




论文第一作者林宏彬来自香港中文大学 (深圳) Deep Bit 实验室,导师为李镇老师。实验室专注于利用人工智能技术进行跨学科研究,例如自动驾驶的三维感知、医学成像和分子理解的多模态数据分析和生成等。研究领域涵盖计算机视觉、机器 / 深度学习和 AI4Science。感兴趣的同学可以在主页上获取更多信息https://mypage.cuhk.edu.cn/academics/lizhen/
全自动驾驶系统的纯视觉方案如特斯拉 “Tesla Vision”,仅依赖于摄像头收集的图像数据,旨在实现高效且成本效益高的自动驾驶技术。在现实场景中,视觉感知模型在面对训练数据分布外场景的泛化能力尤为关键。来自香港中文大学(深圳)、新加坡国立大学、昆仑万维和南洋理工大学的学者们提出了一种名为 MonoTTA 的单目三维检测模型的实时测试时自适应方法。该方法使模能在测试阶段实时进行快速的无监督学习,显著提升了其在未知测试分布上的表现。
MonoTTA 通过自适应挖掘高置信度物体,同时利用负标签以缓解伪标签的噪音,有效减少了模型的漏检和误检,从而帮助单目三维检测模型的实时泛化。目前代码已开源,欢迎感兴趣的小伙伴到 GitHub 查看更多展示视频。

论文链接:https://arxiv.org/pdf/2405.19682
GitHub:https://github.com/Hongbin98/MonoTTA
纯视觉方案在自动驾驶的落地应用还有多远?
近年来,纯视觉自动驾驶系统在全球汽车行业中引起了广泛关注,标志着自动驾驶技术向更高智能化的迈进。不禁让人思考,在自动驾驶领域真正实现纯视觉方案还有多远呢?
在自动驾驶领域,纯视觉方案的泛化能力至关重要。然而,传统的机器学习技术通常依赖大量预先收集的数据来训练模型。实际应用中,测试数据的分布往往与训练数据不同,这种现象称为 “分布偏移”。分布偏移在实际测试中往往可能表现为:1)自然天气的变化导致道路上的物体被遮挡(如雾、雪),或光线条件显著变化;2)由于驾驶过程中的摄像头抖动,出现画面模糊;3)模型训练数据来自某个四季如春的城市,但在高纬度的城市进行测试。这些常见但棘手的分布偏移问题对深度学习模型的影响很大,往往导致模型性能显著下降,严重制约了其在室外场景的广泛部署。
