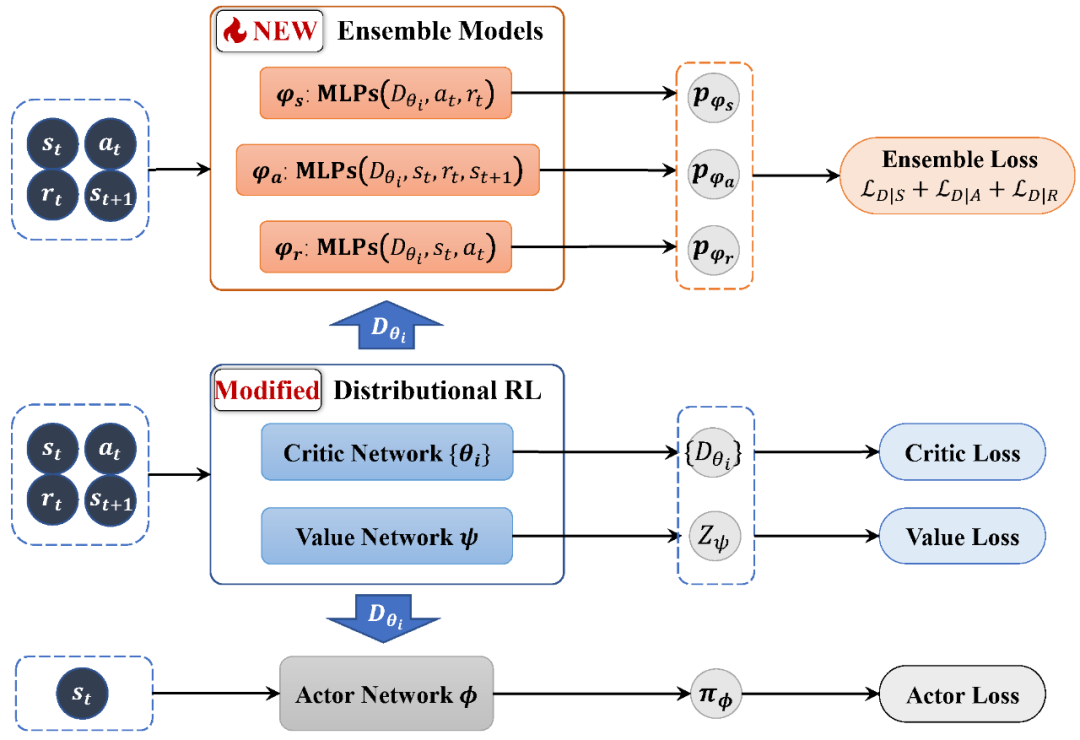 图 2. TRACER 算法框架图。
图 2. TRACER 算法框架图。2. 实验介绍
为了模拟数据受损的情形,我们对数据集的部分数据加入随机噪声或对抗攻击来构建损坏数据。在我们的实验中,我们对 30% 的单类数据进行损坏。因此,在所有类型的数据都有损坏时,整个离线数据集中,损坏数据占约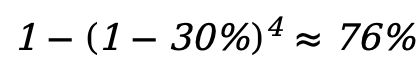
各类数据均受损
所有类型数据元素均存在损坏的部分实验结果见表 1,TRACER 在所有控制环境中均获得了较为明显的性能提升,提升幅度达 + 21.1%,这一结果展现了 TRACER 对大规模、各类数据损坏的强鲁棒性。

表 1. 离线数据集的所有类型元素均存在随机损坏(random)或对抗损坏(advers)时,我们的方法 TRACER 在所有环境中都获得了最高的平均得分。
单类数据受损
单种类型数据元素存在损坏的部分实验结果见表 2 和表 3。在单类数据损坏中,TRACER 于 24 个实验设置里实现 16 组最优性能,可见 TRACER 面向小规模、单类数据损坏的问题也能有效地增强鲁棒性。

表 2. 单类元素存在随机损坏时,我们的方法 TRACER 在 8 个实验设置中获得了最高的平均得分。
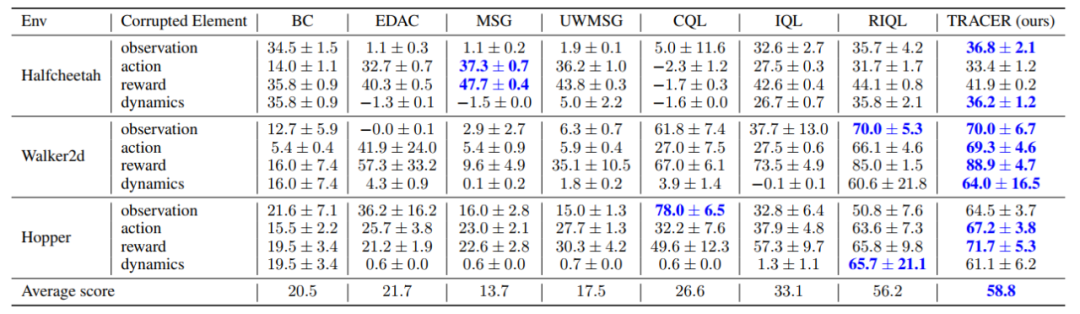
表 3. 单类元素存在对抗损坏时,我们的方法 TRACER 在 8 个实验设置中获得了最高的平均得分。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