纯视觉方案在遭遇分布偏移时具体会有什么问题呢?以单目三维检测模型为例,如图 2 所示,当一个经过良好训练的模型直接应用于受自然气候干扰(如雪和雾)影响的非训练分布测试场景时,相比在训练数据相同分布(即晴天)的场景,分布外测试数据中的物体检测分数会显著下降。正如我们在恶劣天气下行车,视野范围内的车辆、行人也会变得模糊不清,很难判断清楚远方到底是不是有其他车辆。然而当前的单目三维检测方法通常使用固定的分数阈值(如 0.2)来进行物体检测,物体检测分数的大幅下降导致单目三维检测模型出现大量漏检、错检,从而使得模型的性能大幅下降。
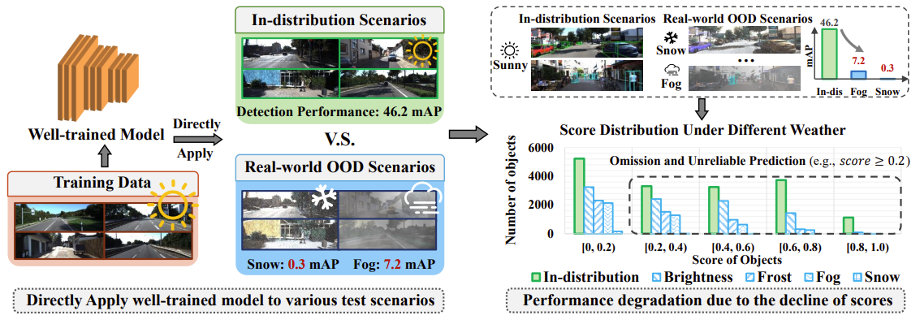
那么该如何解决分布偏移呢?为了应对数据分布的潜在偏移和算法在实际应用场景中对可扩展性和时效性的需求,一种可行的范式是测试时自适应(Test-Time Adaptation, TTA)。该范式要求算法在测试阶段指导模型进行快速无监督 / 自监督学习,是当前用于提升深度模型分布外泛化能力的一种强有效工具。而其中一种更快速、更实时的子范式即实时测试时自适应(Fully Test-Time Adaptation, Fully TTA),其旨在通过在线方式利用连续的测试数据流实时调整和优化模型,缓解数据分布偏移带来的问题从而显著提高模型的性能。该范式能够满足现实场景下的算法部署与实时优化需求,因此吸引了学术界和工业界越来越多的关注。
现存 Fully TTA 方法却往往难以应对分布差异很大的检测任务。例如在极端的天气条件下,如图 2 中的雪天,单目三维检测模型往往无法生成足够的高分检测结果。通俗地说,模型在极端天气下会出现绝大部分物体对象都看不到了的问题。然而,现有的 Fully TTA 方法却是依赖于模型先检测出物体对象,再进行模型的实时适应。因此,这些方法在具有极大差异的分布外场景下难以对模型进行实时调整,换而言之,缺乏挖掘未被正确识别的物体(即漏检)的能力。
技术方案
基于前面的讨论,我们不禁思考:要怎么去设计一个 TTA 方法,去实现这种挖掘未被正确识别的物体(即漏检)的能力呢?来自香港中文大学(深圳)、新加坡国立大学、昆仑万维和南洋理工大学的学者们给出了他们的看法。学者们提出了一个针对单目三维检测模型的实时测试时自适应方法(Monocular Test-Time Adaptation,MonoTTA),其由以下两个适应策略所组成:1) 基于可靠物体对象的模型自适应;2) 基于负标签优化的伪标签噪音缓解。具体细节阐述如下:
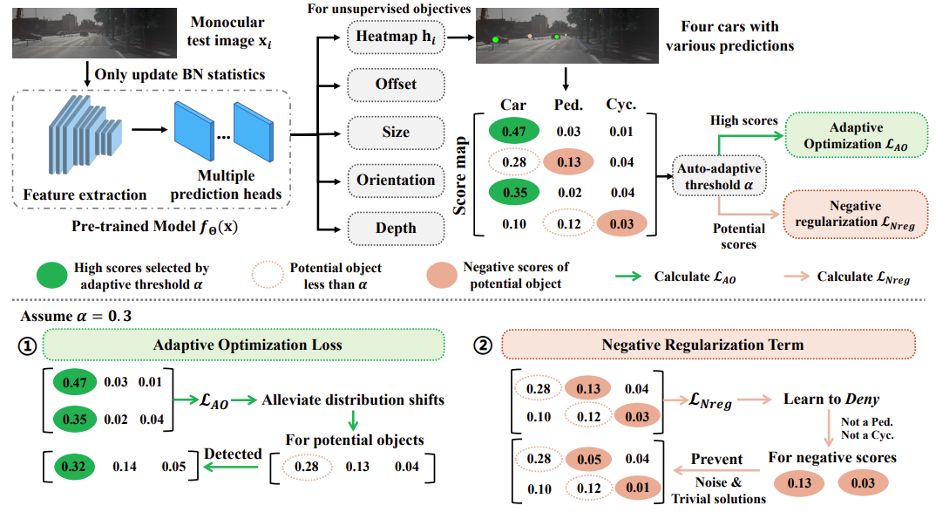
基于可靠物体对象的模型自适应:具体而言,测试数据分布的变化会导致物体对象的检测分数骤降,从而引起漏检和错检。而学者们通过分析发现,即便在域外场景下,高检测分数的物体对象仍然是相对可靠的(如下图 4(a)所示)。此外,即使仅通过高分物体对象(例如,score≥0.5)来优化模型,低分和高分对象的数量都会增加(即图 4(b))。这些观察启发我们要利用高分物体对象而不是所有物体对象进行模型适应,这将是一种更可靠的方式来缓解数据分布变化并发掘潜在物体对象。
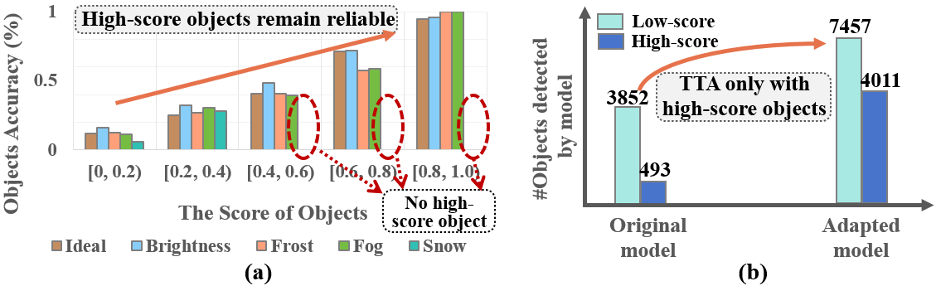
基于上述观察可以发现:域外场景下高分对象不仅是相对可靠的,还可以通过高分对象的这种相对可靠的模型优化,发掘出更多的低分潜在物体对象!这启发学者们设计了适应性优化损失
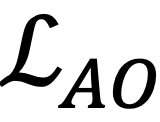
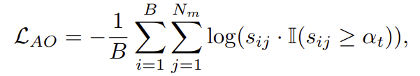
这里的 是在迭代伦次t下的自适应阈值,这是考虑到实际测试场景的分布差异是未知的,因此开发了一种自适应策略,用于在测试图像中自动识别可靠的高分对象。
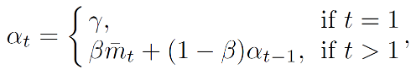
其中,为所有检测到的物体对象的平均分数,β 是衰减系数,而 γ 则是遵循原方法的预定义物体检测阈值。B 为批量大小,
则对应每个检测物体的具体分数值。
为单张图片下的最大检测物体对象数目,
基于负标签优化的伪标签噪音缓解:虽然通过
的优化,模型能有效缓解漏检问题。但像我们先前讨论的,一种极端情况是数据分布差异还会导致高分对象的极度稀缺,如上图 4(a)中的雪天场景,此时大多数对象呈现低分,无法利用高分样本以优化模型。为此,学者们开发了一个负标签正则化项,以合理利用众多低分物体对象以进行负标签学习。一方面,负标签正则化项
具体地,对那些低于自适应阈值 的物体对象,基于每个类别的具体频率
,求和得到最终损失值:
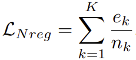
而每个类别下的正则约束项有:
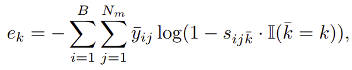
其中,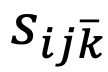
则是具体检测物体对象对于负类别 k 下的检测分数。
是常数权重,
通俗来说,极端情况下模型往往难以直接辨别出物体是什么,但相较之下模型有更大的把握知道物体对象不属于某个具体类别。特别是极端场景下,会在模型适应中扮演了更重要的角色。因为它可以通过只利用低分数的对象(即否定负面类别)来缓解分布偏移,换句话说,使得模型在极端场景下仍然能够减轻分布偏移并获得更多相对高分的对象,从而为
的计算奠定了关键基础。
实验
方法有效性:MonoTTA 能为现存单目三维检测方法带来可观的性能提升:实验结果展示了探索的新方法可以在域外分布测试场景中为单目三维检测模型带来显著的改进,例如,在所制作的 KITTI-C 数据集上的 13 种类型(囊括了噪音、模糊、天气变化以及设备退化影响)的分布外偏移中,平均性能提升了 137% 和 244%。
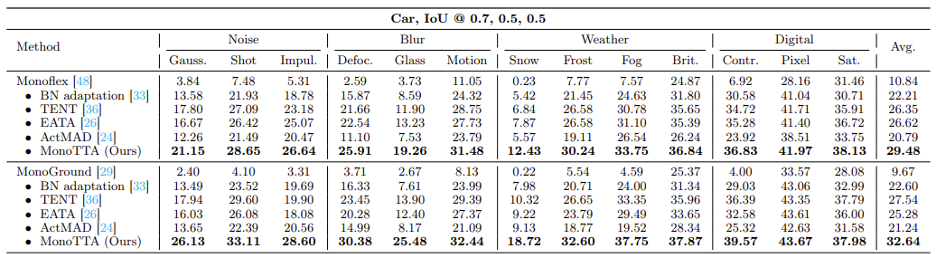
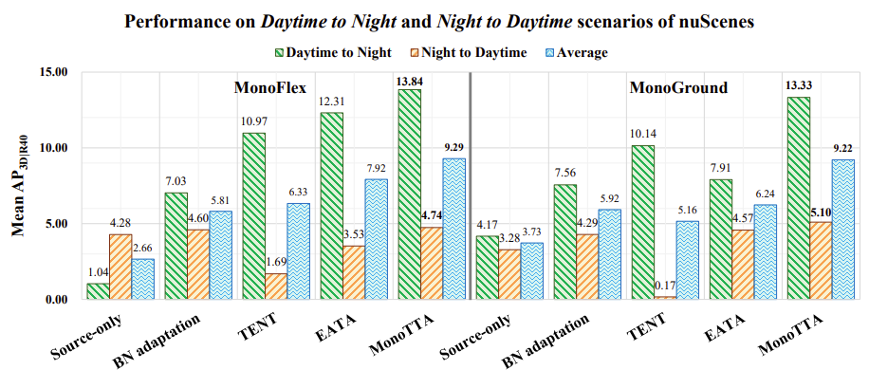
此外,学者们还进一步在 nuScenes 数据集的白天到黑夜(Daytime → Night)和黑夜到白天(Night → Daytime)两个在真实数据场景下做进一步实验,验证了所提出方法的有效性:
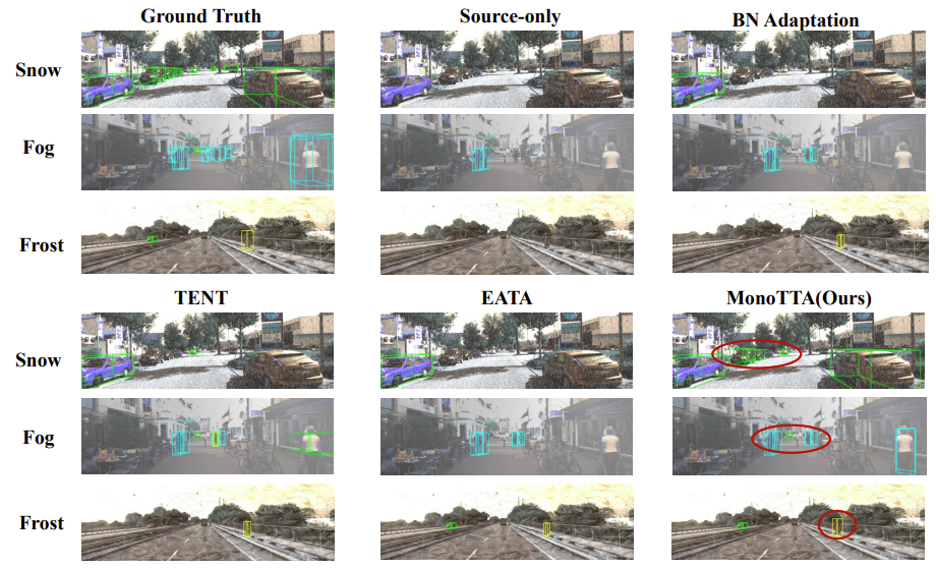
结果可视化:进一步提供了可视化结果如下图所示
并且,基于 KITTI-RAW 数据提供了相应的 demo 视频(更多示例视频见 Github 链接),其中左边为原方法,而右边则对应 MonoTTA 实时适应后的检测结果。基于单张 4090 显卡,MonoTTA 仅需约 45ms 即可适配一张 1280X384 的测试图像,即 fps >=15。相信通过量化部署优化,这个速度还能被进一步提升。

面模糊 - 等级 1)

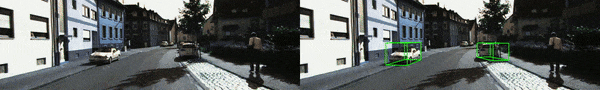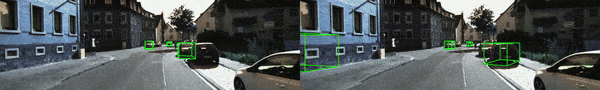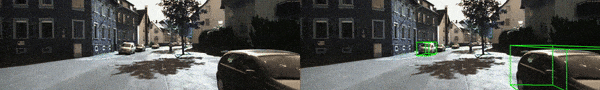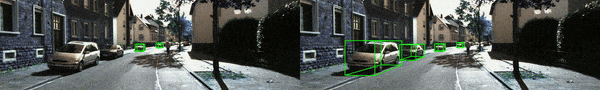
基于上述实验结果,有理由相信通过单目三维检测模型的实时适应,该论文所设计的方法能够有效地提高模型的泛化性能,从而提升单目三维检测在自动驾驶中的落地和应用。



“掌”握科技鲜闻 (微信搜索techsina或扫描左侧二维码关注)











